
La génération de texte basée sur la récupération de connaissances (RAG) permet aux LLM de produire des textes informatifs et cohérents à partir de sources externes. Cependant, la qualité des textes générés dépend fortement de la pertinence des documents récupérés. Pour pallier à ce problème, des chercheurs proposent une méthode nommée "Corrective Retrieval Augmented Generation" (CRAG), qui améliore considérablement les performances des approches basées sur la RAG, donc la précision et la fiabilité des LLM.
Les avancées récentes dans le domaine des modèles de langage ont permis des progrès significatifs dans la génération automatique de texte. Cependant, ces modèles ne sont pas exempts de défis, notamment en ce qui concerne l’exactitude des informations générées. Lorsque les modèles se basent uniquement sur leurs connaissances internes, acquises au cours de l'entraînement, ils peuvent générer des résultats inexacts ou incohérents.
La Génération Augmentée par Récupération (RAG) a été introduite en 2020 pour améliorer la pertinence des informations produites par les LLM. Elle permet au modèle d'utiliser des sources de données externes pour générer des réponses plus précises et à jour, réduisant ainsi le phénomène d'hallucinations.
Pour l'équipe, composée de chercheurs de l'Université de Science et Technologie de Chine, de l'Université de Californie et de Google Research, "Bien que la génération augmentée de récupération (RAG) soit un complément pratique aux LLM, elle repose fortement sur la pertinence des documents récupérés, ce qui soulève des inquiétudes quant à la façon dont le modèle se comporte si la récupération tourne mal".
Ils proposent donc la CRAG, ou génération de récupération corrective augmentée, pour améliorer la robustesse de la génération basée sur la RAG en affinant les documents pertinents récupérés et en corrigeant ceux qui sont inexacts avec la recherche sur le Web.
La CRAG combine la RAG avec un mécanisme de correction automatique. Tout d'abord, un évaluateur de récupération léger est utilisé pour estimer la pertinence des documents récupérés par rapport à la requête d’entrée, et déclencher différentes actions de récupération de connaissances selon le degré de confiance : Correct, Ambigu, Incorrect.
Si les réponses sont ambigües ou incorrectes, des recherches sur le web à grande échelle permettent d'enrichir ou corriger les résultats de la RAG.
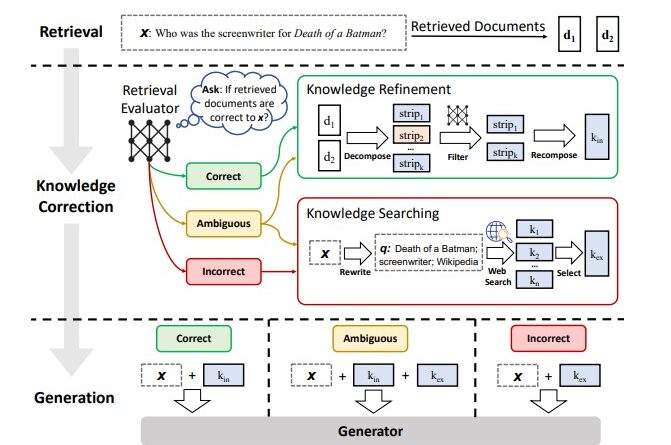 Les chercheurs ont également conçu un algorithme de décomposition-recomposition pour affiner les informations pertinentes dans les documents récupérés. La méthode est plug-and-play et peut être couplée avec diverses approches basées sur RAG.
Les chercheurs ont également conçu un algorithme de décomposition-recomposition pour affiner les informations pertinentes dans les documents récupérés. La méthode est plug-and-play et peut être couplée avec diverses approches basées sur RAG.
 CRAG représente une avancée significative dans le domaine de la génération de texte, permettant d’améliorer la robustesse des modèles de langage et de produire des textes plus précis et plus pertinents. Son adaptabilité à différentes tâches de génération de texte en fait une solution prometteuse pour de nombreuses applications du traitement du langage naturel dans divers domaines.
Références de l'article :
"Corrective Retrieval Augmented Generation" arXiv :2401.15884v1
Auteurs: Shi-Qi Yan1, Jia-Chen Gu2, Yun Zhu3, Zhen-Hua Ling1
1 : National Engineering Research Center of Speech and Language Information Processing,
University of Science and Technology of China, Hefei, China
2 : Department of Computer Science, University of California, Los Angeles
3 : Google Research
CRAG représente une avancée significative dans le domaine de la génération de texte, permettant d’améliorer la robustesse des modèles de langage et de produire des textes plus précis et plus pertinents. Son adaptabilité à différentes tâches de génération de texte en fait une solution prometteuse pour de nombreuses applications du traitement du langage naturel dans divers domaines.
Références de l'article :
"Corrective Retrieval Augmented Generation" arXiv :2401.15884v1
Auteurs: Shi-Qi Yan1, Jia-Chen Gu2, Yun Zhu3, Zhen-Hua Ling1
1 : National Engineering Research Center of Speech and Language Information Processing,
University of Science and Technology of China, Hefei, China
2 : Department of Computer Science, University of California, Los Angeles
3 : Google Research
Les chercheurs ont également conçu un algorithme de décomposition-recomposition pour affiner les informations pertinentes dans les documents récupérés. La méthode est plug-and-play et peut être couplée avec diverses approches basées sur RAG.
Evaluations de la méthode
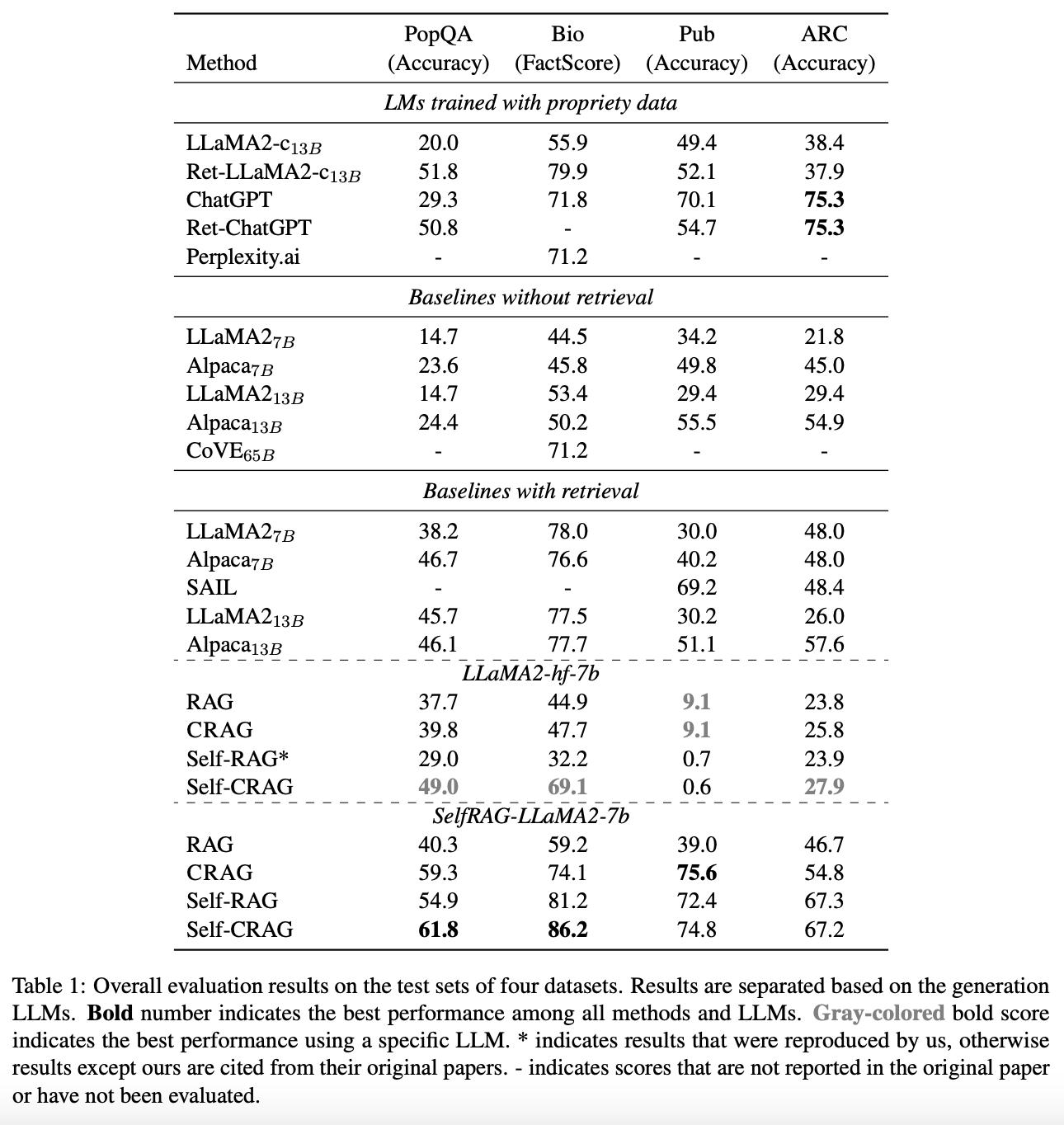
CRAG a été testé sur quatre jeux de données couvrant diverses tâches de génération :- PopQA : un ensemble de données utilisé pour évaluer les modèles de génération de texte sur des tâches de réponse à des questions de format court. Il comprend une collection de questions variées auxquelles les modèles doivent répondre en utilisant des connaissances factuelles ;
- Bio (Biography) : Le jeu de données Bio est destiné à évaluer les modèles de génération de texte sur des tâches de génération de biographies détaillées. Il contient des informations sur différentes entités, et les modèles doivent générer des biographies précises et informatives sur ces entité ;
- Pub : un jeu de données utilisé dans le domaine de la santé pour évaluer les modèles de génération de texte sur des tâches de vérification de faits et de réponse à des questions vrai ou faux. Il contient des affirmations sur des sujets liés à la santé, et les modèles doivent déterminer si ces affirmations sont vraies ou fausses ;
- ARC (Arc-Challenge) : ARC est un ensemble de données composé de questions à choix multiples sur des phénomènes scientifiques de bon sens quotidiens. Les modèles doivent sélectionner la réponse correcte parmi plusieurs choix pour chaque question, en se basant sur leur compréhension du contexte scientifique.
CRAG représente une avancée significative dans le domaine de la génération de texte, permettant d’améliorer la robustesse des modèles de langage et de produire des textes plus précis et plus pertinents. Son adaptabilité à différentes tâches de génération de texte en fait une solution prometteuse pour de nombreuses applications du traitement du langage naturel dans divers domaines.
Références de l'article :
"Corrective Retrieval Augmented Generation" arXiv :2401.15884v1
Auteurs: Shi-Qi Yan1, Jia-Chen Gu2, Yun Zhu3, Zhen-Hua Ling1
1 : National Engineering Research Center of Speech and Language Information Processing,
University of Science and Technology of China, Hefei, China
2 : Department of Computer Science, University of California, Los Angeles
3 : Google Research