

Aujourd’hui, le modèle BERT est l’un des plus populaires et polyvalents dans le domaine de l’IA. Cependant, le fait qu’il implique des opérations denses signifie que la précision et la flexibilité qui le distinguent ne s’obtiennent qu’en contrepartie de coûts élevés en calcul.
En réponse à cela, Graphcore a participé au développement de GroupBERT, un nouveau modèle basé sur BERT qui s’appuie sur des transformations groupées, et qui s’est révélé parfaitement adapté à l’IPU, le microprocesseur dédié à l’intelligence artificielle
Le modèle GroupBERT combine une structure de type transformeur améliorée, des convolutions groupées et des multiplications de matrices. Il offre aux utilisateurs de nos IPU la possibilité de diviser par deux le nombre de paramètres au sein d’un modèle, ainsi que de réduire la durée d’apprentissage de 50 % tout en profitant du même niveau de précision.
Un meilleur BERT grâce aux IPU
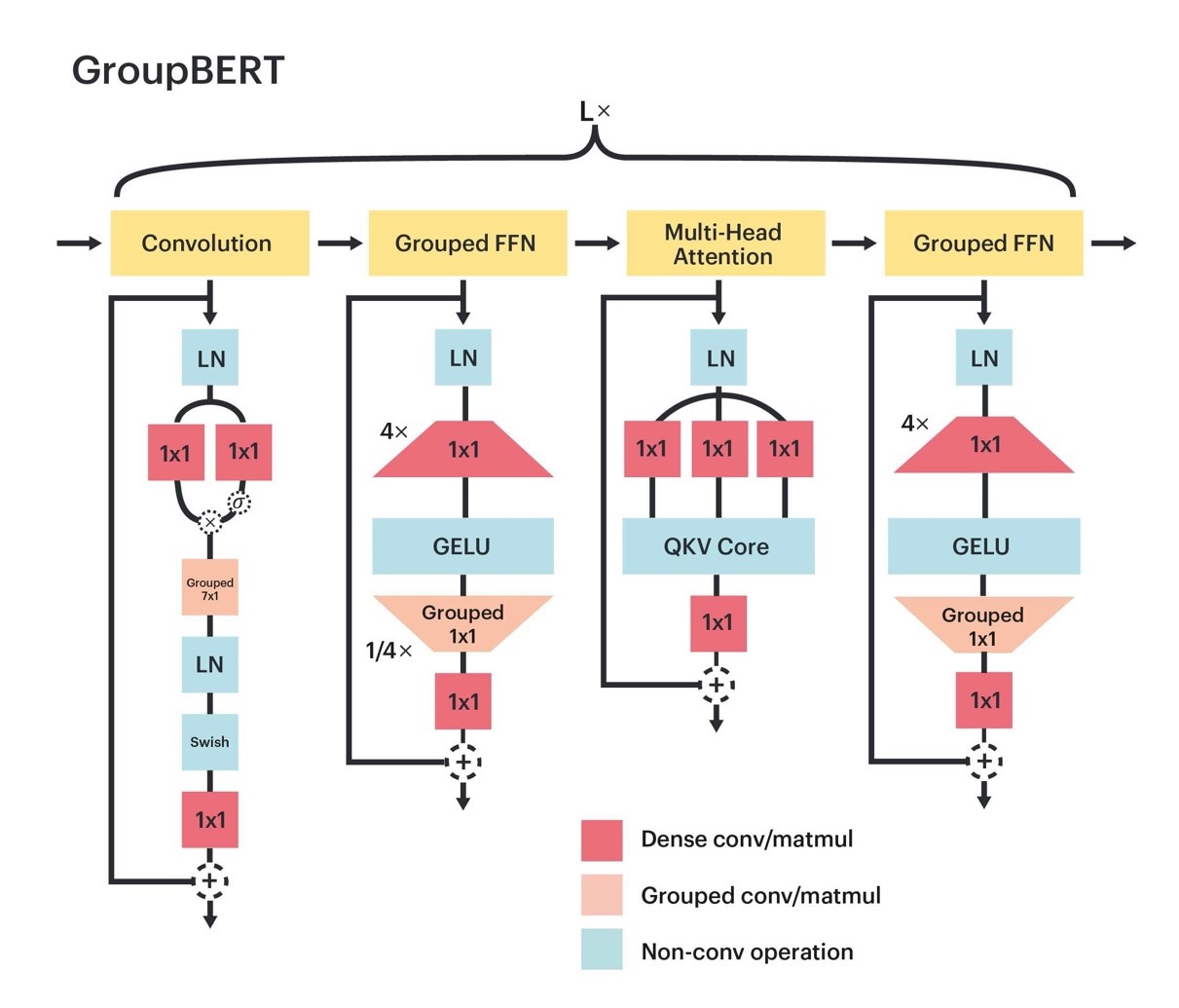
L’étude GroupBERT: Enhanced Transformer Architecture with Efficient Grouped Structures explique comment l’IPU a permis d’explorer des blocs fonctionnels très performants et peu volumineux afin d’en déduire une structure d’encodage de type transformeur, plus efficace lors du préentraînement caché sur un très large corpus de textes.
Le modèle GroupBERT tire parti des transformations groupées. Les modules entièrement connectés sont augmentés par le biais de multiplications groupées de matrices. En outre, un nouveau module de convolution est intégré à la structure du transformeur. De ce fait, chaque couche GroupBERT est étendue à quatre modules plutôt qu’à deux, comme c’est le cas avec le modèle BERT d’origine.
Conformément au taux de perte obtenu avec les données de validation, l’équilibre entre les FLOPS et les performances des tâches est bien meilleur. Pour un taux de perte identique, le modèle GroupBERT requiert moins de la moitié des FLOPS en comparaison avec un modèle BERT traditionnel, qui lui se caractérise uniquement par des opérations denses et n’exploite pas son potentiel de profondeur.
La profondeur accrue et l’intensité arithmétique amoindrie des composants du modèle GroupBERT accentuent les accès à la mémoire. Contrairement aux opérations denses, les opérations groupées induisent un nombre de FLOPS plus bas pour un tenseur d’activation en entrée spécifique. Afin de tirer parti de la puissance en calcul, ces opérations à l’intensité arithmétique faible nécessitent un accès plus rapide aux données. Car l’IPU permet le stockage de l’intégralité des poids et valeurs d’activation dans la puce SRAM avec une bande passante extrêmement élevée de 47,5 To/s, le modèle GroupBERT est non seulement plus efficace, mais il limite aussi la durée d’apprentissage dans bien des contextes.
Un groupement des couches entièrement connectées
La couche d’encodage d’origine se compose de deux modules : le module MHA (Multi-Head Attention, ou « attention multi-têtes ») et le module FFN (Fully Connected Network, ou « réseau entièrement connecté »). De nombreuses recherches ont été effectuées dans le but d’accroître son efficacité. Tay et al. (2020), notamment, présentent diverses approches. La plupart des modifications induites par celles-ci visent à réduire la dépendance computationnelle quadratique du module MHA sur la longueur de séquence. Néanmoins, avec le modèle BERT, la majorité des calculs sont effectués sur une longueur de séquence relativement modérée de 128. De surcroît, le module FFN est celui qui engendre la consommation la plus conséquente en ressources, à raison de près de deux tiers des FLOPS au cours de l’exécution du modèle.
La structure du module FFN est très simple : non linéaire, elle consiste en deux matrices. La première matrice projette la représentation à une dimension plus élevée, généralement quatre fois plus vaste que la représentation cachée du modèle. Cet élargissement de la dimension est suivi par l’exécution d’une fonction d’activation non saturante qui procède à la transformation non linéaire et à la sparsification de la représentation. Enfin, la représentation étendue et éparse est contractée par la matrice de rétroprojection.
Le modèle GroupBERT est synonyme d’un procédé novateur qui réduit les coûts et la durée des calculs avec le module FFN. On remarque que la sparsité causée par le groupement est particulièrement pertinente avec les matrices réceptionnant des entrées éparses. Ainsi, un multiplicateur groupé est seulement introduit au niveau de la deuxième matrice de rétroprojection, ce qui transforme cette dernière en matrice diagonale par blocs. Toutefois, les opérations groupées vont de pair avec une contrainte de localisation au niveau de la représentation cachée entrante, ce qui limite la propagation des informations pendant la transformation. Pour remédier à ce problème, les groupes ont été combinés avec une projection de sortie, semblable au bloc MHA, qui partitionne la représentation cachée au niveau de plusieurs têtes.
Globalement, ce groupement (également appelé « groupement FFN ») permet au modèle GroupBERT de réduire de 25 % le nombre de paramètres de la couche FFN, le tout en limitant de façon minimale les performances des tâches. Ceci tranche avec toutes les méthodes précédentes qui, alors que le groupement de transformeurs était visé, le faisaient s’appliquer aux deux matrices. Le résultat ? Une représentation cachée disjointe et une dégradation considérable des performances.
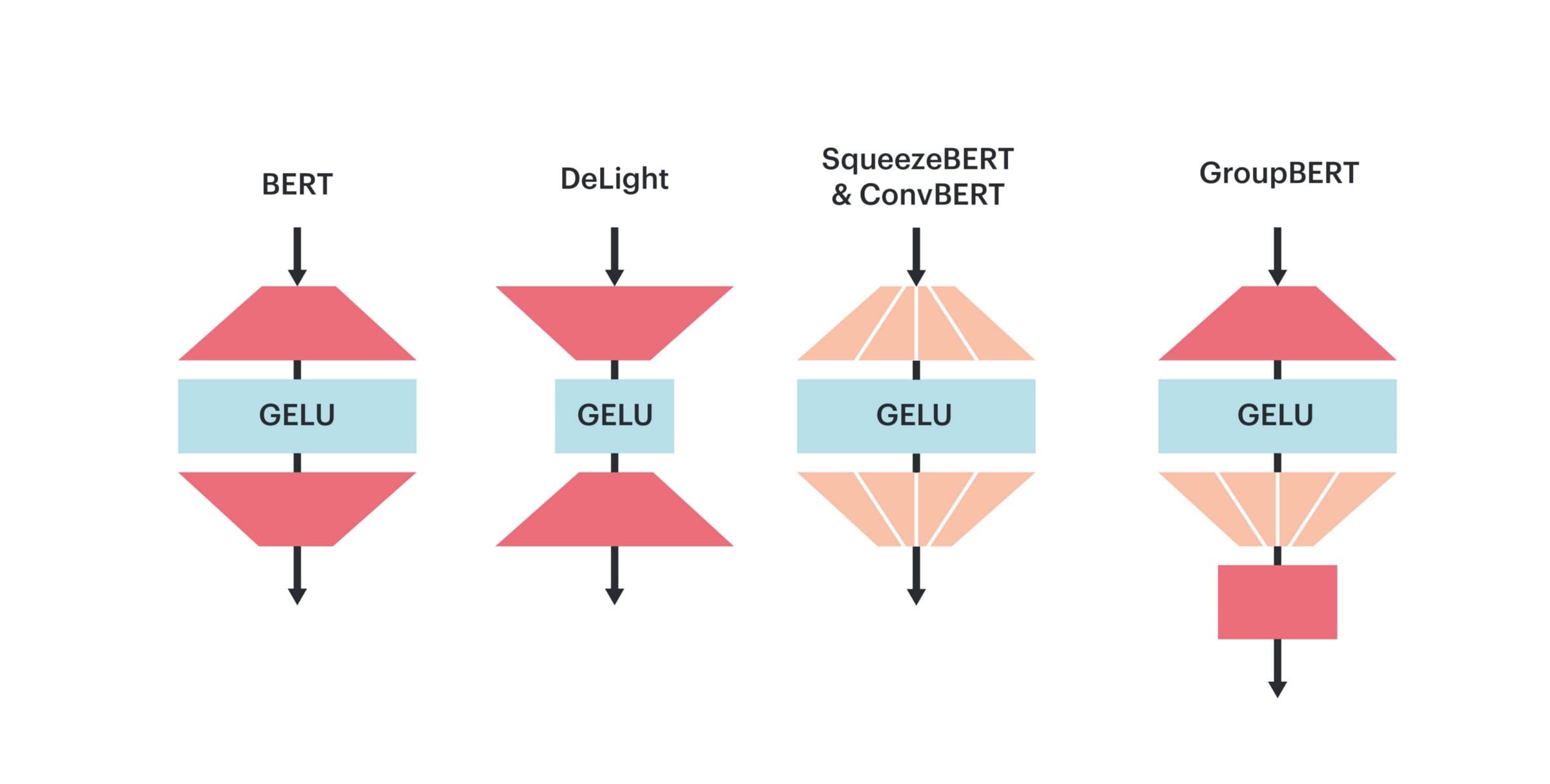
Une convolution groupée qui vient compléter l’attention
Une attention de type « all-to-all » avec les longueurs de séquence propres au modèle BERT n’entraîne pas de surcharge computationnelle notable. Cela étant dit, une étude récente menée par Cordonnier et al. (2020) a démontré que l’emploi exclusif de l’attention multi-têtes pouvait se montrer superflu en premier lieu avec les modèles de langage. Un sous-ensemble de têtes d’attention dans une couche de type transformeur laisse place à un mode convolutionnel afin que seules les interactions locales de tokens soient modélisées.
Le mode de convolution dédié du modèle GroupBERT permet de limiter le calcul répété de schémas d’attention denses lors de la modélisation de l’interaction locale au sein d’une séquence. Une convolution groupée fait office de fenêtre par le biais de laquelle se mêlent les informations entre des tokens de mots qui sont proches les uns des autres. L’encodeur est ensuite étendu à l’aide d’un groupement FFN supplémentaire. Chaque module de traitement de token est dès lors couplé à un module GFFN de traitement d’attribut.
Grâce à ces modules supplémentaires, les interactions locales de tokens sont associées à un élément de modèle léger dédié. Ceci permet ensuite à l’attention MHA de mieux s’exécuter lors de la modélisation d’interactions à longue portée uniquement, dans la mesure où la capacité d’attention est moindre au niveau des interactions locales de tokens. La Figure 3 illustre les schémas d’attention obtenus avec les modèles BERT et GroupBERT à partir des données de validation en phase de pré-entraînement. On remarque clairement que l’exploitation des convolutions permet d’intensifier l’efficacité de l’attention au niveau des interactions à longue portée, le modèle étant plus régulier et étendu.

Des paramètres de modèle qui ont de l’importance
Normalisation
De nombreuses études se sont penchées sur la bonne approche à adopter pour appliquer la normalisation au sein d’un transformeur. Bien que la normalisation de couche soit toujours la plus privilégiée, son application peut s’effectuer de deux façons : à l’aide du paramètre PreNorm ou à l’aide du paramètre PostNorm.
Le paramètre PostNorm permet de normaliser la sortie de la somme connexion saute-couche + résidu, alors que le paramètre PreNorm normalise la représentation de la branche résiduelle avant l’application de la moindre projection, comme illustré sur la Figure 4.

Une implémentation standard du modèle BERT induit l’emploi du paramètre PostNorm, qui présente l’avantage d’offrir des performances plus élevées que le paramètre PreNorm lorsque le taux d’apprentissage par défaut est utilisé. Pourtant, la stabilité de la configuration du paramètre PreNorm est significativement supérieure et peut s’accommoder de taux d’apprentissage plus élevés, ce qui n’est pas le cas d’un modèle avec paramètre PostNorm.
Le paramètre PreNorm étant employé avec le modèle GroupBERT, les performances des tâches sont multipliées. En effet, le modèle peut désormais s’adapter à une multiplication par quatre du taux d’apprentissage, or des taux plus élevés sont importants si l’on cherche à accentuer la généralisation du modèle et à obtenir de meilleurs résultats en convergence.
Des taux d’apprentissage plus élevés ne débouchent pas directement sur des économies en termes de calcul, mais un modèle plus large serait requis si des performances plus conséquentes devaient être obtenues, ce qui entraînerait un élargissement des coûts en calcul. C’est pourquoi l’obtention de taux plus élevés en accroissant la stabilité du modèle est synonyme d’une plus grande efficacité lors de l’emploi de paramètres.
Extinction de neurones
De nombreux modèles de langage basés sur les transformeurs tirent parti de l’extinction de neurones, celle-ci restreignant le sur-ajustement à l’ensemble de données d’apprentissage et favorisant la généralisation. Cependant, car le modèle BERT est pré-entraîné à l’aide d’un très vaste ensemble de données, la question du sur-ajustement ne se pose généralement pas.
Le modèle GroupBERT se passe donc de l’extinction de neurones au cours de la phase de pré-entraînement. Le nombre de FLOPS concernés par la multiplication des masques d’extinction étant négligeable, on peut d’ailleurs parler d’optimisation sans incidence. Néanmoins, la génération de masques d’extinction peut être synonyme d’une forte surcharge en termes de débit. Pour cette raison, l’éradication, avec le modèle BERT, de cette méthode de régularisation aide à l’exécution accélérée du modèle et à l’élévation des performances.
Bien qu’il soit avantageux de procéder au pré-entraînement sur un ensemble de données Wikipédia sans extinction de neurones, cette dernière demeure un outil crucial lors de l’ajustement du modèle GroupBERT. Effectivement, les ensembles de données en question sont considérablement plus petits que le corpus de pré-entraînement.
Le modèle GroupBERT, un transformeur adapté aux IPU
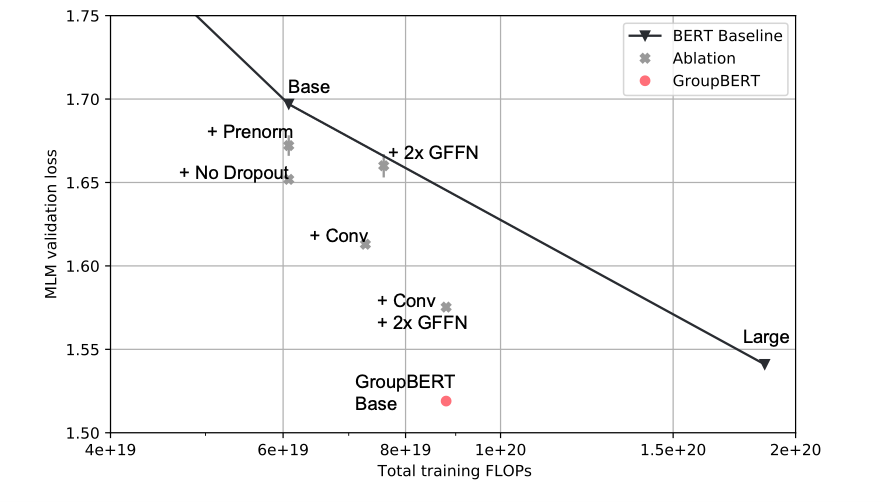
Avant de combiner toutes les modifications concernées dans un seul modèle, il est nécessaire de vérifier l’efficacité de chaque composant. Il convient toutefois de retenir que les groupements FFN réduisent le nombre de FLOPS, alors que l’ajout d’un module de convolution l’accroît. Il n’est donc pas nécessairement pertinent de procéder immédiatement à une comparaison avec le modèle BERT, la quantité de ressources consommée dépendant du modèle. Pour déterminer la qualité des améliorations apportées, nous avons dû effectuer une comparaison qui prenait en compte l’interpolation logarithmique entre des modèles BERT de tailles différentes (standard, intermédiaire et large).
La Figure 5 se rapporte à une étude, par ablation fragmentaire, de chaque amélioration apportée au modèle GroupBERT. Chaque ajout au modèle augmente l’optimum de Pareto du modèle BERT. Après combinaison, et avec les données de validation, le modèle GroupBERT de taille standard est associé au même taux de perte MLM qu’un modèle BERT de taille large, alors même qu’il inclut moins de la moitié des paramètres.
Afin de conclure définitivement que le modèle GroupBERT est d’un niveau supérieur à celui du modèle BERT, nous avons dû prouver que cet avantage perdurait à de nombreuses échelles distinctes. Pour ce faire, nous avons associé deux tailles de modèle supplémentaires au modèle GroupBERT, de manière à obtenir un front de Pareto continu. Cette approche, représentée sur la Figure 6, a permis de démontrer l’avantage constant du modèle GroupBERT sur le modèle BERT, ainsi que sur d’autres modèles qui induisent l’emploi de transformations groupées.
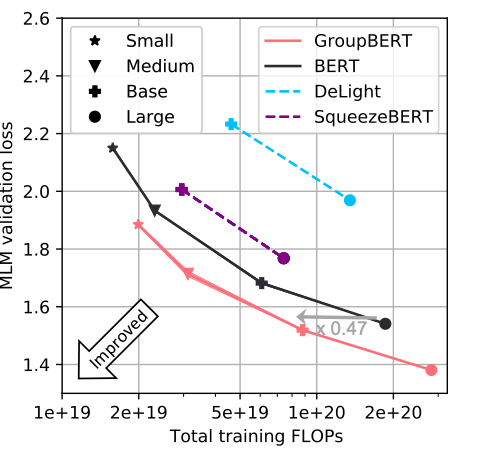
Le modèle GroupBERT étant nativement adapté aux IPU, les économies théoriques obtenues en termes de FLOPS viennent s’ajouter à une durée de pré-entraînement qui n’a plus besoin d’être aussi longue pour garantir l’exactitude des données de validation.
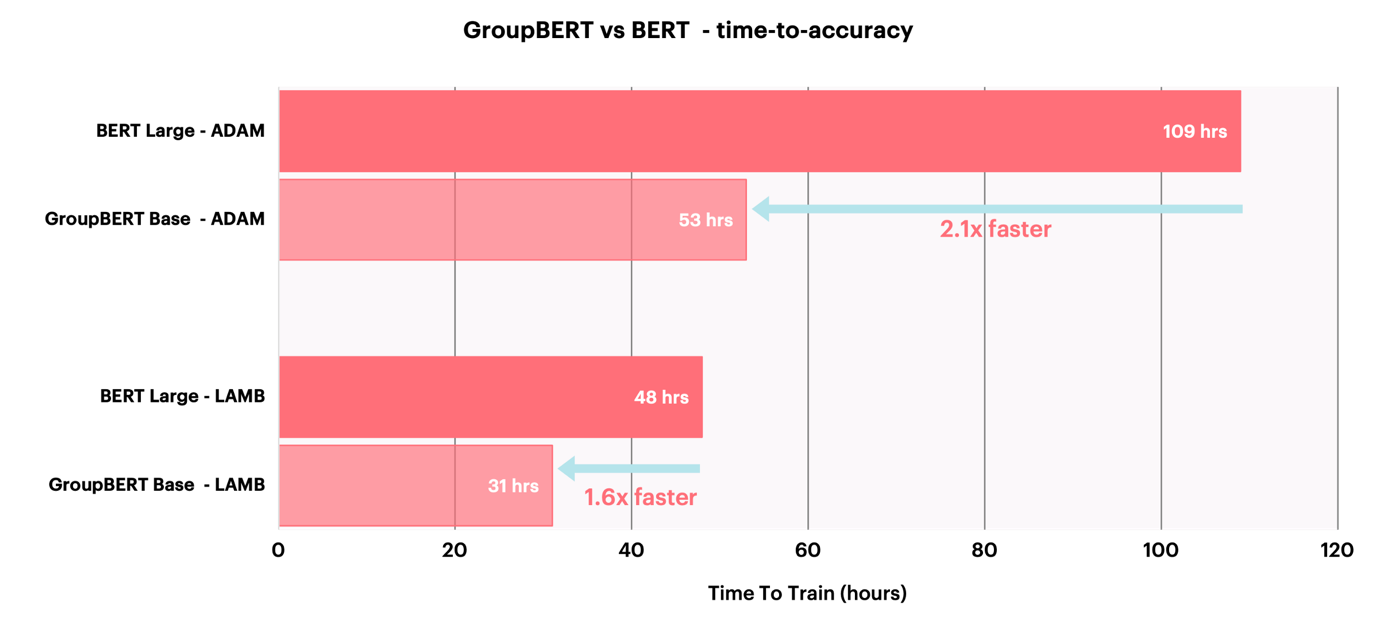
Principales conclusions
Les résultats que nous avons obtenus révèlent les points suivants :
- Les transformations groupées permettent de créer un nombre beaucoup plus important de modèles efficaces.
- La combinaison de convolutions avec une attention dense de type « all-to-all » a une incidence positive, même en cas de tâches nécessitant des interactions à longue portée.
- L’IPU permet d’économiser des FLOPS tout en réduisant la durée de calcul.
- Une hausse significative des performances est possible en ajustant l’architecture, plutôt qu’en procédant à une simple mise à l’échelle du modèle.
En résumé, le modèle GroupBERT permet de multiplier, en phase de pré-entraînement, jusqu’à deux fois les performances d’un modèle BERT. Par conséquent, les calculs sont plus rapides et efficaces.
Consulter l’étude
Accéder au code sur GitHub
Remerciements : Nous remercions Daniel Justus, Douglas Orr, Anastasia Dietrich, Frithjof Gressmann, Alexandros Koliousis, Carlo Luschi et David Svantesson qui ont également contribué à cette étude, ainsi que tous les collègues chez Graphcore pour leur soutien et leurs éclairages.









