
Meta AI Research a récemment dévoilé DINOv3, un modèle de vision par ordinateur entraîné par apprentissage auto-supervisé qui atteint des performances de pointe sur un large éventail de tâches visuelles, sans recourir à un entraînement spécifique pour chacune d'entre elles. Selon les chercheurs, c’est la première fois qu'une seule épine dorsale visuelle figée (frozen backbone) surpasse les solutions spécialisées sur plusieurs tâches de prédiction dense de longue date, notamment la détection d’objets et la segmentation sémantique.
Avec DINOv3, Meta propose un socle unique capable de fournir des représentations utiles directement, sans ajustement lourd. La même architecture peut donc alimenter une recherche d’images, une estimation de profondeur, ou une analyse pixel-par-pixel, simplement en ajoutant une tête légère adaptée.
La plus grande des variantes de DINOv2, présenté par Meta AI en avril 2023, ViT-Giant (ViT-G/14) comptait 1 milliard de paramètres. DINOv3 compte, quant à lui,7 milliards de paramètres entraînés sur 1,7 milliard d’images soigneusement sélectionnées, incluant ImageNet, Mapillary et des données web.
Alors que la mise à l'échelle des modèles auto-supervisés entraîne une dégradation des cartes de caractéristiques denses, nuisant à la cohérence géométrique et à la précision des tâches fines, Meta Research a introduit divers mécanismes pour répondre à ces défis.
Le Gram Anchoring, par exemple, vise à préserver la cohérence locale des images au cours d’un entraînement prolongé, un problème souvent négligé mais décisif pour la qualité des représentations denses. De même, l’usage d’Axial RoPE avec jittering accroît la robustesse face aux variations de résolution ou de proportions d’image, rapprochant le modèle d’un usage plus concret en environnement varié.
Performances du modèle
DINOv3 égale, voire dépasse, les performances des modèles faiblement supervisés ou supervisés les plus récents tels que SigLIP 2, une variante de CLIP optimisée pour la classification d’images, la recherche visuelle et les tâches zero-shot.et Perception Encoder, un modèle multimodal utilisé dans des systèmes comme Gemini ou GPT-4V, sur de nombreux benchmarks de classification d’images, tout en creusant fortement l’écart dans les tâches de prédiction dense.
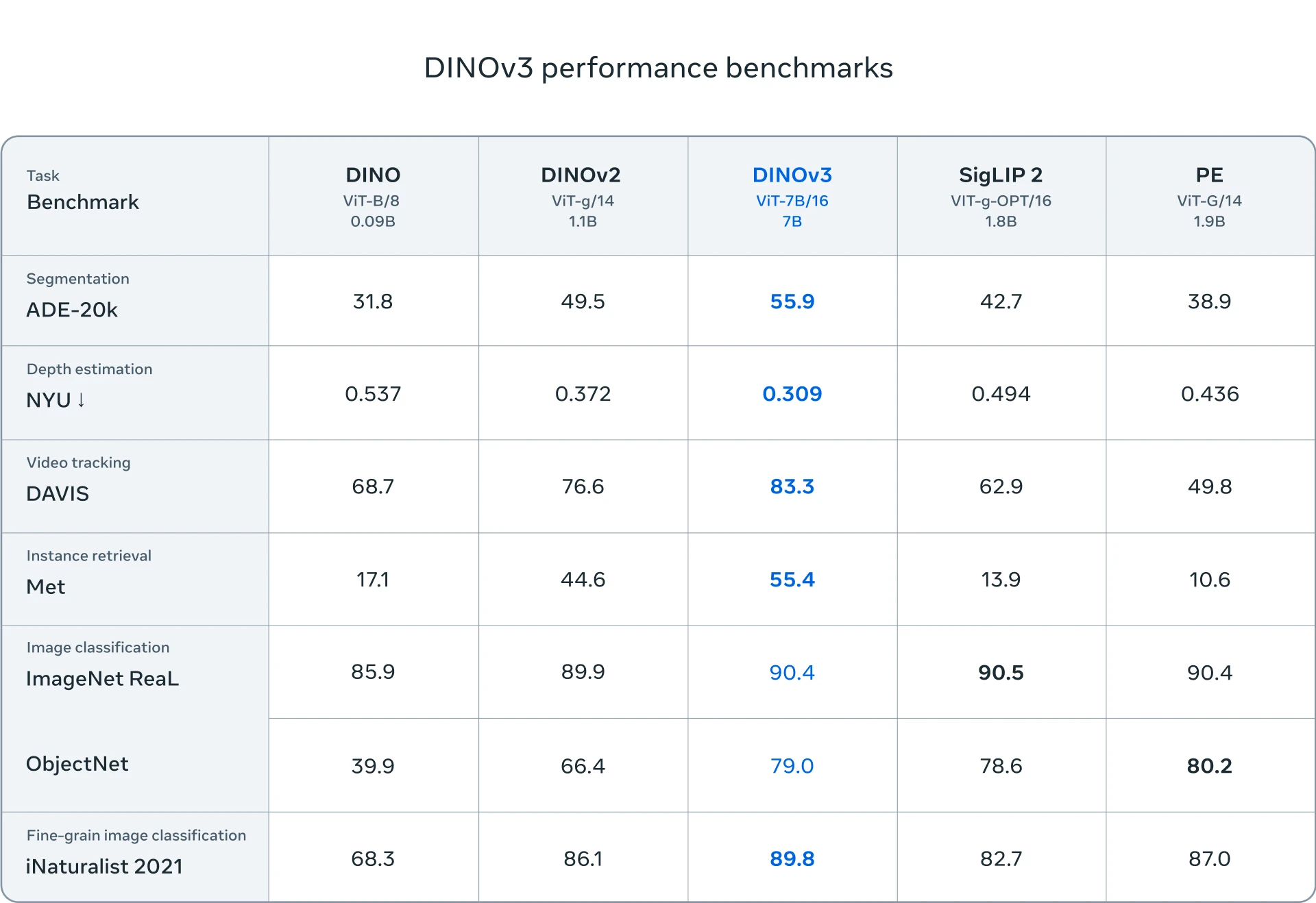
Meta propose également des variantes plus compactes, obtenues par distillation du modèle. On retrouve ainsi des versions ViT-B et ViT-L, ainsi que des architectures ConvNeXt (T, S, B, L), pensées pour s’adapter à des contraintes de calcul variées. Ces déclinaisons conservent une large part des performances de DINOv3, tout en rendant son usage accessible à un éventail plus large de chercheurs et de développeurs.
Applications concrètes
DINOv3 ouvre la voie à une large gamme d’usages dans des contextes où les données annotées sont rares ou coûteuses. Le World Resources Institute l’exploite pour analyser des images satellites et suivre la déforestation, tandis qu’Orakl Oncology s’appuie sur ses représentations pour prédire les réponses thérapeutiques à partir d’images d’organoïdes. Le Jet Propulsion Laboratory de la NASA, de son côté, l’intègre dans des systèmes de vision embarqués pour la robotique d’exploration.
Au-delà de ces cas concrets, sa polyvalence ouvre des perspectives dans la santé, les véhicules autonomes, la robotique, le commerce, la logistique ou encore l’industrie.
Meta met à disposition DINOv3 avec son code d’entraînement, ses modèles pré-entraînés et plusieurs têtes d’évaluation, le tout sous licence commerciale. Une version spécialisée, entraînée sur des images satellites MAXAR, est également proposée. Des notebooks d’exemples sont fournis pour faciliter la prise en main et l’expérimentation.