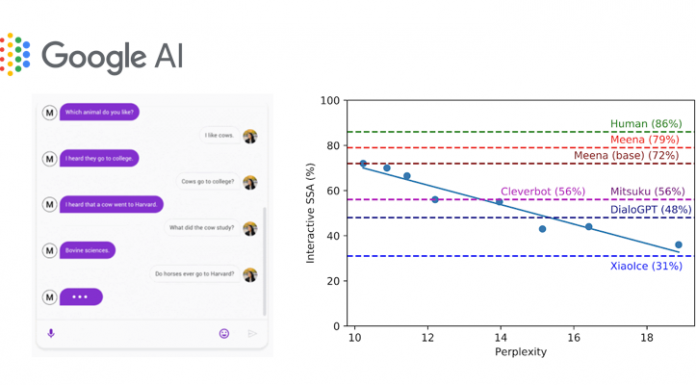
Ce 28 janvier, Google AI a publié un post de blog traduit en français ci-dessous concernant leurs avancées vers un agent conversationnel capable de parler de tout. Écrit par Daniel Adiwardana et Thang Luong de la Brain Team de Google Research, cet article fait référence à la publication sur ArXiv de leurs recherches sur leur chatbot Meena, intitulé Towards a Human-like Open-Domain Chatbot.
Les agents conversationnels modernes (chatbots) ont tendance à être hautement spécialisés - ils fonctionnent bien tant que les utilisateurs ne s'éloignent pas trop de leur utilisation prévue. Pour mieux gérer une grande variété de sujets conversationnels, la recherche sur les dialogues en open source explore une approche complémentaire essayant de développer un chatbot qui n'est pas spécialisé mais qui peut toujours discuter de pratiquement tout ce qu'un utilisateur veut. En plus d'être un problème de recherche fascinant, un tel agent conversationnel pourrait conduire à de nombreuses applications intéressantes, telles que l'humanisation des interactions informatiques, l'amélioration de la pratique des langues étrangères et la création de personnages de films et de jeux vidéo interactifs.
Cependant, les chatbots actuels en open source ont une faille critique - ils ne font souvent aucun sens. Ils disent parfois des choses qui ne correspondent pas à ce qui a été dit jusqu'à présent, ou manquent de bon sens et de connaissances de base sur le monde. De plus, les chatbots donnent souvent des réponses qui ne sont pas spécifiques au contexte actuel. Par exemple, « Je ne sais pas » est une réponse sensée à n'importe quelle question, mais elle n'est pas spécifique. Les chatbots actuels le font beaucoup plus souvent que les gens car ils couvrent de nombreuses entrées utilisateur possibles.
Dans Towards a Human-like Open-Domain Chatbot, nous présentons Meena, un modèle conversationnel neuronal formé de 2,6 milliards de paramètres de bout en bout. Nous montrons que Meena peut mener des conversations plus sensibles et spécifiques que les chatbots de pointe existants. Ces améliorations se reflètent dans une nouvelle mesure d'évaluation humaine que nous proposons pour les chatbots en open source, baptisée Sensibleness and Specificity Average (SSA), qui capture les attributs de base, mais importants pour la conversation humaine. Remarquablement, nous démontrons que la perplexité, une métrique automatique qui est facilement disponible pour tous les modèles de conversation neuronaux, est fortement corrélée avec la SSA.
 Meena est un modèle conversationnel neuronal de bout en bout qui apprend à répondre de manière sensible à un contexte conversationnel donné. L'objectif de la formation est de minimiser la perplexité, l'incertitude de prédire le prochain token (dans ce cas, le mot suivant dans une conversation). Au cœur se trouve l'architecture Evolved Transformer seq2seq, une architecture Transformer découverte via une architecture neuronale évolutive pour améliorer la perplexité.
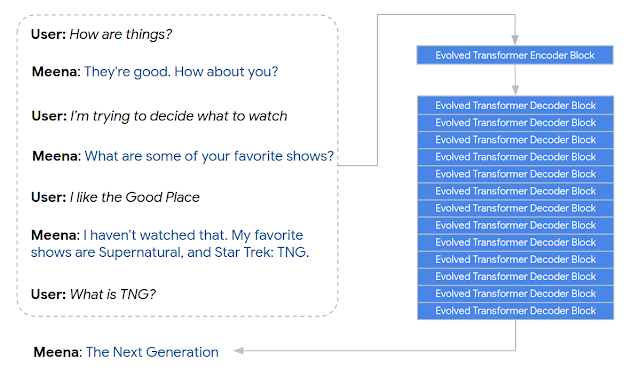
Concrètement, Meena a un seul bloc codeur Evolved Transformer et 13 blocs décodeurs Evolved Transformer comme illustré ci-dessous. L'encodeur est responsable du traitement du contexte de conversation pour aider Meena à comprendre ce qui a déjà été dit dans la conversation. Le décodeur utilise ensuite ces informations pour formuler une réponse réelle. En ajustant les hyper-paramètres, nous avons découvert qu'un décodeur plus puissant était la clé d'une meilleure qualité conversationnelle.
Meena est un modèle conversationnel neuronal de bout en bout qui apprend à répondre de manière sensible à un contexte conversationnel donné. L'objectif de la formation est de minimiser la perplexité, l'incertitude de prédire le prochain token (dans ce cas, le mot suivant dans une conversation). Au cœur se trouve l'architecture Evolved Transformer seq2seq, une architecture Transformer découverte via une architecture neuronale évolutive pour améliorer la perplexité.
Concrètement, Meena a un seul bloc codeur Evolved Transformer et 13 blocs décodeurs Evolved Transformer comme illustré ci-dessous. L'encodeur est responsable du traitement du contexte de conversation pour aider Meena à comprendre ce qui a déjà été dit dans la conversation. Le décodeur utilise ensuite ces informations pour formuler une réponse réelle. En ajustant les hyper-paramètres, nous avons découvert qu'un décodeur plus puissant était la clé d'une meilleure qualité conversationnelle.
 Les conversations utilisées pour la formation sont organisées sous forme de tree threads, où chaque réponse dans le thread est considérée comme un tour de conversation. Nous extrayons chaque exemple de formation à la conversation, avec sept tours de contexte, comme un chemin à travers un fil d'arbre. Nous en choisissons sept pouvoir avoir un bon équilibre entre compter sur un contexte suffisamment long pour former un modèle conversationnel et adapter les modèles aux contraintes de mémoire (les contextes plus longs prennent plus de mémoire).
Le modèle Meena a 2,6 milliards de paramètres et est formé sur 341 Go de texte, filtré à partir des conversations des médias sociaux du domaine public. Par rapport à un modèle génératif de pointe existant, OpenAI GPT-2, Meena a une capacité de modèle 1,7 fois supérieure et a été formée sur 8,5 fois plus de données.
Métrique d'évaluation humaine : Sensibleness and Specificity Average (SSA)
Les métriques d'évaluation humaine existantes pour la qualité du chatbot ont tendance à être complexes et ne donnent pas un accord cohérent entre les examinateurs. Cela nous a motivés à concevoir une nouvelle métrique d'évaluation humaine, la Sensibleness and Specificity Average (SSA), qui capture les attributs de base, mais importants pour les conversations naturelles.
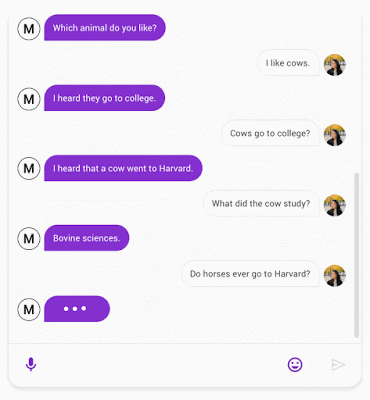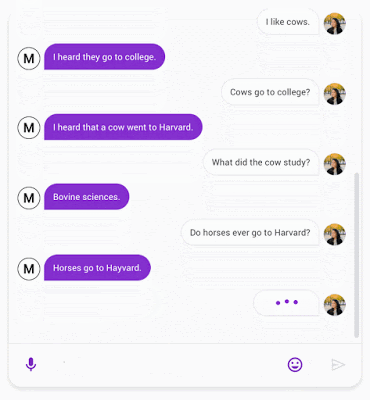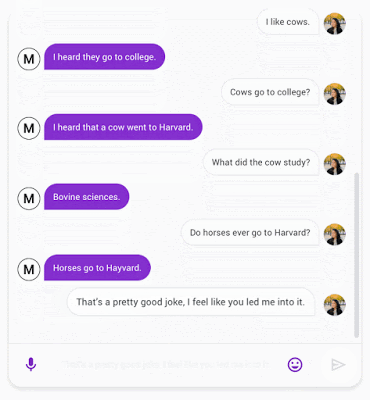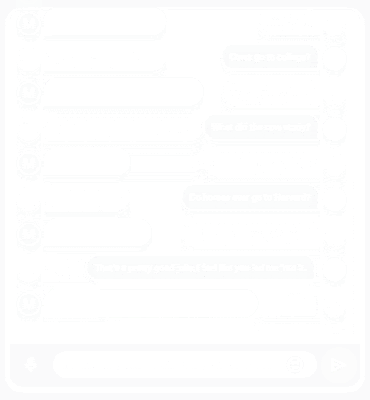
Pour calculer la SSA, nous avons créé une conversation de forme libre avec les chatbots testés - Meena et d'autres chatbots open source bien connus, notamment Mitsuku, Cleverbot, XiaoIce et DialoGPT. Afin d'assurer la cohérence entre les évaluations, chaque conversation commence par le même message d'accueil, « Hi! ». Pour chaque énoncé, les animateurs de la foule répondent à deux questions: « Does it make sense? » Et « is it specific? ». L'évaluateur est invité à faire preuve de bon sens pour juger si une réponse est tout à fait raisonnable dans son contexte. Si quelque chose semble faux - déroutant, illogique, hors contexte ou factuellement erroné - alors il doit être évalué comme « does not make sense ». Si la réponse a un sens, l'énoncé est ensuite évalué pour déterminer s'il est spécifique au contexte donné. Par exemple, si A dit : « I love tennis » et B répond « That's nice », l'énoncé devrait être marqué « not specific ». Cette réponse pourrait être utilisée dans des dizaines de contextes différents. Mais si B répond: « Me too, I can't get enough of Roger Federer! », Alors il est marqué comme « specific », car il est étroitement lié à ce qui est discuté.
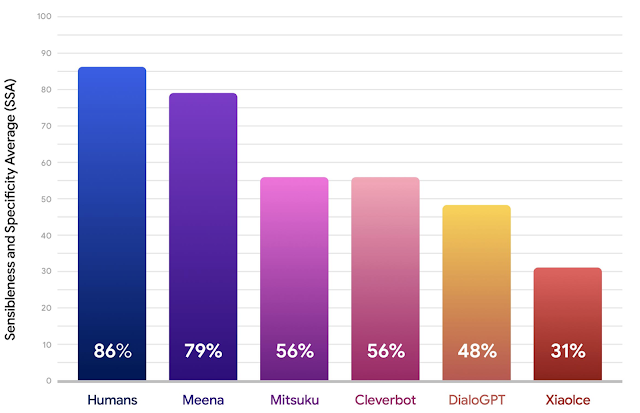
Pour chaque chatbot, nous collectons entre 1600 et 2400 tours de conversation individuels à travers environ 100 conversations. Chaque réponse du modèle est étiquetée par les travailleurs de foule pour indiquer si elle est sensible et spécifique. La sensibilité d'un chatbot est la fraction des réponses étiquetées « sensible », et la spécificité est la fraction des réponses qui sont marquées « specific ». La moyenne de ces deux est le score SSA. Les résultats ci-dessous démontrent que Meena fait beaucoup mieux que les chatbots de pointe existants par de grandes marges en termes de scores SSA, et comble l'écart avec les performances humaines.
Les conversations utilisées pour la formation sont organisées sous forme de tree threads, où chaque réponse dans le thread est considérée comme un tour de conversation. Nous extrayons chaque exemple de formation à la conversation, avec sept tours de contexte, comme un chemin à travers un fil d'arbre. Nous en choisissons sept pouvoir avoir un bon équilibre entre compter sur un contexte suffisamment long pour former un modèle conversationnel et adapter les modèles aux contraintes de mémoire (les contextes plus longs prennent plus de mémoire).
Le modèle Meena a 2,6 milliards de paramètres et est formé sur 341 Go de texte, filtré à partir des conversations des médias sociaux du domaine public. Par rapport à un modèle génératif de pointe existant, OpenAI GPT-2, Meena a une capacité de modèle 1,7 fois supérieure et a été formée sur 8,5 fois plus de données.
Métrique d'évaluation humaine : Sensibleness and Specificity Average (SSA)
Les métriques d'évaluation humaine existantes pour la qualité du chatbot ont tendance à être complexes et ne donnent pas un accord cohérent entre les examinateurs. Cela nous a motivés à concevoir une nouvelle métrique d'évaluation humaine, la Sensibleness and Specificity Average (SSA), qui capture les attributs de base, mais importants pour les conversations naturelles.
Pour calculer la SSA, nous avons créé une conversation de forme libre avec les chatbots testés - Meena et d'autres chatbots open source bien connus, notamment Mitsuku, Cleverbot, XiaoIce et DialoGPT. Afin d'assurer la cohérence entre les évaluations, chaque conversation commence par le même message d'accueil, « Hi! ». Pour chaque énoncé, les animateurs de la foule répondent à deux questions: « Does it make sense? » Et « is it specific? ». L'évaluateur est invité à faire preuve de bon sens pour juger si une réponse est tout à fait raisonnable dans son contexte. Si quelque chose semble faux - déroutant, illogique, hors contexte ou factuellement erroné - alors il doit être évalué comme « does not make sense ». Si la réponse a un sens, l'énoncé est ensuite évalué pour déterminer s'il est spécifique au contexte donné. Par exemple, si A dit : « I love tennis » et B répond « That's nice », l'énoncé devrait être marqué « not specific ». Cette réponse pourrait être utilisée dans des dizaines de contextes différents. Mais si B répond: « Me too, I can't get enough of Roger Federer! », Alors il est marqué comme « specific », car il est étroitement lié à ce qui est discuté.
Pour chaque chatbot, nous collectons entre 1600 et 2400 tours de conversation individuels à travers environ 100 conversations. Chaque réponse du modèle est étiquetée par les travailleurs de foule pour indiquer si elle est sensible et spécifique. La sensibilité d'un chatbot est la fraction des réponses étiquetées « sensible », et la spécificité est la fraction des réponses qui sont marquées « specific ». La moyenne de ces deux est le score SSA. Les résultats ci-dessous démontrent que Meena fait beaucoup mieux que les chatbots de pointe existants par de grandes marges en termes de scores SSA, et comble l'écart avec les performances humaines.
 Métrique automatique : Perplexité
Les chercheurs recherchent depuis longtemps une mesure d'évaluation automatique qui est en corrélation avec une évaluation humaine plus précise. Cela permettrait un développement plus rapide des modèles de dialogue, mais jusqu'à présent, trouver une telle mesure automatique a été difficile. Étonnamment, dans notre travail, nous découvrons que la perplexité, une métrique automatique qui est facilement disponible pour tout modèle neuronal seq2seq, présente une forte corrélation avec l'évaluation humaine, comme la valeur SSA. La perplexité mesure l'incertitude d'un modèle de langage. Plus la perplexité est faible, plus le modèle est confiant dans la génération du prochain token (caractère, sous-mot ou mot). Conceptuellement, la perplexité représente le nombre de choix que le modèle essaie de choisir lors de la production du prochain token.
Pendant le développement, nous avons comparé huit versions de modèles différentes avec des hyperparamètres et des architectures variables, telles que le nombre de couches, les attention heads, le nombre total d'étapes de formation, que nous utilisions Evolved Transformer ou Transformer ordinaire, et que nous nous entraînions avec des étiquettes rigides ou avec une distillation. Comme illustré dans la figure ci-dessous, plus la perplexité est faible, meilleur est le score SSA du modèle, avec un fort coefficient de corrélation (R2 = 0,93).
Métrique automatique : Perplexité
Les chercheurs recherchent depuis longtemps une mesure d'évaluation automatique qui est en corrélation avec une évaluation humaine plus précise. Cela permettrait un développement plus rapide des modèles de dialogue, mais jusqu'à présent, trouver une telle mesure automatique a été difficile. Étonnamment, dans notre travail, nous découvrons que la perplexité, une métrique automatique qui est facilement disponible pour tout modèle neuronal seq2seq, présente une forte corrélation avec l'évaluation humaine, comme la valeur SSA. La perplexité mesure l'incertitude d'un modèle de langage. Plus la perplexité est faible, plus le modèle est confiant dans la génération du prochain token (caractère, sous-mot ou mot). Conceptuellement, la perplexité représente le nombre de choix que le modèle essaie de choisir lors de la production du prochain token.
Pendant le développement, nous avons comparé huit versions de modèles différentes avec des hyperparamètres et des architectures variables, telles que le nombre de couches, les attention heads, le nombre total d'étapes de formation, que nous utilisions Evolved Transformer ou Transformer ordinaire, et que nous nous entraînions avec des étiquettes rigides ou avec une distillation. Comme illustré dans la figure ci-dessous, plus la perplexité est faible, meilleur est le score SSA du modèle, avec un fort coefficient de corrélation (R2 = 0,93).
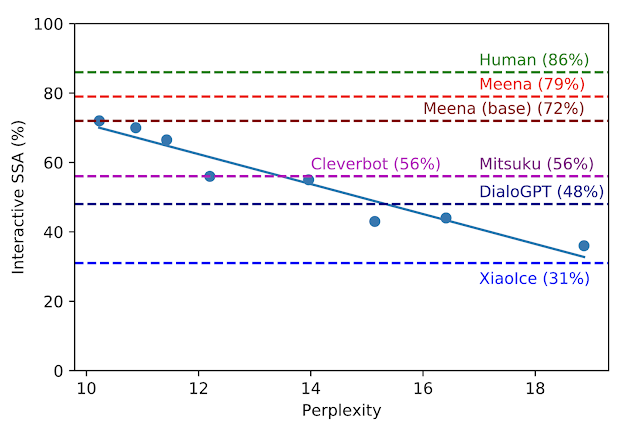 Notre meilleur modèle Meena formé de bout en bout, appelé Meena (base), atteint une perplexité de 10,2 et cela se traduit par un score SSA de 72%. Comparé aux scores SSA obtenus par d'autres chatbots, notre score SSA de 72% n'est pas loin des 86% SSA obtenus par une personne moyenne. La version complète de Meena, qui dispose d'un mécanisme de filtrage et d'un décodage réglé, fait progresser le score SSA à 79%.
Recherches et défis à venir
Comme indiqué précédemment, nous poursuivrons notre objectif de réduire la perplexité des modèles de conversation neuronaux grâce à des améliorations des algorithmes, des architectures, des données et du calcul.
Alors que nous nous sommes concentrés uniquement sur la sensibilité et la spécificité dans ce travail, d'autres attributs tels que la personnalité et la factualité méritent également d'être pris en compte dans les travaux ultérieurs. De plus, la lutte contre la sécurité et les biais dans les modèles est un domaine clé pour nous, et étant donné les défis liés à cela, nous ne publions pas actuellement de démonstration de recherche externe. Nous évaluons cependant les risques et les avantages associés à l'externalisation du point de contrôle du modèle et nous pouvons choisir de le rendre disponible dans les prochains mois afin de faire avancer la recherche dans ce domaine.
Remerciements
Plusieurs membres ont énormément contribué à ce projet : David So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu. Merci également à Quoc Le, Samy Bengio et Christine Robson pour leur soutien expert. Merci aux personnes qui ont donné leur avis sur les versions préliminaires du document : Anna Goldie, Abigail See, YizheZhang, Lauren Kunze, Steve Worswick, Jianfeng Gao, Scott Roy, Ilya Sutskever, Tatsu Hashimoto, Dan Jurafsky, Dilek Hakkani-tur, Noam Shazeer, Gabriel Bender, Prajit Ramachandran, Rami Al-Rfou, Michael Fink, Mingxing Tan, Maarten Bosma et Adams Yu. Merci également aux nombreux bénévoles qui ont aidé à collecter des conversations entre eux et avec divers chatbots. Enfin, merci à Noam Shazeer, Rami Al-Rfou, Khoa Vo, Trieu H. Trinh, Ni Yan, Kyu Jin Hwang et l'équipe de Google Brain pour leur aide avec le projet.
Notre meilleur modèle Meena formé de bout en bout, appelé Meena (base), atteint une perplexité de 10,2 et cela se traduit par un score SSA de 72%. Comparé aux scores SSA obtenus par d'autres chatbots, notre score SSA de 72% n'est pas loin des 86% SSA obtenus par une personne moyenne. La version complète de Meena, qui dispose d'un mécanisme de filtrage et d'un décodage réglé, fait progresser le score SSA à 79%.
Recherches et défis à venir
Comme indiqué précédemment, nous poursuivrons notre objectif de réduire la perplexité des modèles de conversation neuronaux grâce à des améliorations des algorithmes, des architectures, des données et du calcul.
Alors que nous nous sommes concentrés uniquement sur la sensibilité et la spécificité dans ce travail, d'autres attributs tels que la personnalité et la factualité méritent également d'être pris en compte dans les travaux ultérieurs. De plus, la lutte contre la sécurité et les biais dans les modèles est un domaine clé pour nous, et étant donné les défis liés à cela, nous ne publions pas actuellement de démonstration de recherche externe. Nous évaluons cependant les risques et les avantages associés à l'externalisation du point de contrôle du modèle et nous pouvons choisir de le rendre disponible dans les prochains mois afin de faire avancer la recherche dans ce domaine.
Remerciements
Plusieurs membres ont énormément contribué à ce projet : David So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu. Merci également à Quoc Le, Samy Bengio et Christine Robson pour leur soutien expert. Merci aux personnes qui ont donné leur avis sur les versions préliminaires du document : Anna Goldie, Abigail See, YizheZhang, Lauren Kunze, Steve Worswick, Jianfeng Gao, Scott Roy, Ilya Sutskever, Tatsu Hashimoto, Dan Jurafsky, Dilek Hakkani-tur, Noam Shazeer, Gabriel Bender, Prajit Ramachandran, Rami Al-Rfou, Michael Fink, Mingxing Tan, Maarten Bosma et Adams Yu. Merci également aux nombreux bénévoles qui ont aidé à collecter des conversations entre eux et avec divers chatbots. Enfin, merci à Noam Shazeer, Rami Al-Rfou, Khoa Vo, Trieu H. Trinh, Ni Yan, Kyu Jin Hwang et l'équipe de Google Brain pour leur aide avec le projet.
Meena est un modèle conversationnel neuronal de bout en bout qui apprend à répondre de manière sensible à un contexte conversationnel donné. L'objectif de la formation est de minimiser la perplexité, l'incertitude de prédire le prochain token (dans ce cas, le mot suivant dans une conversation). Au cœur se trouve l'architecture Evolved Transformer seq2seq, une architecture Transformer découverte via une architecture neuronale évolutive pour améliorer la perplexité.
Concrètement, Meena a un seul bloc codeur Evolved Transformer et 13 blocs décodeurs Evolved Transformer comme illustré ci-dessous. L'encodeur est responsable du traitement du contexte de conversation pour aider Meena à comprendre ce qui a déjà été dit dans la conversation. Le décodeur utilise ensuite ces informations pour formuler une réponse réelle. En ajustant les hyper-paramètres, nous avons découvert qu'un décodeur plus puissant était la clé d'une meilleure qualité conversationnelle.
Les conversations utilisées pour la formation sont organisées sous forme de tree threads, où chaque réponse dans le thread est considérée comme un tour de conversation. Nous extrayons chaque exemple de formation à la conversation, avec sept tours de contexte, comme un chemin à travers un fil d'arbre. Nous en choisissons sept pouvoir avoir un bon équilibre entre compter sur un contexte suffisamment long pour former un modèle conversationnel et adapter les modèles aux contraintes de mémoire (les contextes plus longs prennent plus de mémoire).
Le modèle Meena a 2,6 milliards de paramètres et est formé sur 341 Go de texte, filtré à partir des conversations des médias sociaux du domaine public. Par rapport à un modèle génératif de pointe existant, OpenAI GPT-2, Meena a une capacité de modèle 1,7 fois supérieure et a été formée sur 8,5 fois plus de données.
Métrique d'évaluation humaine : Sensibleness and Specificity Average (SSA)
Les métriques d'évaluation humaine existantes pour la qualité du chatbot ont tendance à être complexes et ne donnent pas un accord cohérent entre les examinateurs. Cela nous a motivés à concevoir une nouvelle métrique d'évaluation humaine, la Sensibleness and Specificity Average (SSA), qui capture les attributs de base, mais importants pour les conversations naturelles.
Pour calculer la SSA, nous avons créé une conversation de forme libre avec les chatbots testés - Meena et d'autres chatbots open source bien connus, notamment Mitsuku, Cleverbot, XiaoIce et DialoGPT. Afin d'assurer la cohérence entre les évaluations, chaque conversation commence par le même message d'accueil, « Hi! ». Pour chaque énoncé, les animateurs de la foule répondent à deux questions: « Does it make sense? » Et « is it specific? ». L'évaluateur est invité à faire preuve de bon sens pour juger si une réponse est tout à fait raisonnable dans son contexte. Si quelque chose semble faux - déroutant, illogique, hors contexte ou factuellement erroné - alors il doit être évalué comme « does not make sense ». Si la réponse a un sens, l'énoncé est ensuite évalué pour déterminer s'il est spécifique au contexte donné. Par exemple, si A dit : « I love tennis » et B répond « That's nice », l'énoncé devrait être marqué « not specific ». Cette réponse pourrait être utilisée dans des dizaines de contextes différents. Mais si B répond: « Me too, I can't get enough of Roger Federer! », Alors il est marqué comme « specific », car il est étroitement lié à ce qui est discuté.
Pour chaque chatbot, nous collectons entre 1600 et 2400 tours de conversation individuels à travers environ 100 conversations. Chaque réponse du modèle est étiquetée par les travailleurs de foule pour indiquer si elle est sensible et spécifique. La sensibilité d'un chatbot est la fraction des réponses étiquetées « sensible », et la spécificité est la fraction des réponses qui sont marquées « specific ». La moyenne de ces deux est le score SSA. Les résultats ci-dessous démontrent que Meena fait beaucoup mieux que les chatbots de pointe existants par de grandes marges en termes de scores SSA, et comble l'écart avec les performances humaines.
Métrique automatique : Perplexité
Les chercheurs recherchent depuis longtemps une mesure d'évaluation automatique qui est en corrélation avec une évaluation humaine plus précise. Cela permettrait un développement plus rapide des modèles de dialogue, mais jusqu'à présent, trouver une telle mesure automatique a été difficile. Étonnamment, dans notre travail, nous découvrons que la perplexité, une métrique automatique qui est facilement disponible pour tout modèle neuronal seq2seq, présente une forte corrélation avec l'évaluation humaine, comme la valeur SSA. La perplexité mesure l'incertitude d'un modèle de langage. Plus la perplexité est faible, plus le modèle est confiant dans la génération du prochain token (caractère, sous-mot ou mot). Conceptuellement, la perplexité représente le nombre de choix que le modèle essaie de choisir lors de la production du prochain token.
Pendant le développement, nous avons comparé huit versions de modèles différentes avec des hyperparamètres et des architectures variables, telles que le nombre de couches, les attention heads, le nombre total d'étapes de formation, que nous utilisions Evolved Transformer ou Transformer ordinaire, et que nous nous entraînions avec des étiquettes rigides ou avec une distillation. Comme illustré dans la figure ci-dessous, plus la perplexité est faible, meilleur est le score SSA du modèle, avec un fort coefficient de corrélation (R2 = 0,93).
Notre meilleur modèle Meena formé de bout en bout, appelé Meena (base), atteint une perplexité de 10,2 et cela se traduit par un score SSA de 72%. Comparé aux scores SSA obtenus par d'autres chatbots, notre score SSA de 72% n'est pas loin des 86% SSA obtenus par une personne moyenne. La version complète de Meena, qui dispose d'un mécanisme de filtrage et d'un décodage réglé, fait progresser le score SSA à 79%.
Recherches et défis à venir
Comme indiqué précédemment, nous poursuivrons notre objectif de réduire la perplexité des modèles de conversation neuronaux grâce à des améliorations des algorithmes, des architectures, des données et du calcul.
Alors que nous nous sommes concentrés uniquement sur la sensibilité et la spécificité dans ce travail, d'autres attributs tels que la personnalité et la factualité méritent également d'être pris en compte dans les travaux ultérieurs. De plus, la lutte contre la sécurité et les biais dans les modèles est un domaine clé pour nous, et étant donné les défis liés à cela, nous ne publions pas actuellement de démonstration de recherche externe. Nous évaluons cependant les risques et les avantages associés à l'externalisation du point de contrôle du modèle et nous pouvons choisir de le rendre disponible dans les prochains mois afin de faire avancer la recherche dans ce domaine.
Remerciements
Plusieurs membres ont énormément contribué à ce projet : David So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu. Merci également à Quoc Le, Samy Bengio et Christine Robson pour leur soutien expert. Merci aux personnes qui ont donné leur avis sur les versions préliminaires du document : Anna Goldie, Abigail See, YizheZhang, Lauren Kunze, Steve Worswick, Jianfeng Gao, Scott Roy, Ilya Sutskever, Tatsu Hashimoto, Dan Jurafsky, Dilek Hakkani-tur, Noam Shazeer, Gabriel Bender, Prajit Ramachandran, Rami Al-Rfou, Michael Fink, Mingxing Tan, Maarten Bosma et Adams Yu. Merci également aux nombreux bénévoles qui ont aidé à collecter des conversations entre eux et avec divers chatbots. Enfin, merci à Noam Shazeer, Rami Al-Rfou, Khoa Vo, Trieu H. Trinh, Ni Yan, Kyu Jin Hwang et l'équipe de Google Brain pour leur aide avec le projet.