En bref : Les chercheurs de Google ont développé MLE-STAR, un agent d'apprentissage automatique qui améliore le processus de création de modèles d'IA en combinant recherche web ciblée, raffinement du code et assemblage adaptatif. MLE-STAR a démontré son efficacité en remportant 63% des compétitions dans le benchmark MLE-Bench-Lite basé sur Kaggle, surpassant largement les approches précédentes.
Sommaire
Les agents MLE (Machine Learning Engineering agent), basés sur de grands modèles de langage (LLMs), ont ouvert de nouvelles perspectives dans le développement des modèles d’apprentissage automatique en automatisant tout ou partie du processus. Cependant, Les solutions existantes se heurtent souvent à des limites d’exploration ou à un manque de diversité méthodologique. Les chercheurs de Google répondent à ces défis avec MLE-STAR, un agent qui combine recherche web ciblée, raffinement granulaire des blocs de code et stratégie d’assemblage adaptative.
Concrètement, un agent MLE part d’une description de tâche (par exemple, " prédire les ventes à partir de données tabulaires") et d’ensembles de données fournis, puis :
-
Analyse le problème et choisit une approche adaptée ;
-
Génère du code (souvent en Python, avec des bibliothèques ML courantes ou spécialisées) ;
-
Teste, évalue et affine la solution, parfois en plusieurs itérations.
Ces agents s’appuient sur deux compétences clés des LLM :
-
Le raisonnement algorithmique (identifier les méthodes pertinentes pour un problème donné) ;
-
La génération de code exécutable (scripts complets de préparation de données, d’entraînement et d’évaluation).
Leur objectif est de réduire la charge de travail humaine en automatisant des étapes fastidieuses comme l’ingénierie des caractéristiques, le réglage d’hyperparamètres ou la sélection de modèles.
MLE-STAR : une optimisation ciblée et itérative
Selon Google Research, les MLE existants se heurtent à deux obstacles majeurs. Tout d'abord, leur forte dépendance aux connaissances internes des LLMs les pousse à privilégier des méthodes génériques et bien établies, comme la bibliothèque scikit-learn pour les données tabulaires, au détriment d’approches plus spécialisées et potentiellement plus performantes.
Ensuite, leur stratégie d’exploration repose souvent sur une réécriture complète du code à chaque itération. Ce fonctionnement les empêche de concentrer leurs efforts sur des composants spécifiques du pipeline, par exemple, tester de manière systématique différentes options d’ingénierie des caractéristiques, avant de passer à d’autres étapes.
Ensuite, leur stratégie d’exploration repose souvent sur une réécriture complète du code à chaque itération. Ce fonctionnement les empêche de concentrer leurs efforts sur des composants spécifiques du pipeline, par exemple, tester de manière systématique différentes options d’ingénierie des caractéristiques, avant de passer à d’autres étapes.
Pour dépasser ces limites, les chercheurs de Google ont conçu MLE-STAR, un agent qui combine trois leviers :
-
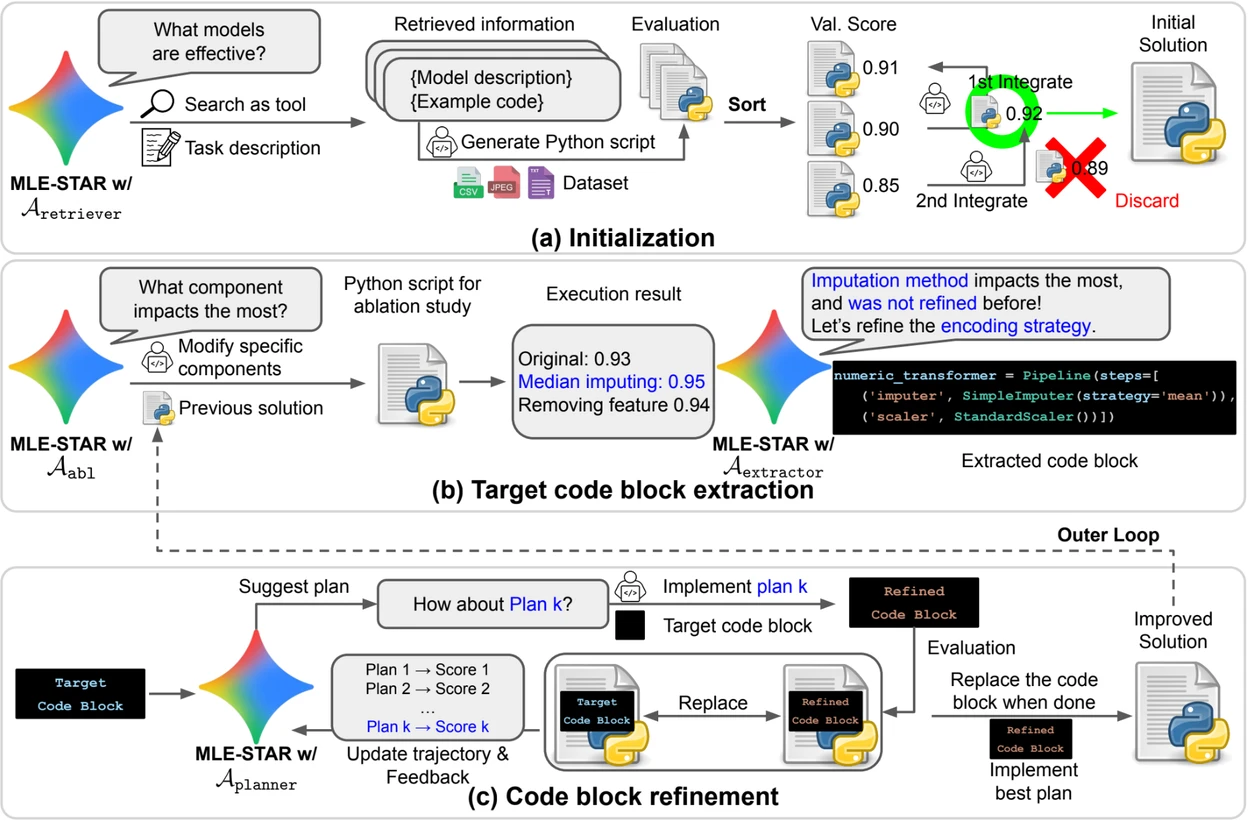
Recherche web pour identifier des modèles spécifiques à la tâche et constituer une solution initiale solide ;
-
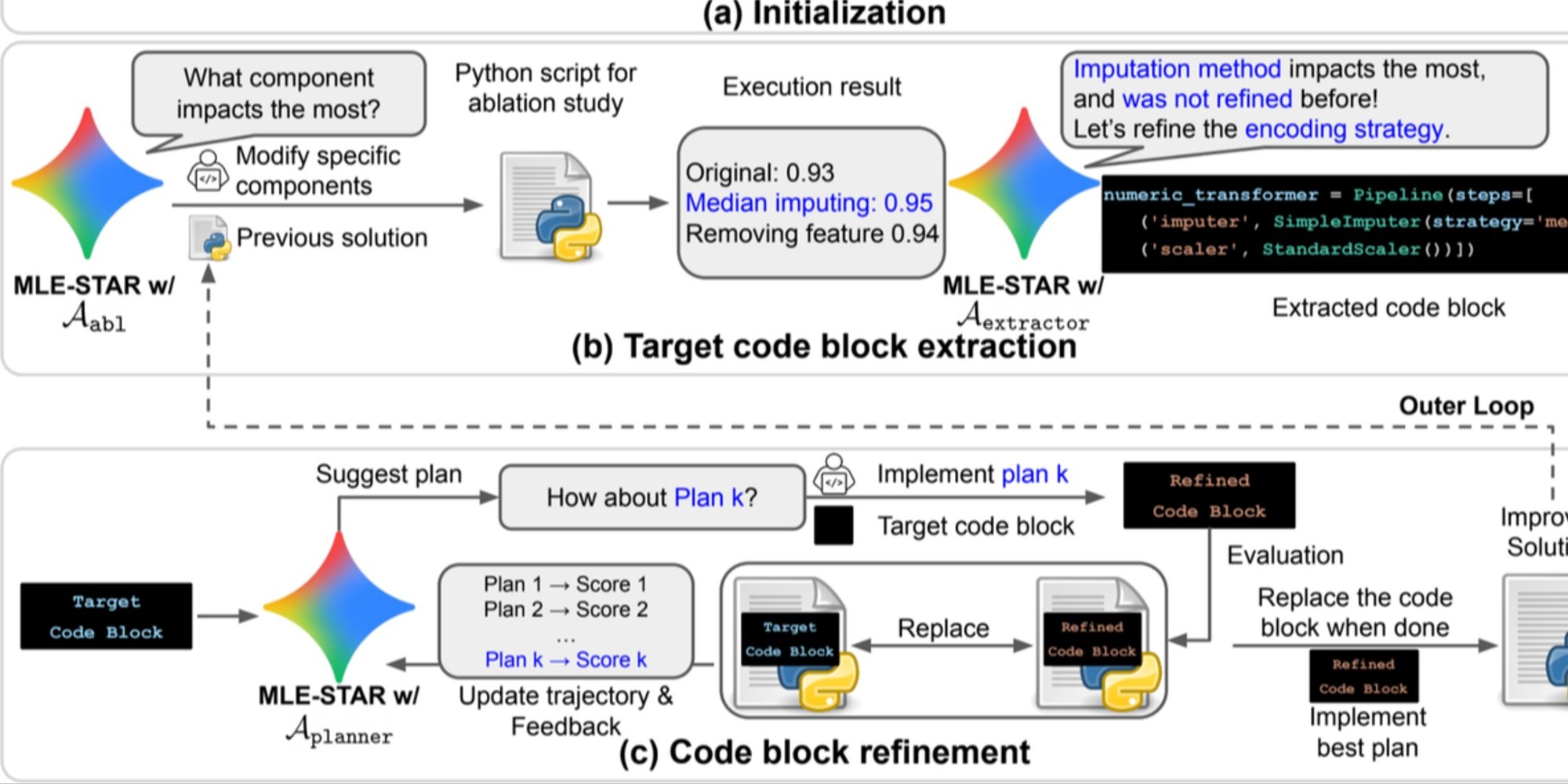
Raffinement granulaire par blocs de code, en s’appuyant sur des études d’ablation pour repérer les parties ayant le plus d’impact sur les performances, puis en les optimisant itérativement ;
-
Stratégie d’assemblage adaptative, capable de fusionner plusieurs solutions candidates en une version améliorée, affinée au fil des tentatives.
Ce processus itératif, recherche, identification du bloc critique, optimisation, puis nouvelle itération, permet à MLE-STAR de concentrer ses efforts là où ils produisent le plus de gains mesurables.
Crédit : Google Research.
Aperçu. a) MLE-STAR commence par utiliser la recherche sur le Web pour trouver et incorporer des modèles spécifiques à une tâche dans une solution initiale. (b) Pour chaque étape de raffinement, il effectue une étude d’ablation afin de déterminer le bloc de code ayant l’impact le plus significatif sur les performances. (c) Le bloc de code identifié subit ensuite un raffinement itératif basé sur les plans suggérés par LLM, qui explorent diverses stratégies en utilisant les commentaires des expériences précédentes. Ce processus de sélection et d’affinement des blocs de code cible se répète, où la solution améliorée de (c) devient le point de départ de l’étape de raffinement suivante (b).
Des modules de contrôle pour fiabiliser les solutions
Au-delà de son approche itérative, MLE-STAR intègre trois modules destinés à renforcer la robustesse des solutions générées :
-
Un agent de débogage pour analyser les erreurs d’exécution (par exemple, une traceback Python) et proposer des corrections automatiques ;
-
Un vérificateur de fuite de données pour détecter les situations où des informations issues des données de test sont utilisées à tort lors de l’entraînement, un biais qui fausse les performances mesurées ;
-
Un vérificateur d’utilisation des données pour assurer que toutes les sources de données fournies sont exploitées, même lorsqu’elles ne se présentent pas sous des formats standard comme le CSV.
Ces modules répondent à des problèmes courants observés dans le code généré par des LLMs.
Des résultats significatifs sur Kaggle
Pour évaluer l’efficacité de MLE-STAR, les chercheurs l’ont testé dans le cadre du benchmark MLE-Bench-Lite, fondé sur des compétitions Kaggle. Le protocole mesurait la capacité d’un agent à produire, à partir d’une simple description de tâche, une solution complète et compétitive.
Les résultats montrent que MLE-STAR obtient une médaille dans 63 % des compétitions, dont 36 % en or, contre 25,8 % à 36,6 % pour les meilleures approches précédentes. Ce gain est attribué à la combinaison de plusieurs facteurs : l’adoption rapide de modèles récents comme EfficientNet ou ViT, la capacité à intégrer des modèles non identifiés par la recherche web grâce à une intervention humaine ponctuelle, et les corrections automatiques apportées par les vérificateurs de fuites et d’utilisation des données.
Retrouver le papier scientifique sur arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
Le code open source est disponible sur GitHub