[embed]https://youtu.be/FsxthdQ_sL4[/embed]
L'apprentissage par renforcement (reinforcement learning ou RL) a de nombreuses applications : robot, voiture autonome, chatbot... Cependant, son adoption pour les applications du monde réel est entravée par des défis d'ingénierie majeurs. Les pods TPU de Google Cloud offrent une solution innovante pour surmonter ces obstacles.
Les premières victoires notables de l'RL ont eu lieu dans l'univers des jeux vidéo, où des systèmes basés sur l'apprentissage par renforcement ont triomphé de champions mondiaux dans des jeux tels que Go, StarCraft 2 et Dota2. Cependant, malgré ces succès, l'application généralisée du RL reste un défi.
Les TPU : des accélérateurs transformateurs pour l'IA
Les TPU (Tensor Processing Unit) introduits en 2016 par Google Cloud, émergent comme une réponse aux défis techniques de l'RL. Ces unités de traitement tensorielles sont spécialement conçues pour les applications de calcul haute performance à grande échelle, offrant une architecture optimisée pour accélérer les opérations tensorielles essentielles aux réseaux neuronaux modernes. La quatrième génération de ces TPU, annoncée en 2021, a été organisée en pods, des grappes de puces TPU interconnectées. Les pods TPU v4 peuvent ainsi combiner jusqu'à 4 096 puces, offrant une performance de pointe de 1,1 ExaFLOPS.
L'architecture Sebulba pour la mise à l'échelle du RL
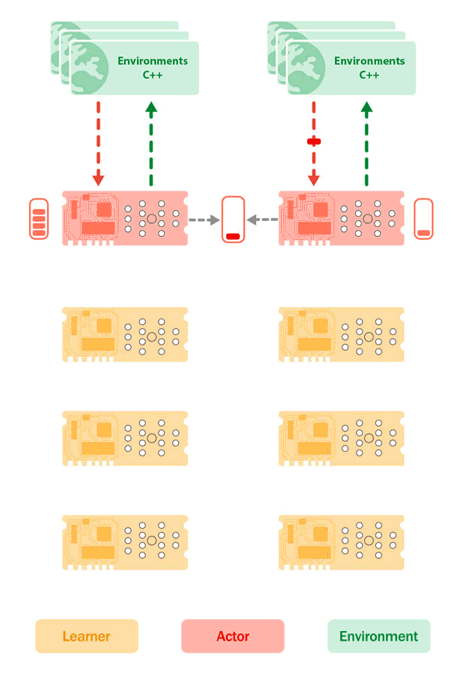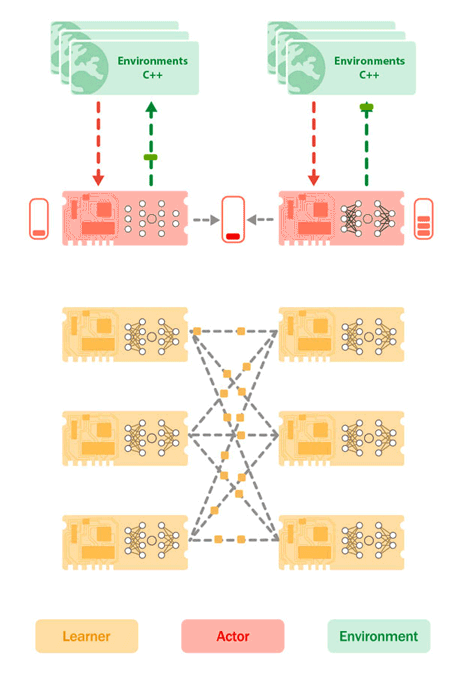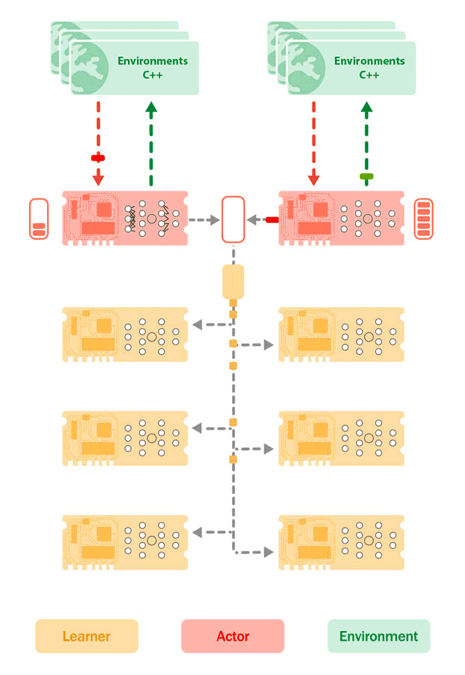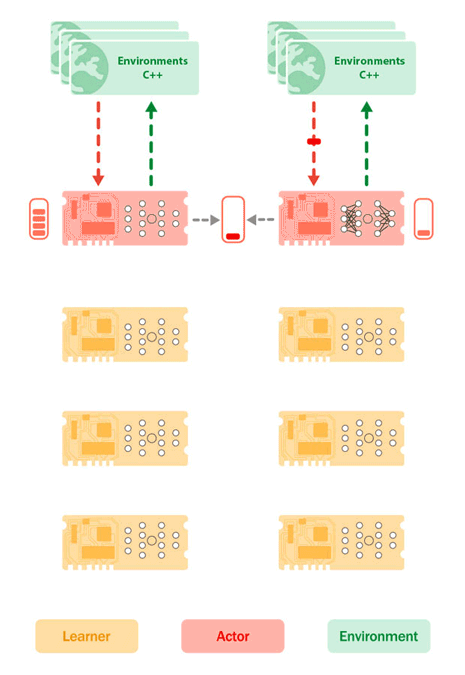
L'architecture Sebulba, introduite en 2021 dans l’article Podracer de Google DeepMind. est une réponse à la mise à l'échelle des systèmes RL. En co-localisant les acteurs et les apprenants sur les mêmes TPU, Sebulba minimise les goulots d'étranglement associés au transfert de données, tout en capitalisant sur les capacités de traitement parallèle des TPU. La figure ci-dessous illustre la configuration des cœurs d'acteur et d'apprenant sur un TPU, qui peut être répliquée sur plusieurs TPU pour augmenter le débit et la performance des agents RL.
Architecture de Sebulba illustrant le placement des cœurs d’apprentissage (jaune) et des cœurs d’acteur (rouge) sur le TPU, ainsi que les environnements sur les processeurs hôtes (vert). Les environnements envoient leurs observations et leurs récompenses aux cœurs d’acteurs qui envoient ensuite en réponse les prochaines actions à entreprendre. Ce faisant, les acteurs construisent un tampon de trajectoires. Simultanément, l’apprenant extrait des lots de trajectoires de la mémoire tampon des acteurs et effectue des mises à jour d’apprentissage, en poussant de nouveaux paramètres de modèle vers les appareils des acteurs. Crédit Google Cloud
Un cas d'utilisation concret : le routage des cartes de circuits imprimés
InstaDeep propose DeepPCB, un produit basé sur l’IA permettant aux ingénieurs électriciens d’acheminer leurs cartes de circuits imprimés de manière optimale sans intervention humaine. Dans ce cadre, son équipe produit a créé un moteur de simulation rapide pour entraîner efficacement des agents de RL. En connectant l’architecture Sebulba au simulateur DeepPCB, elle a obtenu une accélération de 15 à 235 fois par rapport à l’ancienne architecture distribuée.
Lors de la conférence Next ’23, Google Cloud a présenté la 5ème génération de ses TPU : les v5e, indiquant sur son blog :
"Cloud TPU v5 est spécialement conçu pour apporter la rentabilité et les performances requises pour l’entraînement et l’inférence à moyenne et grande échelle. TPU v5e offre des performances d’entraînement jusqu’à 2 fois supérieures par dollar et jusqu’à 2,5 fois plus performantes par dollar pour les LLM et les modèles d’IA gen par rapport à Cloud TPU v4. Avec un coût inférieur de moitié à celui de TPU v4, TPU v5e permet à un plus grand nombre d’organisations d’entraîner et de déployer des modèles d’IA plus grands et plus complexes".
Références de l'article : Blog Google Cloud, rédigé par Armand Picard, Ingénieur logiciel, InstaDeep et Donal Byrne, Ingénieur de recherche senior, InstaDeep.
MA
Marie-Claude Benoit
Rédaction ActuIA — actualités, données et analyses sur l'intelligence artificielle pour les décideurs.