
Alors que Meta prépare le lancement des premiers modèles Llama 4 pour le début de l'année prochaine, l'entreprise a dévoilé en fin de semaine dernière son dernier ajout à la famille Llama 3 : Llama 3.3 70B. Ce modèle, qui comme son nom l'indique compte 70 milliards de paramètres, est aussi performant que Llama 3 405B mais nécessite beaucoup moins de ressources.
LLama 3.3 70B a été annoncé par Meta sur X le 6 décembre dernier :
"Alors que nous continuons à explorer de nouvelles techniques de post-formation, nous lançons aujourd’hui Llama 3.3 - un nouveau modèle open source qui offre des performances et une qualité de pointe dans les cas d’utilisation basés sur du texte, tels que la génération de données synthétiques à une fraction du coût d’inférence".
Il est distribué sous la "Llama 3.3 Community License Agreement", qui permet l'utilisation, la reproduction, la distribution, la création d'œuvres dérivées et les modifications du modèle. Cependant, cette licence impose certaines conditions, comme l'obligation de fournir une copie de l'accord de licence avec toute distribution du modèle et d'afficher "Built with Llama" sur les produits dérivés. Les organisations comptant plus de 700 millions d’utilisateurs actifs mensuels devront quant à elles demander une licence commerciale.
S'il n'est pas open source au sens strict de l'OSAID, comme les modèles Llama 3.1 8B, 70B et 405 B, Llama 3.3 70B est un modèle "ouvert" exclusivement textuel. A leur instar, il est multilingue (anglais, allemand, français, italien, portugais, hindi, espagnol et thaïlandais), dispose d’une fenêtre contextuelle pouvant aller jusqu’à 128 000 tokens et de capacités de raisonnement renforcées.
Il a été pré-entraîné sur 15 000 milliards de tokens à partir de données accessibles au public avant d'être affiné sur plus de 25 millions d’exemples générés synthétiquement. Ses connaissances s'arrêtent en décembre 2023. Il utilise l'apprentissage par renforcement avec retour humain (RLHF) et le réglage fin supervisé (SFT), ce qui lui permet de générer des réponses sûres et utiles.
Llama 3.3 70B innove en utilisant la technique Grouped Query Attention (GQA) ce qui lui permet de traiter des tâches complexes de manière plus efficace tout en nécessitant moins de ressources informatiques.
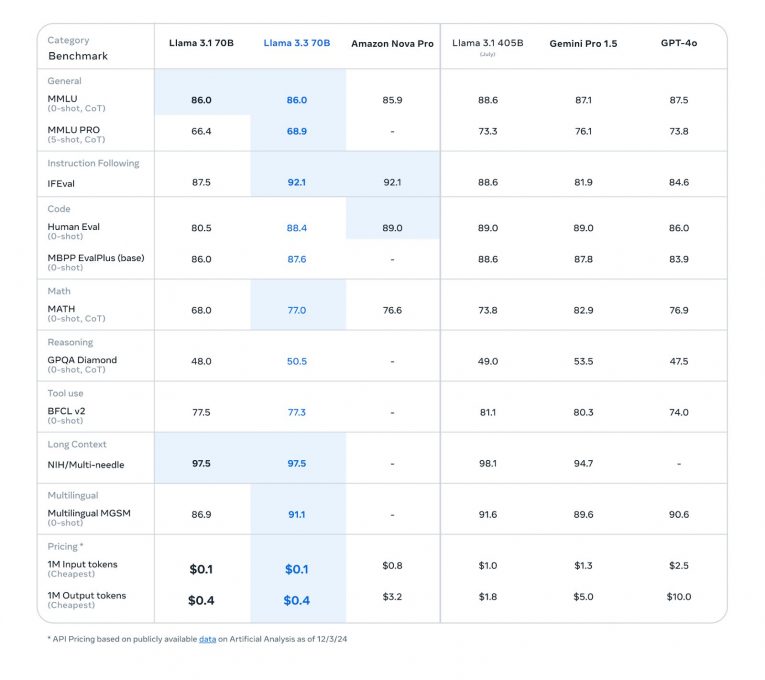 Les scores obtenus par LLama 3.3 70B montrent qu'il est particulièrement adapté pour des cas d’utilisation nécessitant un bon suivi des instructions, une prise en charge multilingue efficace et le traitement de données volumineuses ou complexes :
Les scores obtenus par LLama 3.3 70B montrent qu'il est particulièrement adapté pour des cas d’utilisation nécessitant un bon suivi des instructions, une prise en charge multilingue efficace et le traitement de données volumineuses ou complexes :
Performances du modèle
Meta a évalué les performances du modèle par rapport à celles de ses prédécesseurs Llama 3.1 70B et 405B et celles de ses concurrents Gemini 1.5 Pro de Google, GPT-4o d'OpenAI et Nova Pro d'Amazon.
Les scores obtenus par LLama 3.3 70B montrent qu'il est particulièrement adapté pour des cas d’utilisation nécessitant un bon suivi des instructions, une prise en charge multilingue efficace et le traitement de données volumineuses ou complexes :
- Pour le suivi d'instructions (Instruction Following - IFEval), qui évalue la capacité des modèles à comprendre et exécuter des instructions complexes, il a obtenu un score de 92.1, égal à Amazon Nova Pro mais supérieur à GPT-4o (89.6) et Gemini 1.5 Pro (89.4) ;
- Multilinguisme (MGSM - 0-shot) : avec un score de 91.1, il excelle dans le traitement multilingue. Ce résultat est proche de LLama 3.1 405B (91,6), inférieur à Claude 3.5 Sonnet (92.8) mais meilleur que Gemini 1.5 Pro (90.6) ;
- Gestion de longs contextes (Long-context - NIH/Multi-needle) : il obtient 97.5, démontrant une très bonne capacité à traiter de grandes quantités d'informations sur des contextes étendus, surpassant Gemini 1.5 Pro (94.7).