
Diagnostic plus rapide et précoce des maladies, traitements personnalisés et développement de nouveaux médicaments : qu’il soit question d’améliorer grandement le pronostic des patients, de sauver des vies ou d’aider des individus du monde entier à être en meilleure santé et à vivre plus longtemps, le potentiel de l’IA est conséquent dans le secteur médical.
L’innovation est particulièrement rapide et présente déjà des résultats significatifs. Néanmoins, parallèlement, la confidentialité et la protection des données des patients utilisées pour entraîner des modèles d’IA induisent de nouveaux défis. À juste titre, les interrogations du public, du personnel médical et des gouvernements croissent à ce sujet. En outre, il est devenu essentiel d’approfondir les recherches afin d’optimiser les techniques d’IA et, ainsi, mieux préserver les informations.
Des chercheurs de la faculté de médecine de l’université de Stanford sont à l’origine d’une avancée décisive dans le domaine de la confidentialité différentielle, une méthode clé offrant la possibilité de sécuriser des données sensibles. En utilisant des IPU Graphcore, l’équipe a pu multiplier par plus de 10 la vitesse de l’entraînement d’un modèle d’IA avec confidentialité différentielle. Précédemment considérée comme trop complexe en termes de calcul pour envisager son emploi généralisé, cette dernière est devenue une alternative viable à exploiter dans des situations concrètes.
Après en avoir démontré les bénéfices avec des données d’apprentissage non privées, les chercheurs de Stanford, en collaboration avec Graphcore, envisagent désormais d’appliquer cette technique à des scanners pulmonaires de patients atteints du COVID. L’objectif est de mettre au jour de nouvelles caractéristiques du virus qui continue à affecter des vies tout autour du globe.
Défis liés à la confidentialité des données médicales
L’utilisation d’informations personnelles sensibles dans le cadre de l’IA implique de nombreux défis. Assurer la souveraineté des données et empêcher l’identification des individus constituent deux des plus importants. Dans chaque cas, des solutions technologiques sophistiquées sont à disposition, et deux d’entre elles, décrites ci-dessous, sont de plus en plus prometteuses comme l’ont prouvé les recherches réalisées à Stanford.Apprentissage fédéré
Les modèles entraînés à l’aide de vastes quantités de données variées ayant trait aux patients, et provenant d’ensembles de données détenus par de multiples institutions et fournisseurs de soins qui représentent diverses catégories de population sur la planète, sont plus robustes, moins sujets à certains types de biais et, in fine, plus utiles.L’apprentissage automatique standard nécessite la collation centralisée des données pour l’entraînement. Même lorsque les données sont anonymisées, en retirant les détails qui facilitent l’identification des patients, la transmission de ces informations à des organisations et établissements de recherche tiers s’est avérée particulièrement problématique. En effet, la réglementation exige maintenant souvent que les données des patients demeurent dans la juridiction auprès de laquelle elles ont été obtenues.
L’apprentissage fédéré fait partie des solutions, car les modèles d’IA peuvent, dans ce contexte, être entraînés à l’aide de données de patients anonymisées, sans qu’il faille centraliser celles-ci. À la place, le modèle en cours de développement est appliqué et entraîné localement.
Bien que l’apprentissage fédéré soit une technique d’intérêt, des études récentes ont révélé des failles. Des informations médicales anonymes peuvent effectivement être réidentifiées en déduisant des données à partir d’un modèle intégralement entraîné, ce qui peut permettre de les associer aux personnes concernées, ou en restaurant les ensembles de données d’origine.
Pour cette raison, l’emploi de l’apprentissage fédéré requiert aussi d’optimiser l’application de la confidentialité différentielle.
Confidentialité différentielle
Grâce à la confidentialité différentielle, la protection des données sensibles atteint un niveau supérieur via l’entraînement d’un modèle d’apprentissage fédéré d’une telle sorte qu’il devient impossible, pour qui que ce soit, de déduire des données d’entraînement sur sa base, ou de restaurer les ensembles de données d’origine.La descente de gradient stochastique avec confidentialité différentielle, ou « descente DPSGD », ajoute du bruit aux données de patients anonymisées en tronquant et en modifiant les gradients qui correspondent à des données d’apprentissage individuelles. Avec ce bruit supplémentaire, il est moins aisé d’identifier les données individuelles employées, ou de restaurer l’ensemble de données utilisé au départ pour entraîner le modèle.
Alors qu’elle présente de sérieux avantages quand la sécurité de détails confidentiels est en jeu, la descente DPSGD fait encore l’objet de peu de recherches. En outre, jusqu’à aujourd’hui, elle n’a pas été transposée à de larges ensembles de données, car son utilisation serait trop onéreuse, du point de vue de la capacité de calcul, avec des systèmes traditionnels tels que des GPU ou des processeurs.
C’est sur ce point que s’est attardée, à la faculté de médecine de l’université de Stanford, l’équipe de chercheurs en radiologie spécialisée dans la vision par ordinateur. L’étude NanoBatch DPSGD: Exploring Differentially Private Learning on ImageNet with Low Batch Sizes on the IPU en a été tirée.
Du fait des besoins en calcul, la descente DPSGD est généralement appliquée à de petits ensembles de données, et analysée par leur biais. Néanmoins, l’équipe de Stanford est parvenue à procéder à une première analyse sur des IPU en exploitant 1,3 million d’images provenant de l’ensemble de données ImageNet, disponible publiquement et faisant office, dans ce cadre, de proxy pour un large ensemble constitué de données confidentielles. L’étude démontre qu’il pourrait devenir possible d’envisager le déploiement de la confidentialité différentielle à grande échelle sans être freiné par les limitations qui, actuellement, la caractérisent.
Accélération de la descente DPSGD par nanolots et à l’aide d’IPU Graphcore
Pour accélérer le traitement, une approche courante consiste à employer des microlots dans lesquels les données sont traitées conjointement. Par ailleurs, des gradients joints sont tronqués et modifiés, et non pas des gradients individuels. Il a toutefois été prouvé que ce processus réduit la qualité prédictive du modèle qui en découle, ainsi que les métriques de protection finales, ce qui mène donc plutôt vers un échec. En réalité, c’est avec un microlot d’une taille de 1, également appelé « nanolot », qu’on obtient la plus haute précision.[caption id="attachment_33647" align="aligncenter" width="640"]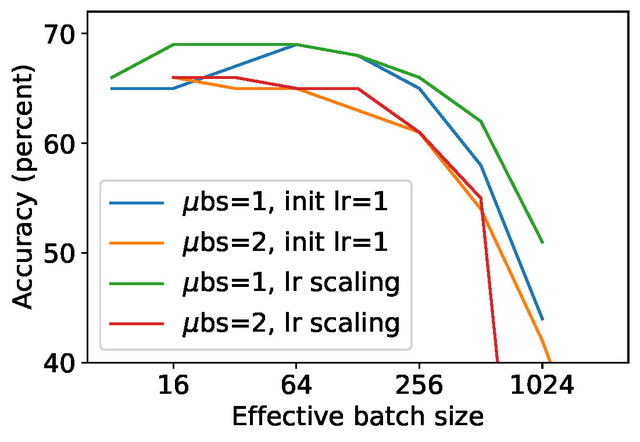 Figure 1 : Précision de la classification après 100 époques d’apprentissage pour différents nombres d’accumulations de gradients. Un nanolot de taille 1 est comparé à un microlot de taille 2. La taille de lot effective correspond au total obtenu en multipliant la taille du microlot par le nombre d’accumulations de gradients. Des troncations et un bruit semblables ont été utilisés pour différentes tailles de lot effectives. Ainsi, les entrées associées à la même taille de lot effective sont garantes d’une protection identique de la confidentialité.[/caption]
Figure 1 : Précision de la classification après 100 époques d’apprentissage pour différents nombres d’accumulations de gradients. Un nanolot de taille 1 est comparé à un microlot de taille 2. La taille de lot effective correspond au total obtenu en multipliant la taille du microlot par le nombre d’accumulations de gradients. Des troncations et un bruit semblables ont été utilisés pour différentes tailles de lot effectives. Ainsi, les entrées associées à la même taille de lot effective sont garantes d’une protection identique de la confidentialité.[/caption]
La descente DPSGD par nanolots n’est pas communément utilisée, surtout car elle entraîne une réduction considérable des performances avec les GPU, à tel point que l’exécution du modèle Resnet-50 sur l’ensemble de données ImageNet nécessite de nombreux jours.
En revanche, la descente DPSGD par nanolots est extrêmement efficace avec les IPU : on parle de résultats 8 à 11 fois supérieurs qu’avec des GPU, et en quelques heures seulement. La surcharge de calcul due aux opérations supplémentaires requises par la descente DPSGD est bien moindre si l’on se tourne vers un IPU ; elle équivaut à 10 % au lieu de 50 à 90. Pourquoi ? Car l’architecture MIMD et le parallélisme granulaire de l’IPU sont synonymes d’une efficacité beaucoup plus élevée.
D’autre part, la protection des données à caractère personnel et la descente DPSGD par nanolots exigent l’emploi d’une norme de groupe, et non de lot, qui peut être rapidement traitée par un IPU, mais qui ralentirait énormément un GPU. Des études menées par Graphcore ont récemment présenté une nouvelle technique de normalisation, la norme de proxy, qui permet d’exploiter les propriétés des normes de lot et d’améliorer l’exécution des tâches. Il existe là un chemin particulièrement intéressant à explorer.
[caption id="attachment_33648" align="aligncenter" width="1116"] Tableau : Comparaison des performances avec des configurations différentes et une taille de microlot de 1. La descente DPSGD sur GPU s’appuie sur l’algorithme vmap et la bibliothèque de confidentialité différentielle TensorFlow. À gauche : puce de génération précédente. À droite : puce de dernière génération.[/caption]
Tableau : Comparaison des performances avec des configurations différentes et une taille de microlot de 1. La descente DPSGD sur GPU s’appuie sur l’algorithme vmap et la bibliothèque de confidentialité différentielle TensorFlow. À gauche : puce de génération précédente. À droite : puce de dernière génération.[/caption]
Descente DPSGD par nanolots avec l’ensemble de données ImageNet en six heures
Le modèle ResNet-50 peut dès lors être entraîné, en six heures environ, à l’aide de l’ensemble de données ImageNet et à raison de 100 époques, sur un IPU-POD16. La durée est de plusieurs jours avec un GPU. Une précision de 71 % a été obtenue, soit 5 % sous la limite. Ceci a été anticipé en raison du bruit supplémentaire et, même si les résultats ont été meilleurs que prévu, cela demeure une variable à approfondir.En cas de confidentialité différentielle, il est fréquent de relever également des valeurs epsilon et delta. Dans cette étude, la valeur epsilon est de 11,4 pour une valeur delta de 10-6, ce qui constitue une plage satisfaisante. L’équipe de chercheurs ambitionne déjà de réduire ces valeurs encore davantage en définissant, par exemple, des périodes d’apprentissage plus agressives afin de diminuer la durée des époques.
[caption id="attachment_33649" align="aligncenter" width="1164"]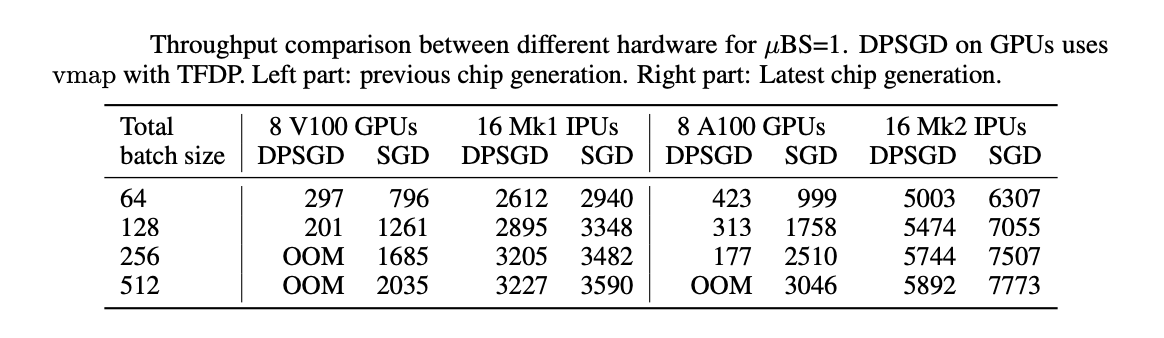
Tableau : Résultats obtenus avec la confidentialité différentielle (valeur epsilon finale et précision après 100 époques), l’ensemble de données ImageNet et différentes configurations et tailles globales de lot. La durée correspond au temps nécessaire, en heures, pour procéder à un entraînement sur 100 époques.[/caption]
Les recherches réalisées ouvrent la voie à de considérables améliorations en termes de confidentialité des données dans le secteur de la santé, mais également dans bien d’autres, comme celui des services financiers où la protection des informations sensibles est cruciale.
Vous pouvez consulter l'étude dans son intégralité sur Arxiv.