
Une équipe de recherche de Google Brain a revisité les perceptrons multicouches (MLP pour multilayer perceptron) en concevant MLP-Mixer. Il s'agit d'un modèle sans fioritures qui approche les performances de pointe dans la classification ImageNet, et qui pourrait atteindre des performances comparables à des systèmes comme ViT (Vision Transformer), BiT (Big Transfer), HaloNet et NF-Net. À l'avenir, il est tout à fait possible de penser que les réseaux neuronaux multicouches les plus simples puissent être plus sophistiqués que les architectures actuelles les plus avancées.
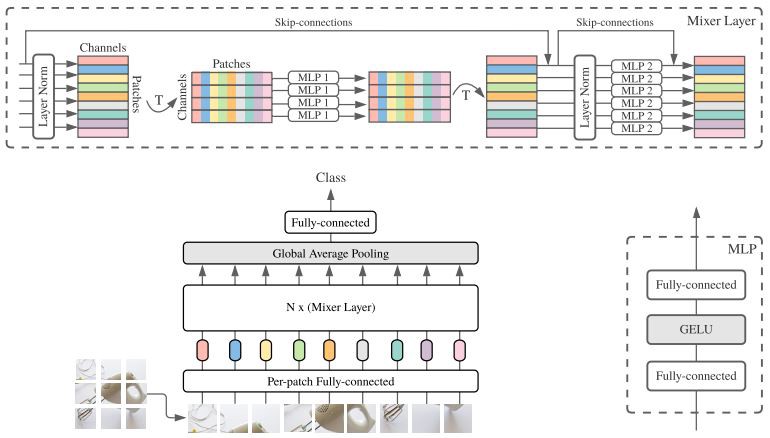 MLP-Mixer comporte un classificateur principal, de plusieurs couches de mélangeurs et d'incorporations linéaires. Chaque couche contient un MLP gérant les tokens et l'autre gérant les canaux, qui sont composés de deux couches entièrement connectées.[/caption]
MLP-Mixer comporte un classificateur principal, de plusieurs couches de mélangeurs et d'incorporations linéaires. Chaque couche contient un MLP gérant les tokens et l'autre gérant les canaux, qui sont composés de deux couches entièrement connectées.[/caption]
Une étude pour exploiter les perceptrons multicouches pour la classification d'images et la vision par ordinateur
À l'heure actuelle, les réseaux de neurones convolutifs excellent dans le traitement des images et dans la vision par ordinateur, car ils sont conçus pour discerner les relations spatiales, et les pixels qui sont proches les uns des autres dans une image qui ont tendance à être plus liés que les pixels qui sont éloignés les uns des autres. Les MLP ne possèdent pas ce biais, ce qui fait qu'ils ont tendance à prendre en compte les relations interpixels qui existent, mais qui ne sont pas nécessaires au processus de traitement d'image. Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov et Lucas Beyer, accompagnées de chercheurs de Google Brain ont eu l'idée de modifier les MLP afin qu'ils puissent traiter et comparer les images à travers des patchs plutôt qu'en analysant chaque pixel individuellement. C'est ainsi qu'ils ont conçu MLP-Mixer, qui permet aux MLP d'exploiter ce processus. Leur création a fait l'objet d'une publication intitulé "MLP-Mixer: An all-MLP Architecture for Vision". Il faut savoir que les MLP sont les "blocs de construction" les plus simples du deep learning. Ce travail montre qu'ils peuvent faire le poids face aux architectures les plus performantes pour la classification d'images.Comment MLP-Mixer a-t-il été conçu et comment fonctionne-t-il ?
Les auteurs ont préformé MLP-Mixer pour la classification d'images à l'aide d'ImageNet-21k, qui contient 21 000 classes, et l'ont affiné sur ImageNet qui dispose de 1 000 classes. Prenons une image divisée en patchs, MLP-Mixer utilise une couche linéaire initiale pour générer 1 024 représentations de chaque patch. MLP-Mixer empile les représentations dans une matrice, de sorte que chaque ligne contient toutes les représentations d'un patch et chaque colonne contient une représentation de chaque patch. MLP-Mixer est composé d'une série de couches de mixage, chacune contenant deux MLP, chacune composée de deux couches entièrement connectées. Étant donné une matrice, une couche de mélangeur utilise un MLP pour mélanger les représentations dans les colonnes (que les auteurs appellent le mélange de jetons) et un autre pour mélanger les représentations dans les lignes (que les auteurs appellent le mélange de canaux). Ce processus rend une nouvelle matrice à transmettre à la couche de mélangeur suivante. Une couche softmax rend une classification. [caption id="attachment_31422" align="aligncenter" width="770"] MLP-Mixer comporte un classificateur principal, de plusieurs couches de mélangeurs et d'incorporations linéaires. Chaque couche contient un MLP gérant les tokens et l'autre gérant les canaux, qui sont composés de deux couches entièrement connectées.[/caption]