
Mardi dernier, Mistral AI a annoncé le lancement de Voxtral, sa première famille de modèles audio open source. Conçus pour des usages professionnels, ces modèles de compréhension de la parole marquent l’entrée de la licorne française sur le segment stratégique de l’intelligence vocale, un domaine jusqu’ici dominé par des acteurs comme OpenAI, Meta et Google.
La gamme Voxtral se décline en deux modèles principaux : Voxtral Small (24 milliards de paramètres) et Voxtral Mini (3 milliards de paramètres), chacun destiné à des environnements distincts. Le modèle Small se positionne sur des cas d’usage complexes et un déploiement cloud à grande échelle tandis que la version Mini vise les déploiements embarqués ou à ressources limitées. Mistral AI propose également Voxtral Mini Transcribe, une version optimisée uniquement pour la transcription vocale, avec un rapport qualité/prix supérieur à celui de modèles comme Whisper.
Des fonctionnalités qui vont au-delà de la transcription
Voxtral se veut une alternative aux systèmes ASR (reconnaissance automatique de la parole) peu fiables et aux API fermées et propriétaires coûteuses.
Conçu pour traiter de longs contextes audio, il peut gérer jusqu’à 30 minutes de transcription ou 40 minutes de compréhension, grâce à une fenêtre de 32 000 tokens.
S’appuyant sur l’architecture du modèle linguistique Mistral Small 3.1, il peut répondre à des requêtes orales, générer des résumés à partir de fichiers audio ou transformer une intention exprimée oralement en appel API ou en flux backend. Le modèle prend en charge les langues les plus utilisées notamment l'anglais, l'espagnol, l'arabe, le français, le portugais, l'hindi, l'allemand, le néerlandais et l'italien.
Des performances de pointe
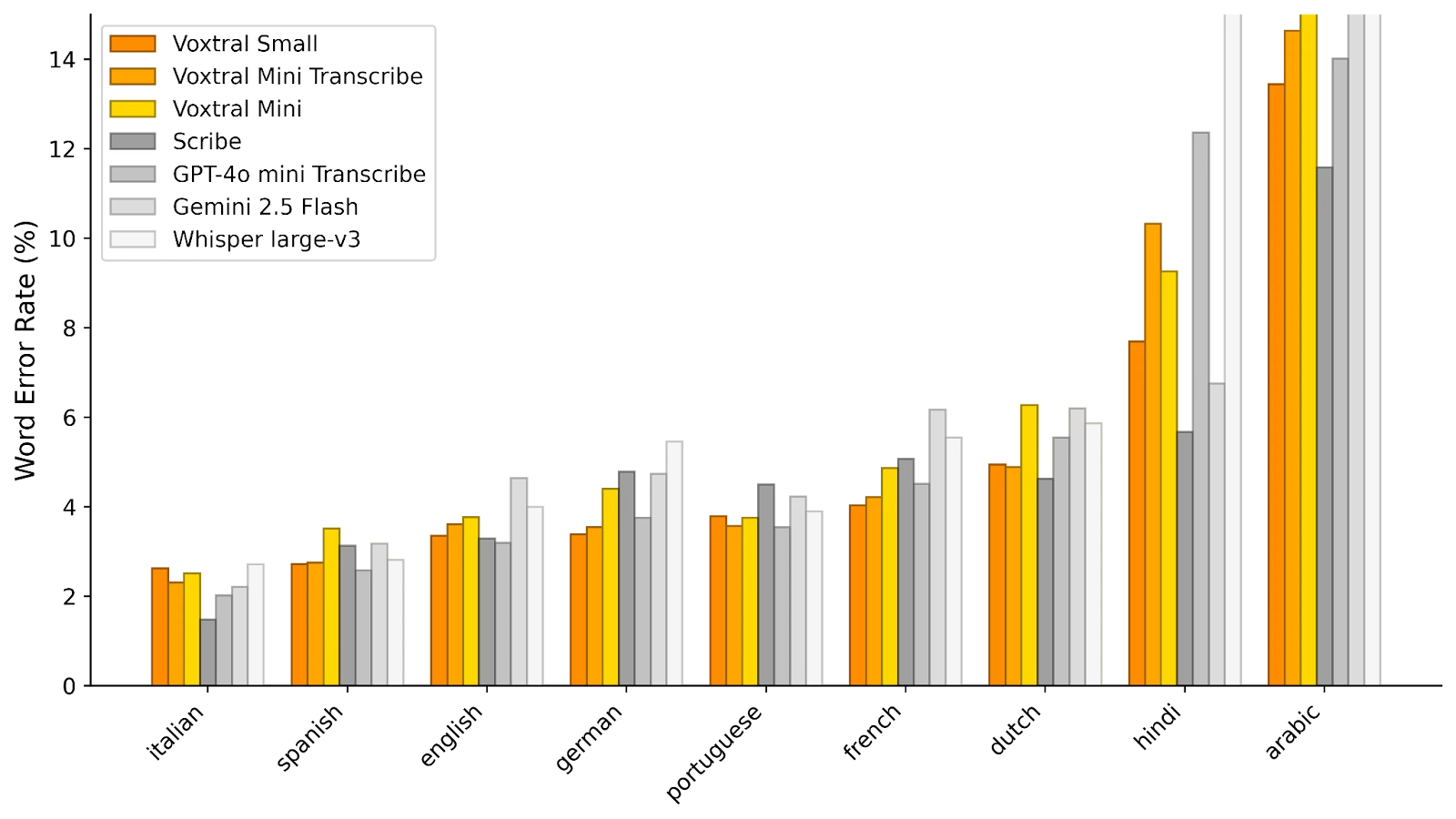
D’après les premières évaluations communiquées par Mistral, Voxtral Small surpasse le modèle de référence Whisper v3, mais également Gemini 2.5 Flash et GPT-4o Mini Transcribe d'Open AI sur plusieurs métriques de transcription automatique, tout en affichant une consommation de ressources maîtrisée.
Dans FLEURS (ci-dessous), Voxtral Small affiche des performances de pointe dans toutes les langues testées, avec une précision supérieure à Whisper.
Disponibilité
Les deux modèles, distribués sous licence Apache 2.0, sont disponibles en téléchargement sur Hugging Face. Voxtral est également accessible via API dès 0,001 $/minute pour ceux qui désirent l'intégrer à leur application, soit moins de la moitié du coût des offres concurrentes, et viendra d'ici peu enrichir l'assistant conversationnel de Mistral AI, Le Chat.
Pour les contextes métiers spécifiques, les entreprises peuvent opter pour des déploiements privés et sécurisés, notamment dans les domaines juridiques ou médicaux.
Mistral AI prévoit de lui apporter dans les mois à venir de nouvelles fonctionnalités comme la segmentation audio, la diarisation (identification des différents locuteurs) ou la détection des émotions.
Une dynamique de marché en expansion
Ce lancement intervient alors que les solutions de transcription et d’analyse audio sont en forte demande, avec une accélération des cas d’usage dans le support client, l’analyse d’interactions, la documentation automatisée ou l’assistance vocale. Voxtral vient s'insérer dans un espace déjà occupé par des initiatives comme Whisper (OpenAI, MIT), SeamlessM4T (Meta, non commercial), ou des frameworks comme NVIDIA NeMo ou ESPnet.
Mais peu d’entre eux offrent, à ce jour, un accès libre, une compréhension sémantique intégrée et une capacité à déclencher des actions à partir de la voix, dans une seule et même solution.
Cet article publirédactionnel est publié dans le cadre d'une collaboration commerciale