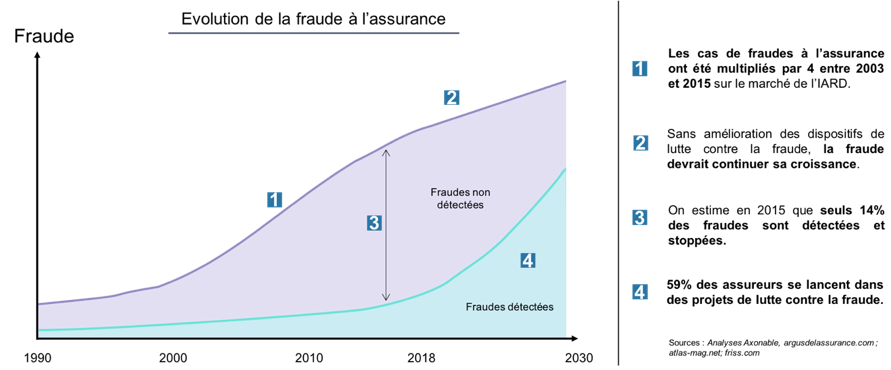
L’Agence pour la lutte contre la fraude à l’assurance (Alfa) a signalé dans son rapport annuel que la fraude à l’assurance représenterait un coût réel estimé à 2,5Md€ soit près de 5% des primes dommages en France. D’un autre côté, la fraude sur les cartes bancaires représenterait une perte de 400M€ selon le rapport annuel 2016 de l’Observatoire de la sécurité des moyens de paiement. Ces chiffres pourraient augmenter si les entreprises n’implémentent pas un mécanisme de détection des fraudes.
L’utilisation d’Internet a accentué les types de fraudes sur la dernière décennie, ceci s’intensifie de plus en plus avec l’utilisation des applications mobiles et bientôt des objets connectés. En conséquence, la détection et la prévention des fraudes est devenue un enjeu majeur pour beaucoup d’entreprise aujourd’hui. Les principaux challenges d’un mécanisme de détection des fraudes sont la grande quantité de données, l’évolution et la volatilité de types de fraudes.
Une analyse classique de données permet d’extraire les motifs caractéristiques des opérations dites « normales » et celles de « fraudes ». Ces systèmes de détection des fraudes traditionnels utilisent ces motifs afin de créer des règles métiers lesquelles dans certains cas ne sont pas assez flexibles et compliquent la prise de décision. Cela se traduit par un retard dans l’analyse de dossiers, dans la mise à jour des règles métiers ainsi que dans les remboursements aux assurés dans le cas des assurances.
Les motifs caractéristiques de la fraude varient d’un secteur à un autre et évoluent très rapidement. Une approche d’apprentissage automatique de type Deep Learning(apprentissage profond) permet de pallier ces problèmes en réduisant le temps de traitement de données ainsi qu’en améliorant le taux de détection de fraudes. En effet, un algorithme prédictif de type Deep Learning permet d’automatiser l’extraction de motifs caractéristiques, d’exploiter des données non-structurés, et utiliser des règles plus flexibles, tout ceci en aidant la prise de décision d’un analyste métier et en réduisant l’effort de l’analyse des grandes quantités des données. Ce type de traitement automatique de données peut fournir des outils plus performants, aider à mieux cibler les opérations douteuses ainsi qu’améliorer la découverte des nouveaux types de fraudes.
Comment améliorer un mécanisme de détection des fraudes en utilisant du Machine Learning
Les systèmes de détection des fraudes classiques sont confrontés à plusieurs problèmes dont les plus importants sont : la qualité et le format de données à traiter, la grande quantité de données non labélisées et l’automatisation de la prédiction des fraudes. Pour pallier ces problèmes, l’utilisation d’une approche mixte d’apprentissage supervisé et non-supervisé peut être envisagé. L’approche d’apprentissage non-supervisé peut réduire l’effort de labélisation tandis qu’une approche d’apprentissage supervisé peut automatiser la prédiction des fraudes.
Auto-encodeur : un algorithme d’apprentissage non-supervisé pour réduire l’effort de traitement de grande quantité de données
Un Auto-encodeur est un réseau de neurones artificiels qui est souvent utilisé dans l’apprentissage des caractéristiques discriminantes d’un ensemble de données. Un auto-encodeur peut être vu comme l’ensemble d’un encodeur et d’un décodeur. L’encodeur cherche à réduire les dimensions des données d’entrée afin de les représenter dans un nouvel espace ou encodage tandis que le décodeur cherche à reconstruire les données à partir de l’encodage. Le but étant de reconstruire une donnée à partir de l’encodage en minimisant l’erreur de reconstruction. Si un auto-encodeur est entrainé pour apprendre la représentation des opérations non-frauduleuses, les opérations reconstruites à partir de leur encodage qui ont une grande erreur de reconstruction peuvent être considérées comme des opérations suspicieuses. L’auto-encodeur peut ainsi être utilisé pour réduire l’effort de labélisation des données.
MLP : un algorithme d’apprentissage supervisé pour automatiser la prédiction des fraudes
Nous avons vu précédemment que l’auto-encodeur permet de faire face au problème de labélisation des données. Cependant, pour faire face à la prédiction d’une fraude d’une façon plus performante et autonome, nous devons faire appel à un algorithme d’apprentissage supervisé. Pour ce faire, nous pouvons utiliser une architecture tel qu’un Multi-layer-Perceptron (MLP).
Un MLP est un réseau de neurones qui peut contenir plusieurs couches de neurones où tous les neurones d’une couche sont connectés à tous les neurones de la couche suivante. Ce type de connexion de neurones nous permet d’utiliser toutes les caractéristiques d’une donnée d’entrée afin de prédire une fraude.
Un problème très récurrent dans les systèmes de détection classiques est la mise à jour des règles métiers suite à l’arrivée d’un nouveau type de fraude. L’industrialisation d’un model prédictif tels que ceux décrit précédemment permettent de répondre en partie à ce problème. D’autres approches tels que l’Active Learning et l’Online Learning permettent d’industrialiser ce processus.
Vous voulez en savoir plus sur les mécanismes de détection des fraudes ? N’hésitez pas à nous contacter.



