
Bloomberg avait révélé la semaine dernière que Mistral AI préparait une seconde levée de fonds, estimée à 450 millions d'euros. Finalement, l'investissement est de 385 millions d'euros, une somme considérable en Europe pour une start-up aussi jeune qui passe d'ailleurs au statut de licorne, puisqu'elle est désormais valorisée à environ 2 milliards de dollars.
Pour rappel, Mistral AI n'a que 7 mois d'existence. Cependant, la détermination et l'expérience de ses cofondateurs les ont très vite amenés sur le devant de la scène française. La start-up est présentée aussi bien en France qu'aux États-Unis comme une alternative à OpenAI, ce qui explique la confiance des investisseurs américains.
Son PDG, Arthur Mensch, expert en deep learning, a travaillé un peu plus de 2 ans et demi au sein de DeepMind, le laboratoire d’IA de Google tandis que Timothée Lacroix, plus de huit ans chercheur chez Meta, et Guillaume Lample qui avait rejoint Facebook AI Research (FAIR) en 2016, sont deux des chercheurs de l’équipe à l’origine de LLama (Large Language Model Meta AI), une collection de modèles de langage de fondation publiée en février dernier
Cette levée de fonds de série A a été dirigée par le fonds de capital-risque Andreessen Horowitz, auquel se sont associés les fonds LightSpeed Ventures et General Catalyst, l’éditeur de logiciel Salesforce, via son fonds dédié à l’IA générative, la banque BNP Paribas et le transporteur CMA CGM. Elle va permettre à la start-up, qui compte aujourd'hui 22 collaborateurs, d'accélérer le développement de ses modèles et produits.
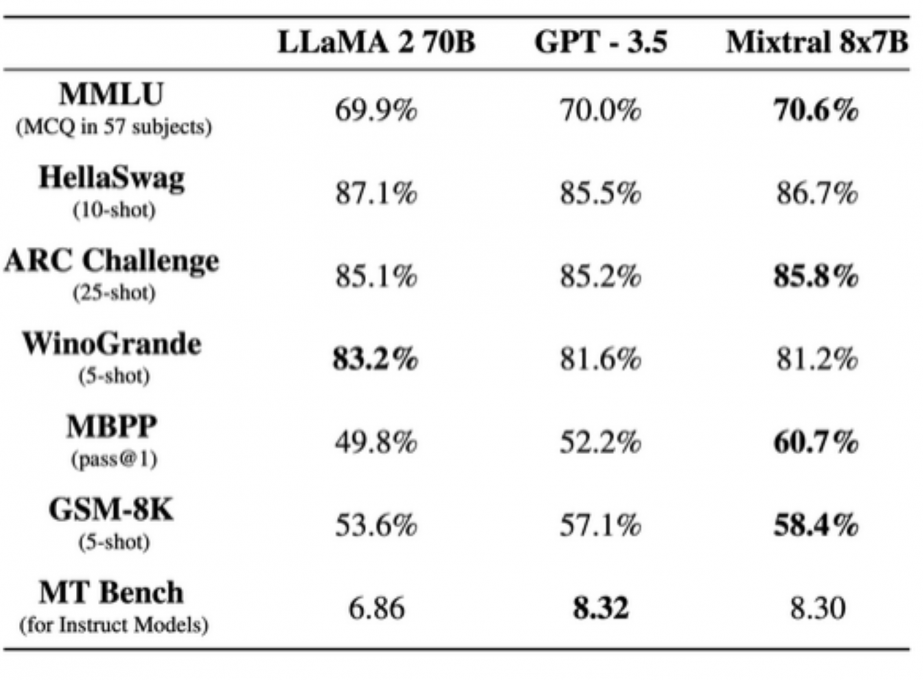 L'équipe de Mistral AI a également mesuré le compromis de ses modèles entre le budget de qualité et le budget d’inférence. Mistral 7B et Mixtral 8x7B se sont révélés très performants par rapport aux modèles Llama 2
L'équipe de Mistral AI a également mesuré le compromis de ses modèles entre le budget de qualité et le budget d’inférence. Mistral 7B et Mixtral 8x7B se sont révélés très performants par rapport aux modèles Llama 2
 Elle a constaté que Mixtral est plus véridique (73,9 % contre 50,2 % sur le benchmark TruthfulQA) et présente moins de biais sur le benchmark BBQ. Dans l’ensemble, Mixtral affiche des sentiments plus positifs que Llama 2 sur BOLD, avec des variances similaires dans chaque dimension.
Elle a constaté que Mixtral est plus véridique (73,9 % contre 50,2 % sur le benchmark TruthfulQA) et présente moins de biais sur le benchmark BBQ. Dans l’ensemble, Mixtral affiche des sentiments plus positifs que Llama 2 sur BOLD, avec des variances similaires dans chaque dimension.
 En même temps que Mixtral 8x7B, Mistral AI a lancé Mixtral 8x7B Instruct, optimisé grâce à un réglage fin supervisé et à une optimisation directe des préférences (DPO) pour un suivi minutieux des instructions. Sur MT-Bench, il atteint un score de 8,30, ce qui en fait le meilleur modèle open-source, avec des performances comparables à GPT3.5.
En même temps que Mixtral 8x7B, Mistral AI a lancé Mixtral 8x7B Instruct, optimisé grâce à un réglage fin supervisé et à une optimisation directe des préférences (DPO) pour un suivi minutieux des instructions. Sur MT-Bench, il atteint un score de 8,30, ce qui en fait le meilleur modèle open-source, avec des performances comparables à GPT3.5.
 S’inscrire pour utiliser l'API
Références de l'article : blog Mistral AI
S’inscrire pour utiliser l'API
Références de l'article : blog Mistral AI
Mixtral AI, le second modèle de Mistral AI
Mistral AI est un fervent défenseur de l'open source, elle déclare d'ailleurs sur son site :"Nous croyons fermement qu’en formant nos propres modèles, en les publiant ouvertement et en encourageant les contributions de la communauté, nous pouvons construire une alternative crédible à l’oligopole émergent de l’IA. Les modèles génératifs à poids ouvert joueront un rôle central dans la prochaine révolution de l’IA”.
Son premier modèle Mistral 7B avait donc été mis à la disposition des développeurs. Bien que de petite taille, ce LLM surpassait tous les modèles ouverts allant jusqu’à 13B paramètres alors disponibles sur tous les benchmarks standards en anglais et en code. La société annonce à présent le lancement du modèle Mixtral 8x7B, basé sur une architecture à mélange clairsemé d'experts (SMoE) avec des poids ouverts, le tout sous licence Apache 2.0. Mixtral a les capacités suivantes :- Il gère gracieusement un contexte de 32k jetons.
- Il gère l’anglais, le français, l’italien, l’allemand et l’espagnol.
- Il montre de solides performances dans la génération de code.
- Il peut être affiné en un modèle de suivi d’instructions qui atteint un score de 8,3 sur MT-Bench.
Un modèle efficace, mais avec un coût et une latence moindres.
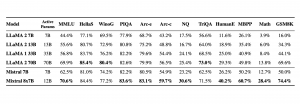
Mixtral est un réseau d'experts épars. En tant que modèle de décodeur exclusivement, il utilise un bloc de rétroaction pour choisir parmi huit groupes distincts de paramètres. À chaque couche et pour chaque jeton, un réseau de routeurs sélectionne deux de ces groupes, appelés "experts", pour traiter le jeton et combine leur sortie de manière additive. Cette approche augmente le nombre total de paramètres du modèle tout en contrôlant le coût et la latence. Mixtral dispose de 46,7 milliards de paramètres au total, mais n'utilise que 12,9 milliards de paramètres par jeton, traitant ainsi les entrées et générant les sorties à la même vitesse et au même coût qu'un modèle 12,9 B. Le modèle est pré-entraîné sur des données extraites du Web ouvert, permettant la formation simultanée d'experts et de routeurs.Les performances du modèle
La start-up a comparé Mixtral à Llama 2 70B et GPT3.5 : il les égale ou surpasse sur la plupart des benchmarks. Mixtral est comparé à la famille Llama 2 et au modèle de base GPT3.5, se montrant équivalent ou supérieur sur la plupart des benchmarks.
L'équipe de Mistral AI a également mesuré le compromis de ses modèles entre le budget de qualité et le budget d’inférence. Mistral 7B et Mixtral 8x7B se sont révélés très performants par rapport aux modèles Llama 2
Hallucinations et préjugés
Afin d'identifier les éventuels défauts à corriger par affinage / modélisation des préférences, l'équipe a mesuré la performance du modèle de fondation sur TruthfulQA/BBQ/BOLD et l'a comparé à Llama 2 70BMaîtrise des langues
Que ce soit en français, allemand, espagnol, italien ou en anglais, Mixtral 8x7B a surpassé les modèles Llama 30B 1e version mais également Llama 2 70B.
En même temps que Mixtral 8x7B, Mistral AI a lancé Mixtral 8x7B Instruct, optimisé grâce à un réglage fin supervisé et à une optimisation directe des préférences (DPO) pour un suivi minutieux des instructions. Sur MT-Bench, il atteint un score de 8,30, ce qui en fait le meilleur modèle open-source, avec des performances comparables à GPT3.5.
Mistral AI ouvre un accès bêta à ses premiers services de plateforme
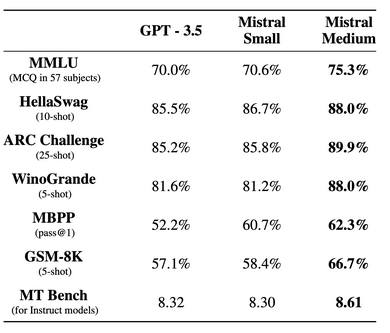
Mistral AI ouvre l'accès à sa version bêta de la plateforme, offrant trois points de terminaison de chat pour la génération de texte basée sur des instructions textuelles, ainsi qu'un point de terminaison d'intégration. Chaque point de terminaison propose un compromis différent entre performance et prix.Points de terminaison génératifs
La start-up dit avoir travaillé à la consolidation des techniques d’alignement les plus efficaces (mise au point, optimisation directe des préférences) pour créer des modèles faciles à contrôler et agréables à utiliser. Elle a pré-entraîné les modèles sur des données extraites du Web ouvert et effectué un réglage fin des instructions à partir d’annotations.- Mistral-Tiny : Le plus rentable, utilisant Mistral 7B Instruct v0.2, noté à 7,6 sur MT-Bench et fonctionnant en anglais uniquement ;
- Mistral-small : Utilisant le modèle Mixtral 8x7B, noté à 8,3 sur MT-Bench, il prend en charge l'anglais, le français, l'italien, l'allemand, l'espagnol, et le code.
- Mistral-Médium : De la plus haute qualité, utilisant un modèle prototype noté à 8,6 sur MT-Bench, prenant en charge plusieurs langues et le code.
S’inscrire pour utiliser l'API
Références de l'article : blog Mistral AI