La start-up américaine Anthropic, fondée en 2021 par d’anciens chercheurs d’OpenAI, a annoncé le lancement de son nouveau modèle Claude Sonnet 4.5, présenté comme une avancée majeure dans le domaine de la programmation assistée par IA.
Derrière les superlatifs de l’éditeur, il s’agit avant tout d’un jalon supplémentaire dans une compétition technologique de plus en plus rapide autour des agents capables de raisonner, coder et interagir directement avec des environnements logiciels complexes.
Un modèle pensé pour le développement et les agents logiciels
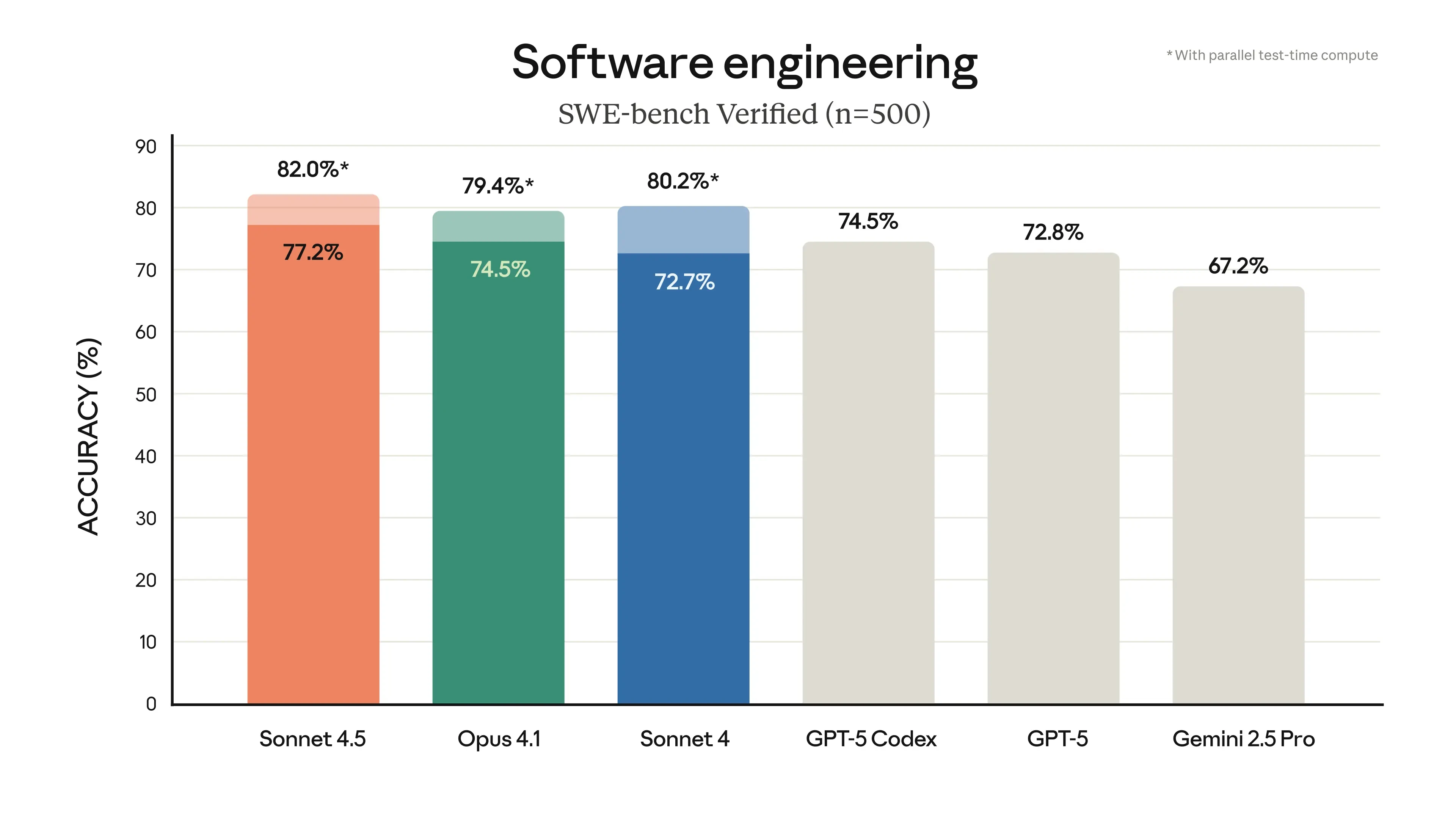
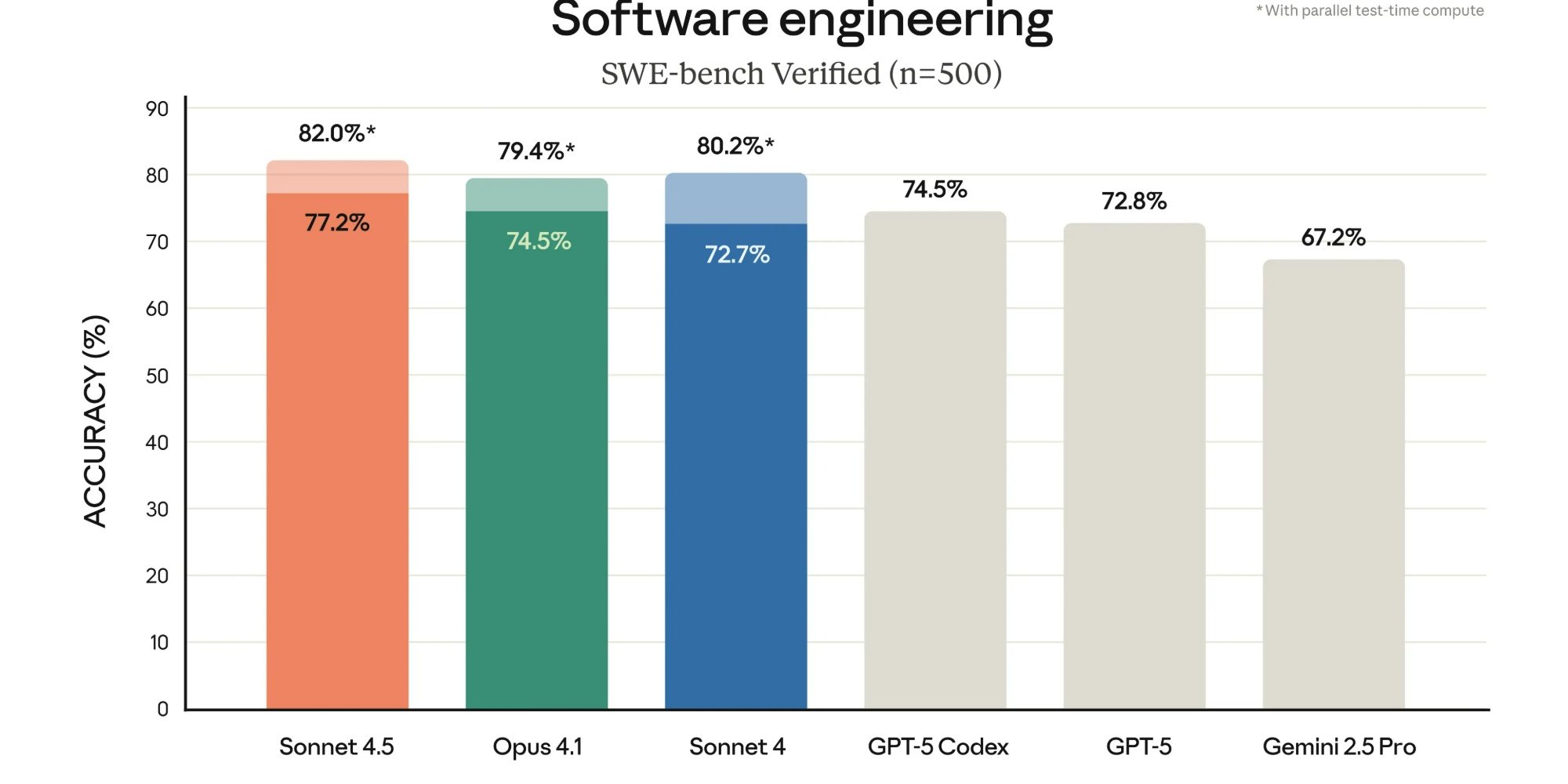
Claude Sonnet 4.5 est présenté comme « le meilleur modèle de programmation au monde ». Concrètement, Anthropic met en avant plusieurs points :
-
Des gains de performance sur le benchmark SWE-bench Verified, conçu pour évaluer la résolution de tâches de programmation réelles. Le modèle atteindrait désormais un niveau supérieur à 60 % de réussite, contre 42 % pour la version précédente sortie il y a quatre mois.
-
Une meilleure gestion des tâches longues et complexes, avec la possibilité de maintenir le fil d’un projet pendant plus de 30 heures.
-
Des capacités accrues d’interaction avec des environnements informatiques, comme la navigation web, la manipulation de feuilles de calcul ou l’édition de documents.
Ces évolutions s’accompagnent d’outils annexes : un SDK d’agents Claude (Agent SDK), qui permet aux développeurs de concevoir leurs propres agents basés sur les mêmes briques technologiques que celles utilisées pour « Claude Code », ainsi qu’un plugin pour VS Code et des fonctionnalités renforcées d’exécution de code et de création de fichiers au sein des applications Claude.
Une emphase sur la sécurité et l’alignement
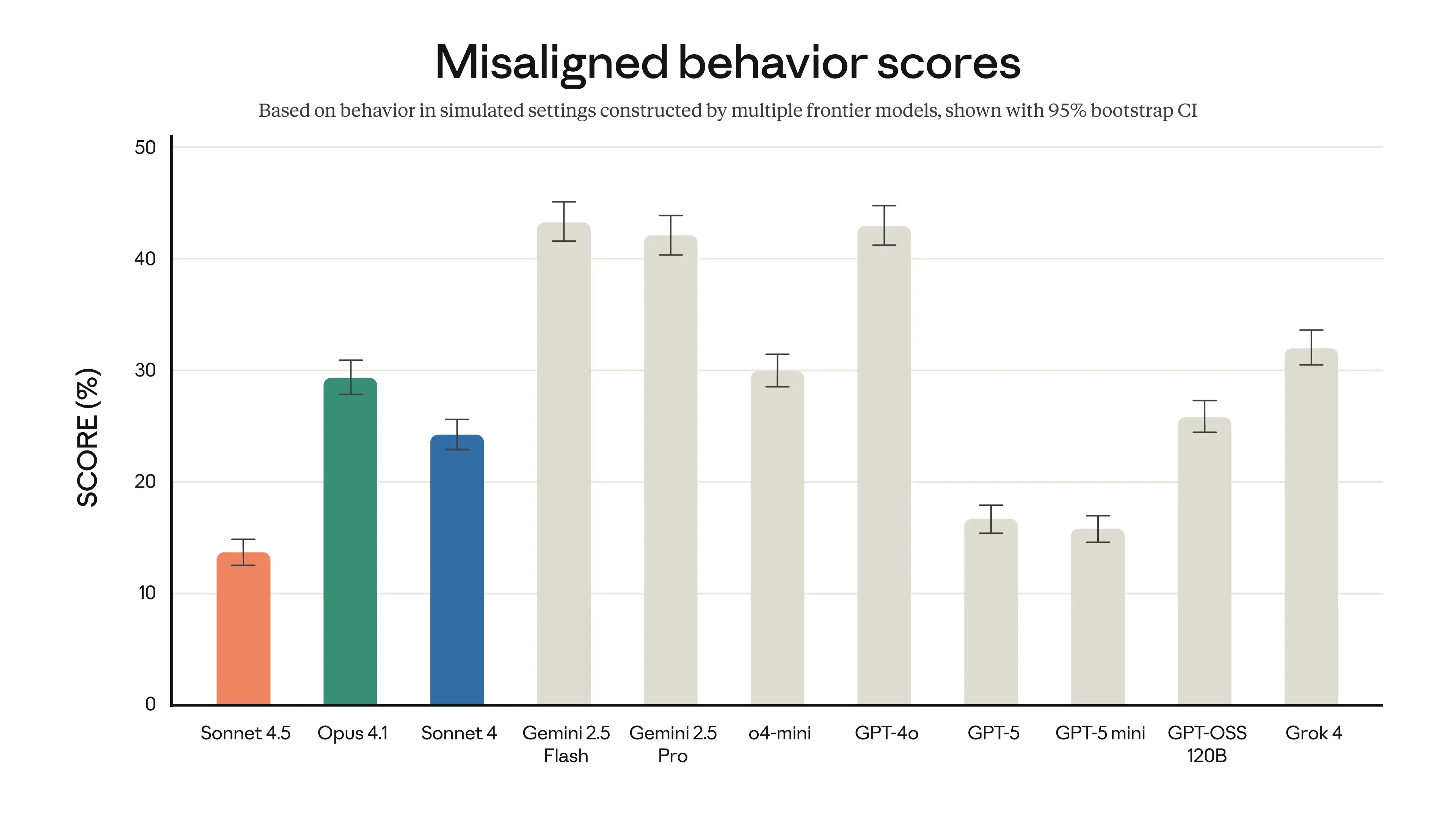
Anthropic insiste également sur l’aspect sécurité et alignement du modèle. Claude Sonnet 4.5 est déployé sous le label interne AI Safety Level 3 (ASL-3), avec des filtres renforcés visant à limiter les usages sensibles, notamment dans les domaines chimique, biologique, radiologique et nucléaire (CBRN).
La société affirme avoir réduit de manière significative les comportements jugés problématiques (complaisance, incitation à des raisonnements délirants, contournement de règles, etc.) grâce à un entraînement spécifique et à des techniques d’interprétabilité mécaniste.
Entre annonces techniques et contexte concurrentiel
L’annonce s’inscrit dans une dynamique concurrentielle intense. OpenAI, Google DeepMind et Anthropic multiplient les mises à jour rapprochées, chacune revendiquant des sauts de performance sur des benchmarks souvent difficiles à comparer entre eux.
Dans ce contexte, il est nécessaire de nuancer le discours :
-
Les benchmarks mettent en avant des écarts importants d’une version à l’autre, mais leur représentativité des usages réels reste débattue.
-
L’usage prolongé d’un modèle dans des environnements de production révèle souvent des limites moins visibles lors des démonstrations ou des évaluations internes.
-
Le développement de SDK et d’extensions suggère que les éditeurs cherchent à consolider un écosystème captif, où les entreprises utilisatrices seraient incitées à bâtir directement leurs workflows autour d’une plateforme donnée.
Perspectives
Claude Sonnet 4.5 marque une étape dans l’évolution rapide des modèles spécialisés dans le raisonnement appliqué et la programmation, avec une intégration de plus en plus poussée aux environnements de travail des développeurs.
Reste à savoir si ces avancées se traduiront, à moyen terme, par des gains mesurables de productivité et par une adoption durable dans les entreprises. Les avancées indéniables permises par l'IA au service du développement pouvant parfois être anéanties par une dette technique et sécuritaire.
La prudence reste de mise : si l’accélération du cycle d’innovation impressionne, la maturité de ces outils dans des contextes professionnels sensibles (finance, droit, santé, recherche scientifique) devra être évaluée au-delà des chiffres mis en avant par les éditeurs.