
Des chercheurs du département d’apprentissage automatique (MLD) et de l’Institut des technologies linguistiques (LTI) de l’Université Carnegie Mellon ont développé en un modèle de langage multimodal à grande échelle (MLLM) nommé Generating Images With Large Language Models (GILL). GILL est l’un des premiers modèles qui accepte à la fois des images et du texte en entrée, et peut superposer du texte et des images dans ses réponses.
Les chercheurs ont adapté un modèle de langage autoregressif (LLM) pré-entraîné sur du texte afin qu'il traite simultanément des entrées d’images et de texte, tout en produisant des sorties d’images et de texte. Dans cette approche, la majorité des poids du modèle, y compris ceux du générateur d’images, Stable Diffusion, sont maintenus figés. En revanche, un nombre restreint de paramètres est finement ajusté en utilisant des données de légendes d’images pour obtenir une diversité étendue de capacités.
La méthode s’articule autour de plusieurs étapes. Tout d’abord, le modèle doit apprendre à traiter le contenu image-et-texte, une étape essentielle dans son adaptation à une tâche multimodale. Ensuite, le modèle doit être capable de générer des images, qu’elles soient récupérées à partir d’une source existante ou nouvellement créées, et il doit prendre des décisions pour déterminer s’il doit produire du texte ou des images à chaque étape du processus.
Leurs résultats montrent qu’il est possible de mapper efficacement l’espace d’incorporation de sortie d’un modèle de langage pré-entraîné gelé spécifique au texte sur celui d’un modèle de génération text-to-image figé, bien que les deux modèles utilisent des encodeurs de texte entièrement différents.
Le modèle multimodal GILL peut ainsi traiter des entrées d’images et de texte entrelacées arbitrairement pour générer du texte, récupérer des images et générer de nouvelles images.
[caption id="attachment_54910" align="alignnone" width="696"]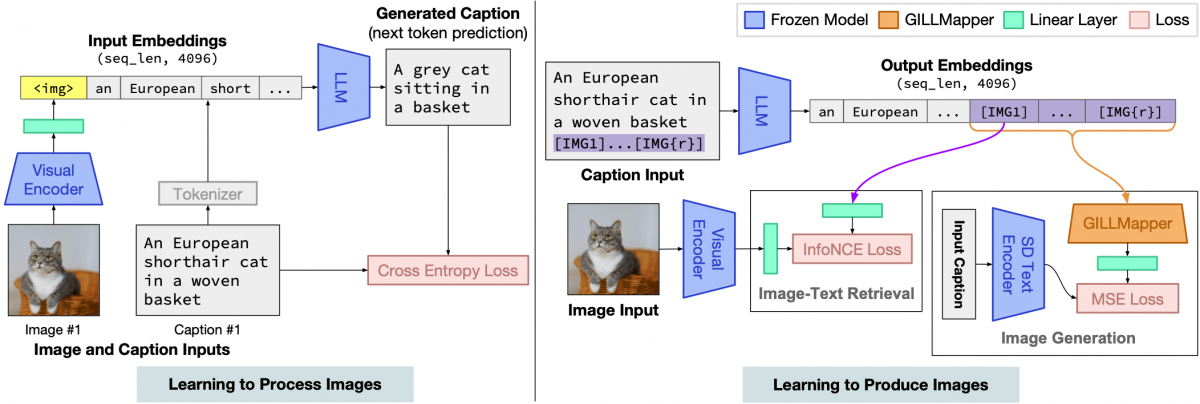 Aperçu de l’architecture du modèle GILL. Il est entraîné avec une perte de légende pour apprendre à traiter les images (à gauche), et avec des pertes pour la récupération d’image et la génération d’image pour apprendre à produire des images (à droite).[/caption]
Les chercheurs ont entraîné l’encodeur d’image ViT-L, dérivé de CLIP, à aligner ses embeddings avec ceux générés par le modèle texte-vers-image, et ce dernier à identifier les requêtes demandant une image, permettant ainsi au système de produire ou de récupérer des images.
Ils ont également construit un classificateur linéaire pour permettre au modèle GILL de déterminer quand une image devrait être récupérée ou générée. Pour l'entraîner, ils ont collecté des annotations humaines sur PartiPrompts P2, une collection de 1632 invites utilisée pour évaluer les modèles de génération d’images. Pour chacune d’entre elles, ils ont généré une image et récupéré l’image la plus similaire de CC3M, un ensemble de données composé de ~3,3 millions d’images annotées avec des légendes.
Cinq annotateurs humains ont ensuite sélectionné parmi ces 2 images, celle qui correspondait le mieux à l’invite.
[caption id="attachment_54912" align="alignnone" width="696"]
Aperçu de l’architecture du modèle GILL. Il est entraîné avec une perte de légende pour apprendre à traiter les images (à gauche), et avec des pertes pour la récupération d’image et la génération d’image pour apprendre à produire des images (à droite).[/caption]
Les chercheurs ont entraîné l’encodeur d’image ViT-L, dérivé de CLIP, à aligner ses embeddings avec ceux générés par le modèle texte-vers-image, et ce dernier à identifier les requêtes demandant une image, permettant ainsi au système de produire ou de récupérer des images.
Ils ont également construit un classificateur linéaire pour permettre au modèle GILL de déterminer quand une image devrait être récupérée ou générée. Pour l'entraîner, ils ont collecté des annotations humaines sur PartiPrompts P2, une collection de 1632 invites utilisée pour évaluer les modèles de génération d’images. Pour chacune d’entre elles, ils ont généré une image et récupéré l’image la plus similaire de CC3M, un ensemble de données composé de ~3,3 millions d’images annotées avec des légendes.
Cinq annotateurs humains ont ensuite sélectionné parmi ces 2 images, celle qui correspondait le mieux à l’invite.
[caption id="attachment_54912" align="alignnone" width="696"]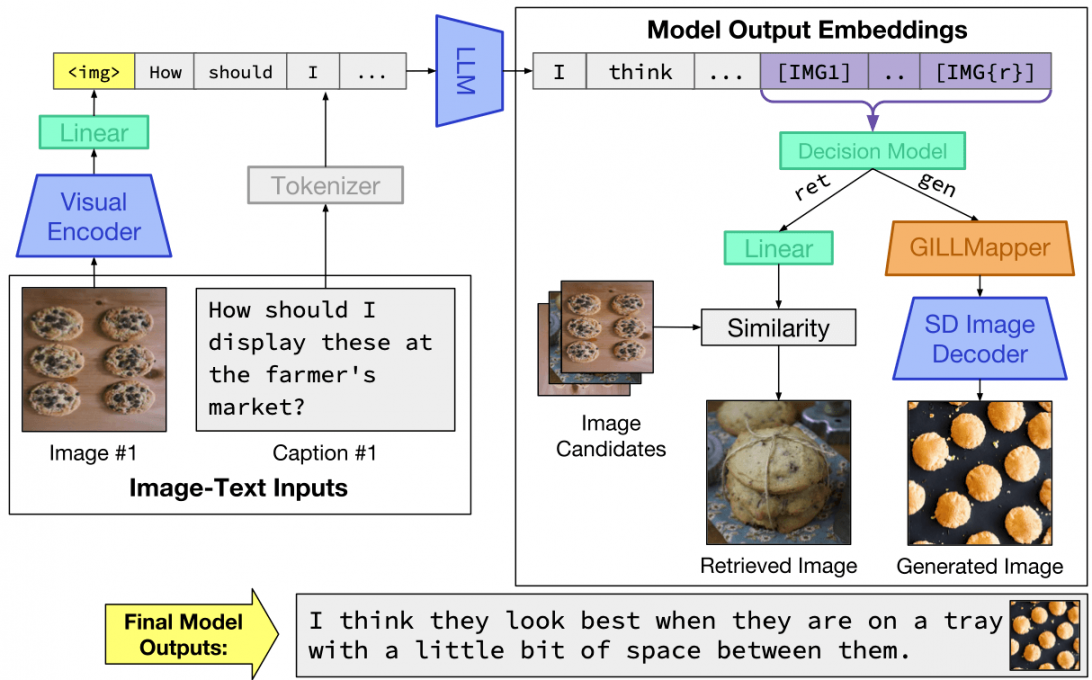 Lors de l’inférence, le modèle prend en compte les entrées d’image et de texte entrelacées arbitrairement et produit du texte entrelacé avec des plongements d’image. Après avoir décidé de récupérer ou de générer pour un ensemble particulier de jetons, il renvoie les sorties d’image appropriées (récupérées ou générées).[/caption]
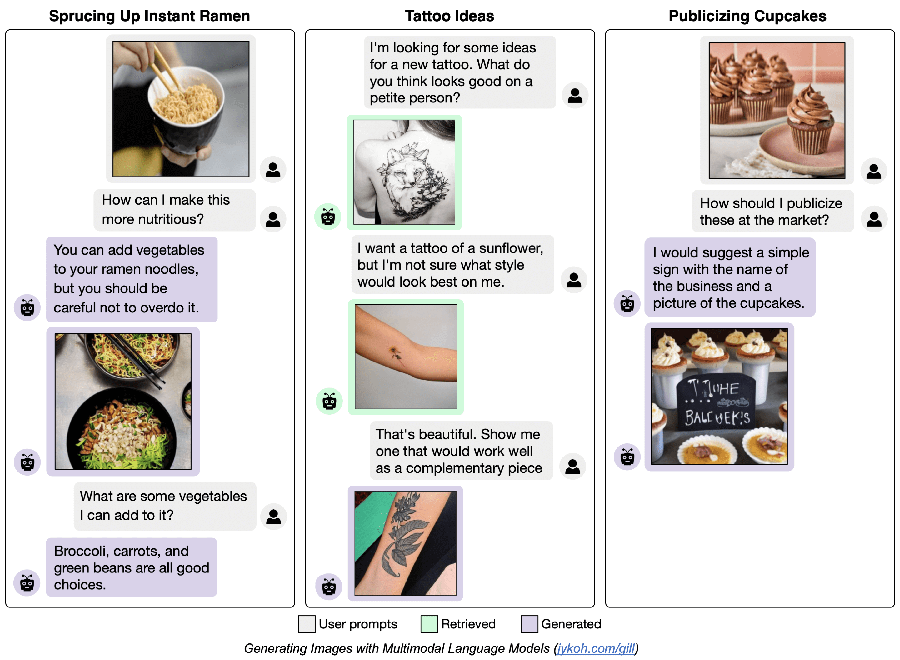
GILL peut être invité à générer du texte de type dialogue, comme ci-dessous :
Lors de l’inférence, le modèle prend en compte les entrées d’image et de texte entrelacées arbitrairement et produit du texte entrelacé avec des plongements d’image. Après avoir décidé de récupérer ou de générer pour un ensemble particulier de jetons, il renvoie les sorties d’image appropriées (récupérées ou générées).[/caption]
GILL peut être invité à générer du texte de type dialogue, comme ci-dessous :
Aperçu de l’architecture du modèle GILL. Il est entraîné avec une perte de légende pour apprendre à traiter les images (à gauche), et avec des pertes pour la récupération d’image et la génération d’image pour apprendre à produire des images (à droite).[/caption]
Les chercheurs ont entraîné l’encodeur d’image ViT-L, dérivé de CLIP, à aligner ses embeddings avec ceux générés par le modèle texte-vers-image, et ce dernier à identifier les requêtes demandant une image, permettant ainsi au système de produire ou de récupérer des images.
Ils ont également construit un classificateur linéaire pour permettre au modèle GILL de déterminer quand une image devrait être récupérée ou générée. Pour l'entraîner, ils ont collecté des annotations humaines sur PartiPrompts P2, une collection de 1632 invites utilisée pour évaluer les modèles de génération d’images. Pour chacune d’entre elles, ils ont généré une image et récupéré l’image la plus similaire de CC3M, un ensemble de données composé de ~3,3 millions d’images annotées avec des légendes.
Cinq annotateurs humains ont ensuite sélectionné parmi ces 2 images, celle qui correspondait le mieux à l’invite.
[caption id="attachment_54912" align="alignnone" width="696"] Lors de l’inférence, le modèle prend en compte les entrées d’image et de texte entrelacées arbitrairement et produit du texte entrelacé avec des plongements d’image. Après avoir décidé de récupérer ou de générer pour un ensemble particulier de jetons, il renvoie les sorties d’image appropriées (récupérées ou générées).[/caption]
GILL peut être invité à générer du texte de type dialogue, comme ci-dessous :
Limitations
Les chercheurs soulignent que malgré ses capacités intéressantes, GILL est un prototype de recherche précoce et présente plusieurs limites, notamment celles des LLM. Ils concluent toutefois :"Notre approche est modulaire et peut bénéficier de modèles de langage multimodaux ou visuels plus puissants qui seront publiés à l'avenir. L'extension de la dorsale du modèle de langage multimodal, de la dorsale de génération d'images ou du modèle de traitement visuel constitue des orientations prometteuses qui devraient probablement renforcer davantage les capacités vision-langage".
Références de l'article : Generating Images with Large Language Models class="arxivid">arXiv :2305.17216v3 Auteurs : Jing Yu Koh, Daniel Fried, Ruslan Salakhutdinov, Université Carnegie Mellon