
Les grands modèles de langage pré-entraînés, tels que GPT-4 ont révolutionné le domaine du traitement du langage naturel (NLP) en offrant des performances de pointe sur de nombreuses tâches. Cependant, ces modèles sont également très coûteux en termes de ressources, tant pour l’entraînement que pour l’inférence. Des chercheurs de Microsoft Research et de l’ETH Zurich ont développé SliceGPT, une nouvelle méthode de compression post-entraînement pour les modèles de langage pré-entraînés, basée sur la suppression de parties des matrices de poids du réseau.
Les LLMs nécessitent des infrastructures de calcul massives, ce qui limite leur accessibilité et leur déploiement dans divers contextes.
Pour réduire ces coûts, de nombreuses méthodes de compression ont été proposées, telles que la distillation, la quantification, le pruning ou la factorisation. Ces méthodes visent à réduire la taille du modèle, le nombre d’opérations ou la complexité du réseau, tout en préservant les performances du modèle original.
Avec SliceGPT, les chercheurs proposent une nouvelle méthode de compression post-entraînement pour les modèles de langage pré-entraînés, basée sur la suppression de parties des matrices de poids du réseau.
Pour réaliser cette compression, SliceGPT utilise l'analyse en composantes principales (PCA), une méthode statistique qui permet de transformer un ensemble de variables corrélées en un nouvel ensemble de variables non corrélées, appelées composantes principales. Ces composantes capturent l'essentiel de la variabilité des données d'origine.
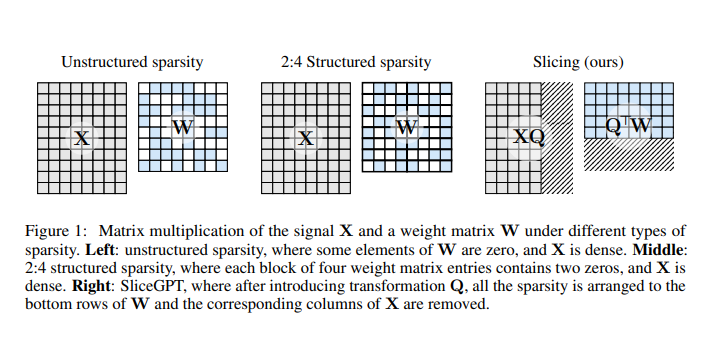
Dans le contexte de SliceGPT, la PCA est utilisée pour calculer des transformations orthogonales à chaque couche du réseau. Ces transformations permettent de projeter le signal entre les blocs du réseau sur ses composantes principales. Ensuite, SliceGPT supprime les composantes principales mineures, ce qui revient à découper des lignes ou des colonnes des matrices modifiées des poids du réseau.
Ce processus de compression est conçu de manière à préserver l'invariance computationnelle du réseau, ce qui signifie que les prédictions du modèle ne sont pas altérées après la compression. En d'autres termes, bien que le modèle soit réduit en taille, il est capable de maintenir ses performances et de produire des résultats similaires à ceux obtenus avec le modèle original non compressé.
Les chercheurs ont évalué les performances de SLICEGPT sur les familles de modèles OPT, LLAMA-2 et Phi-2, en utilisant les jeux de données WikiText-2 et Alpaca pour la calibration. Ils montrent que SLICEGPT peut compresser ces modèles jusqu’à 30% en conservant une perplexité et une précision compétitives, tout en réduisant le temps d’inférence et le nombre de GPU nécessaires.
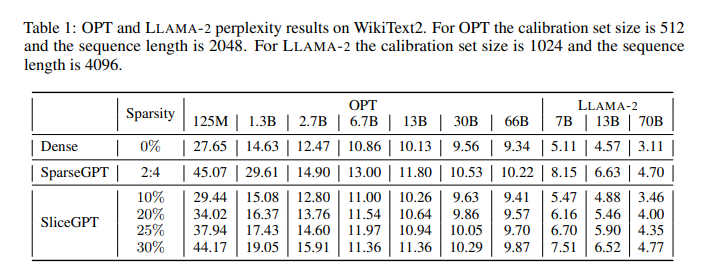 Ils ont également comparé SLICEGPT à d’autres méthodes de compression, SLICEGPT offre un meilleur compromis entre la taille du modèle, la qualité du langage et la vitesse d’inférence.
Ils ont également comparé SLICEGPT à d’autres méthodes de compression, SLICEGPT offre un meilleur compromis entre la taille du modèle, la qualité du langage et la vitesse d’inférence.
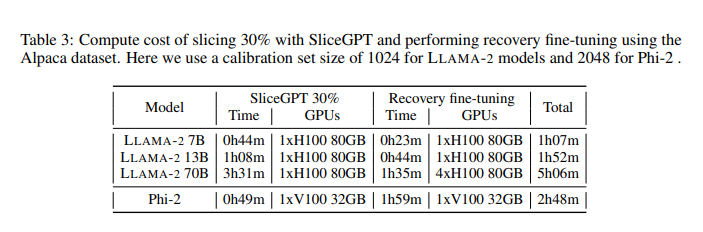 Ils ont réduit le coût de l'inférence du modèle LLAMA-2 70B sur des GPU A100 de 40 Go à 66% de celui du modèle dense sans aucune optimisation de code supplémentaire, en nécessitant moins de GPU (passant de 4 à 3).
Sur des GPU RTX6000 de 24 Go, le coût de l'inférence est réduit à 64%, nécessitant 2 GPU de moins (passant de 7 à 5). Sur des tâches secondaires sans entraînement, en découpant les modèles OPT 66B, LLAMA-2 70B et Phi-2 à 25%, ils maintiennent 99%, 96% et 87% des performances du modèle dense. Avec le réglage fin de récupération, les modèles LLAMA-2 70B et Phi-2 découpés à 25% augmentent respectivement à 99% et 90% de performance.
Les chercheurs espèrent que leurs travaux pourront aider de futures recherches à améliorer l'efficacité des modèles d'apprentissage profond, et peut-être inspirer de nouvelles perspectives théoriques.
Références de l'article :
"SLICEGPT: COMPRESS LARGE LANGUAGE MODELS BY DELETING ROWS AND COLUMNS"
https://doi.org/10.48550/arXiv.2305.18403
Auteurs :
Saleh Ashkboos, Torsten Hoefler, ETH Zurich,
Maximilian L. Croci, James Hensman, Microsoft Research
Marcelo Gennari do Nascimento, Microsoft
Ils ont réduit le coût de l'inférence du modèle LLAMA-2 70B sur des GPU A100 de 40 Go à 66% de celui du modèle dense sans aucune optimisation de code supplémentaire, en nécessitant moins de GPU (passant de 4 à 3).
Sur des GPU RTX6000 de 24 Go, le coût de l'inférence est réduit à 64%, nécessitant 2 GPU de moins (passant de 7 à 5). Sur des tâches secondaires sans entraînement, en découpant les modèles OPT 66B, LLAMA-2 70B et Phi-2 à 25%, ils maintiennent 99%, 96% et 87% des performances du modèle dense. Avec le réglage fin de récupération, les modèles LLAMA-2 70B et Phi-2 découpés à 25% augmentent respectivement à 99% et 90% de performance.
Les chercheurs espèrent que leurs travaux pourront aider de futures recherches à améliorer l'efficacité des modèles d'apprentissage profond, et peut-être inspirer de nouvelles perspectives théoriques.
Références de l'article :
"SLICEGPT: COMPRESS LARGE LANGUAGE MODELS BY DELETING ROWS AND COLUMNS"
https://doi.org/10.48550/arXiv.2305.18403
Auteurs :
Saleh Ashkboos, Torsten Hoefler, ETH Zurich,
Maximilian L. Croci, James Hensman, Microsoft Research
Marcelo Gennari do Nascimento, Microsoft
 Evaluations
Evaluations
Les chercheurs ont évalué les performances de SLICEGPT sur les familles de modèles OPT, LLAMA-2 et Phi-2, en utilisant les jeux de données WikiText-2 et Alpaca pour la calibration. Ils montrent que SLICEGPT peut compresser ces modèles jusqu’à 30% en conservant une perplexité et une précision compétitives, tout en réduisant le temps d’inférence et le nombre de GPU nécessaires.
Ils ont également comparé SLICEGPT à d’autres méthodes de compression, SLICEGPT offre un meilleur compromis entre la taille du modèle, la qualité du langage et la vitesse d’inférence.
Ils ont réduit le coût de l'inférence du modèle LLAMA-2 70B sur des GPU A100 de 40 Go à 66% de celui du modèle dense sans aucune optimisation de code supplémentaire, en nécessitant moins de GPU (passant de 4 à 3).
Sur des GPU RTX6000 de 24 Go, le coût de l'inférence est réduit à 64%, nécessitant 2 GPU de moins (passant de 7 à 5). Sur des tâches secondaires sans entraînement, en découpant les modèles OPT 66B, LLAMA-2 70B et Phi-2 à 25%, ils maintiennent 99%, 96% et 87% des performances du modèle dense. Avec le réglage fin de récupération, les modèles LLAMA-2 70B et Phi-2 découpés à 25% augmentent respectivement à 99% et 90% de performance.
Les chercheurs espèrent que leurs travaux pourront aider de futures recherches à améliorer l'efficacité des modèles d'apprentissage profond, et peut-être inspirer de nouvelles perspectives théoriques.
Références de l'article :
"SLICEGPT: COMPRESS LARGE LANGUAGE MODELS BY DELETING ROWS AND COLUMNS"
https://doi.org/10.48550/arXiv.2305.18403
Auteurs :
Saleh Ashkboos, Torsten Hoefler, ETH Zurich,
Maximilian L. Croci, James Hensman, Microsoft Research
Marcelo Gennari do Nascimento, Microsoft