

Hello !
Si vous avez envie de faire du machine learning avec du texte mais ne savez pas par où commencer, ce tutoriel est fait pour vous 😉 Le traitement automatique du langage naturel (ou NLP pour Natural Language Processing) est une branche à part entière de l’IA qui permet de réaliser plusieurs tâches :
- Traduction de texte
- Résumé automatique de texte
- Analyse de sentiment
- Reconnaissance d’entités nommées (ex : nom propre ou lieu)
Et bien d’autres encore. A l’heure des assistants vocaux et des smartphones de plus en plus puissants le NLP est au cœur de nombreuses problématiques. Le Deep Learning a révolutionné le domaine en aidant l’algorithme à prendre en compte le contexte notamment.
Je vous propose ici de découvrir quelques étapes importantes lorsque l’on traite des données textuelles, avec en trame de fond une tâche de classification.
Le but de ce tutoriel est de déterminer si un texte est considéré comme un spam ou non. Pour cela, nous utiliserons un dataset composé de 1956 commentaires labellisés (spam : 1, ham : 0) en provenance de 5 vidéos YouTube populaires en 2012. Les données sont disponibles ici.
Nous utiliserons python et les librairies scikit-learn (fournie avec anaconda) et NLTK (Natural Language Toolkit) que vous pouvez installer avec la commande conda install -c anaconda nltk sur anaconda prompt.
Si vous n’avez pas Anaconda, vous pouvez le télécharger via ce lien, ce que je vous conseille tant Jupyter notebook est pratique en Data Science.
Première étape : Importer les données
Dans un premier temps, ouvrez un notebook et importez les librairies suivantes. Nous allons voir au fur et à mesure quoi utiliser 😉
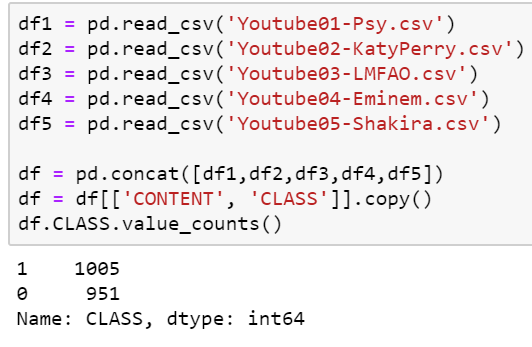
Il est temps de charger les données ! Puisque nous n’avons que 5 fichiers csv, nous allons les charger un par un dans un dataframe, puis les concaténer et enfin ne garder que les deux colonnes qui nous intéressent, à savoir CONTENT, le commentaire, et CLASS qui est le label associé. Nous pouvons voir que nous avons un nombre presque similaire de chacune des classes, ce qui est toujours une bonne chose pour une tâche de classification puisqu’il n’y a pas de classe biaisée.
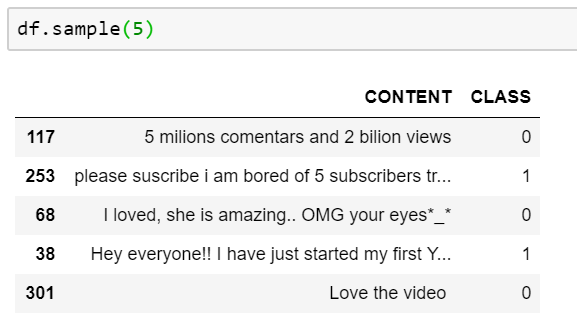
Voyons à quoi ressemblent quelques commentaires pris au hasard.
Avant de passer à la phase de classification, il faut nettoyer le texte ! Cette phase, appelée preprocessing en anglais, est essentielle et sur elle repose 80% de la réussite de tel ou tel algorithme.
Preprocessing des données
Le preprocessing comporte plusieurs étapes souvent complémentaires. Nous allons ici découvrir les plus courantes, à savoir :
- Normalisation du texte
- Tokénization
- Suppression des stopwords
- Lemmatization (ou Stemming)
- N-grams
Normalisation
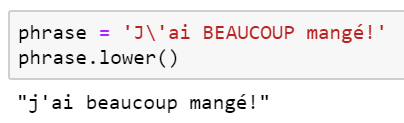
Normaliser le texte signifie le mettre à la même casse, souvent tout en minuscule.
Tokénization
Passons à la Tokénization ! C’est un procédé très simple qui divise une chaîne de caractère en tokens, c’est-à-dire des éléments atomiques de la chaîne. Un token n’est pas forcément un mot, ce peut être par exemple un signe de ponctuation. NLTK fournit plusieurs types de tokénization, comme la tokénization par mot ou par phrase. En effet, si on considère que la fin d’une phrase correspond à un point puis un espace puis une majuscule, nous aurions du mal avec les acronymes ou les titres (Dr. Intel). Ce que NLTK propose, ce sont donc des tokenizers déjà entraînés sur un set de documents (ou corpus). Dans notre cas, nous n’avons besoin que du tokenizer de mots :

Suppression des stop words
Vient ensuite l’étape de suppression des stopwords qui est cruciale, car elle va enlever dans le texte tous les mots qui n’ont que peu d’intérêt sémantique. Les stopwords sont en effet tous les mots les plus courants d’une langue (déterminants, pronoms, etc..). NLTK dispose d’une liste de stopwords en anglais (ou dans d’autres langues).

stopW est maintenant une liste, il est donc facile d’y rajouter certains mots en fonction de la tâche. Par exemple, si on dispose de reviews de problèmes sur un modèle de téléphone, il peut être utile d’enlever le mot « téléphone » tant celui-ci sera présent. Il est maintenant simple d’enlever les stop words d’une liste de tokens avec une compréhension de liste.

Stemming et Lemmatization
Ces deux méthodes sont très couramment utilisées dans le traitement du langage naturel car permettent de représenter sous un même mot plusieurs dérivées du mot. Dans le cas du Stemming, nous allons uniquement garder le radical du mot (ex : dormir, dortoir et dors deviendront dor). La lemmatization, moins radicale 😉, va laisser au mot un sens sémantique mais va éliminer le genre ou le pluriel par exemple.

Par défaut, le lemmatizer de NLTK fait effet sur les noms, maison peut lui spécifier d’autres PoS (pour Part-of-Speech) comme le verbe ou l’adjectif, et l’employer dans une composition de fonction comme suit.

Nous pouvons maintenant appliquer en un coup la lemmatization et la normalisation à notre dataframe. Ici, nous appliquons la tokénization dans le but de faire la lemmatization, mais nous rejoignons les tokens (avec la fonction join) car nous allons ici avoir besoin de cette forme plus tard, tout dépend de l’application.

Dans la pratique, le Stemming est employé surtout pour effectuer des recherches sur un grand nombre de document (ex : moteur de recherche), pour le reste, la lemmatization est souvent préférée.
Ces méthodes sont employées pour deux raisons :
- Donner le même sens à des mots très proches mais d’un genre différent (ou éliminer le pluriel, etc…)
- Réduire la sparsité des matrices utilisées dans les algorithmes (voir partie suivante sur TFIDF)
N-grams
Les n-grams sont tous simplement des suites de mots présents dans le texte. Ce que nous traitions jusqu’à présent étaient uniquement des unigrammes, nous pouvons ensuite rajouter des bigrammes ou même des trigrammes. Un bigramme est un couple de mot qui se suivent dans le texte, nous pouvons les trouver facilement grâce à NLTK :
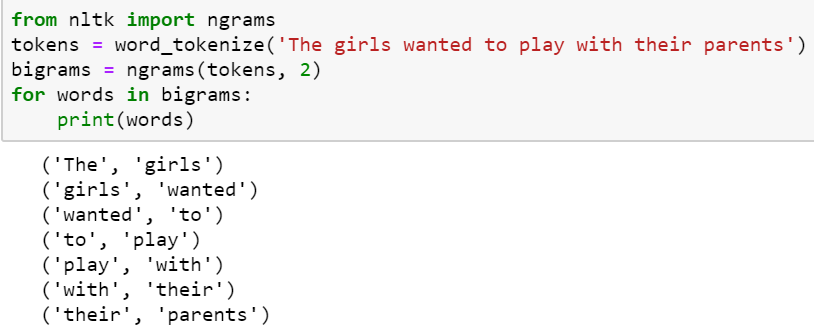
Si l’intérêt des bigrammes ne saute pas aux yeux, considérez le cas suivant : « I want to go the White House » Les unigrammes ne détecteront pas la co-occurrence des termes « White » et « House » tandis que l’usage des bigrammes le ferait ressortir comme un seul et même terme. En effet, après le bout de code montré au-dessus, il convient de sélectionner uniquement les bigrammes qui co-occurent un nombre minimum de fois. La librairie Gensim le fait très simplement mais nous allons réserver cela à un autre tutoriel.
Classification
Vous le savez peut-être mais les algorithmes n’aiment pas les mots… Heureusement pour nous, il existe des méthodes simples permettant de convertir un document en une matrice de mot. Ces matrices étant souvent creuses (sparse en anglais), c’est-à-dire pleines de 0 avec peu de valeurs, la lemmatization aide à réduire leurs tailles. Afin de convertir ces phrases en matrice, nous allons voir une méthode que l’on appelle TFIDF (Term Frequency – Inverse Document Frequency).
TFIDF
TFIDF est une approche bag-of-words (bow) permettant de représenter les mots d’un document à l’aide d’une matrice de nombres. Le terme bow signifie que l’ordre des mots dans la phrase n’est pas pris en compte, contrairement à des approches plus poussées de Deep Learning (word embeddings : word2vec, GLoVE). Néanmoins, TFIDF est une méthode efficace utilisée dans de nombreux outils de querying puisqu’elle donne de l’importance aux mots qui apparaissent de temps en temps mais pas trop, tout en en limitant l’importance des mots qui apparaissent souvent.
TFIDF est composé de ces deux termes : ![]()
Avec la fréquence du terme dans un document (dans notre cas un commentaire). étant le nombre de fois où le terme apparaît dans le document et le nombre de mots du document.
Plus tf est élevé, plus le mot a de l’importance. Il nous reste à calculer IDF :
![]()
Ou n est le nombre de documents et t∈d le nombre de documents où le terme est présent.
Nous avons enfin tƒidƒ(t)=tƒ(t) x idƒ(t) pour un document en particulier.
C’est un bon exercice de reproduire cet algorithme from scratch en python. Comme souvent, il est présent sur plusieurs librairies, notamment scikit-learn. En plus de cela, le tfidf vectorizer de scikit-learn nous permet directement de spécifier les stop words que l’on souhaite, mais aussi le nombre de N-grams que l’on souhaite prendre en compte, ainsi que plusieurs autres paramètres. Dans notre cas, nous allons ajouter les bigrammes et également prendre en compte les stopwords.
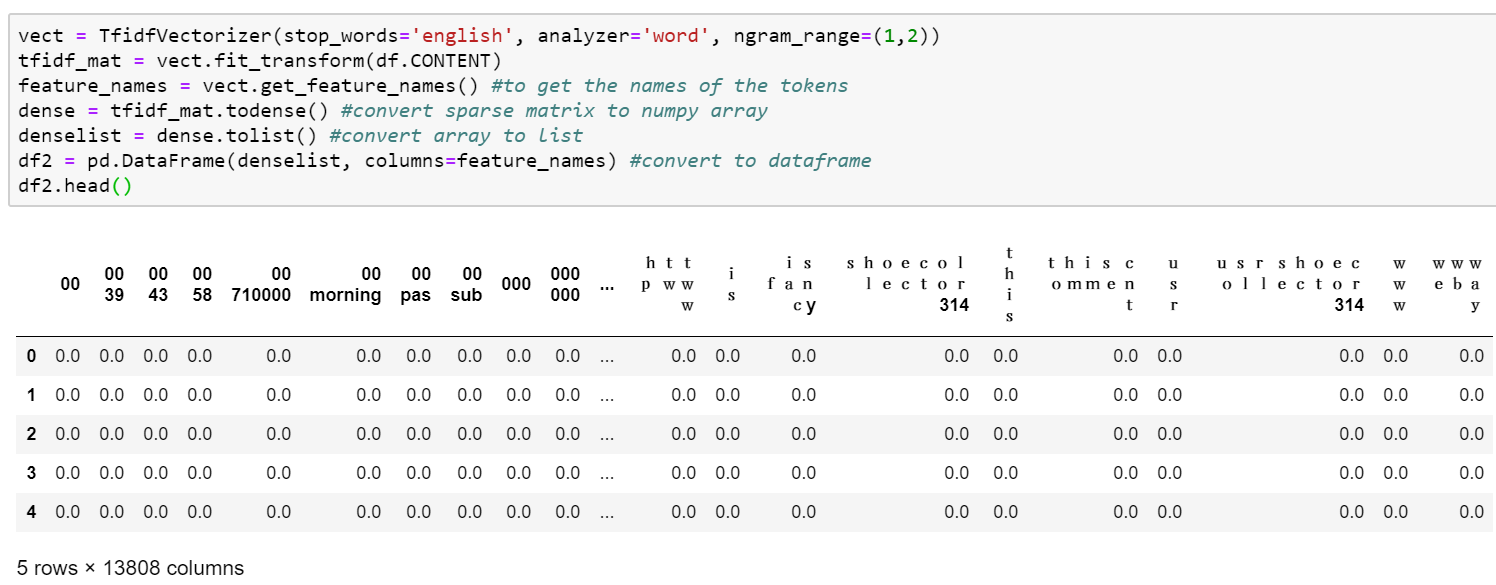
La matrice que nous récupérons comporte quand même 13808 colonnes (et le même nombre de lignes qu’au départ, soit 1956) ! Comme vous pouvez le constater, nous ne voyons ici que des zéros, ce qui est normal puisque sur ces 13808 tokens, seuls quelques-uns sont présent dans chaque commentaire.
Support Vector Machine
Une machine à vecteurs de support (SVM) est un algorithme permettant de réaliser des tâches de classification ou de régression, très en vogue il y a quelques années mais depuis largement surpassé par les réseaux de neurones profonds. Néanmoins, il fonctionne bien sur des données textuelles. Son principe est de séparer au maximum les exemples tirés des différentes classes, on le qualifie de hard margin classifier comme vous pourrez le voir sur l’exemple suivant.
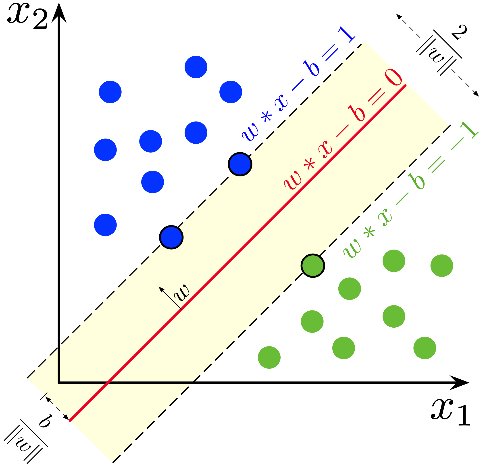
Si vous voulez découvrir comment cet algorithme fonctionne, je vous invite à consulter ce lien (bases en maths requises).
Avant de tester le modèle, nous allons séparer nos données en un jeu d’entraînement et un jeu de test, afin d’évaluer la qualité de notre modèle, puis nous pouvons directement entraîner le modèle et effectuer des prédictions sur le jeu de test. Avec un score F1 assez élevé et une matrice de confusion concluante, nous pouvons voir que nos résultats sont bons.
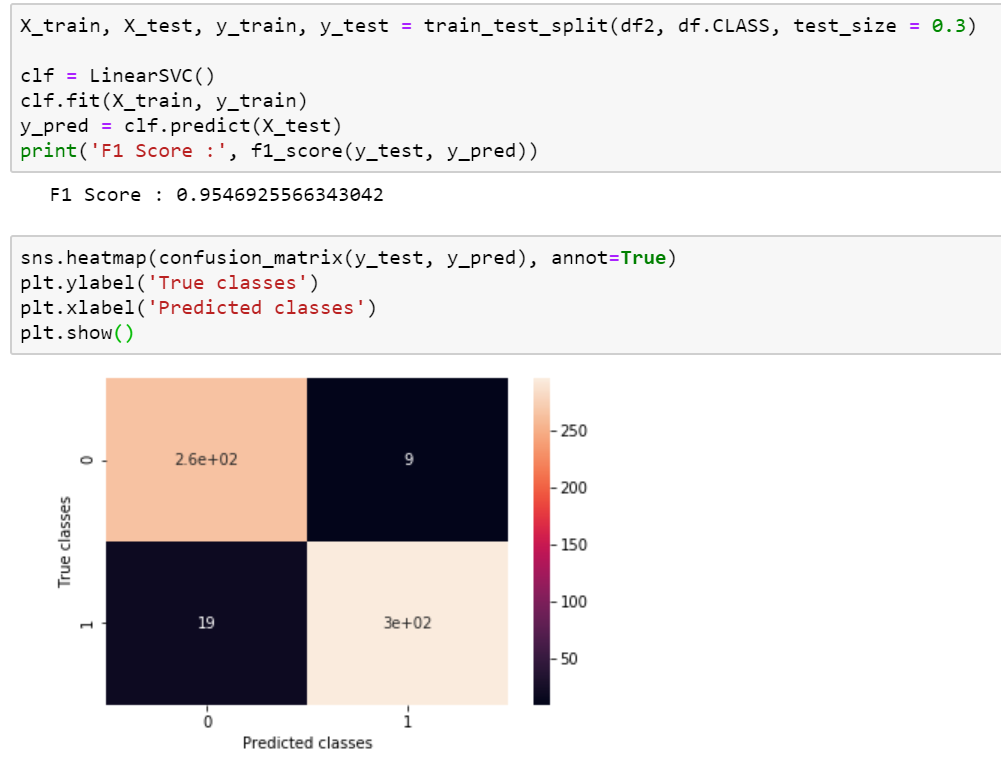
Pour rappel, une matrice de classification nous renseigne sur le nombre de spam/ham correctement classés ou bien sur ceux qui ont été mal classés.
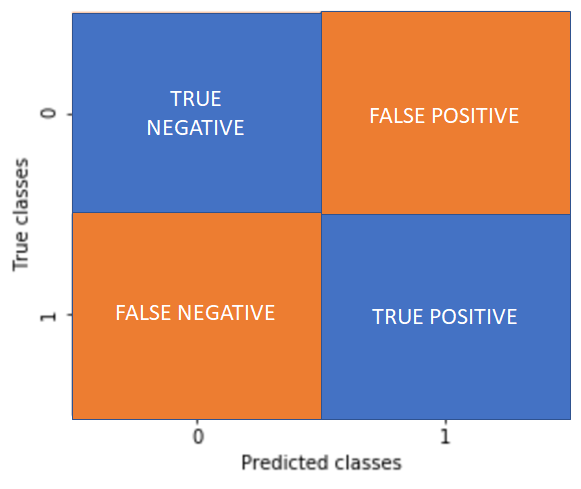
Le score F1 est une métrique très utile dans les tâches de classification, nous indiquant à la fois la précision et le recall du modèle, qui se calculent grâce à la matrice de confusion ci-dessus et dont vous pourrez trouver le détail sur wikipédia 😉
C’est tout pour ce tutoriel ! Si vous avez des commentaires n’hésitez pas, je compte poursuivre ce tutoriel par un autre montrant comment déterminer des topics ou mots-clés dans un ensemble de documents.
Source image :
https://commons.wikimedia.org/wiki/File:SVM_margin.png









