
Les grands modèles de langage (LLM) exigent d'énormes ressources de calcul et d'énergie pour l'entraînement et l'inférence. Les coûts d'entraînement dépendent de la taille du modèle et du volume de données, tandis que les coûts d'inférence sont influencés par la taille du modèle et le volume de requêtes d'utilisateurs. Dans l'article "Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws", les chercheurs de MosaicML proposent une modification des lois d'échelle de Chinchilla pour inclure les coûts d'inférence.
Cet article de recherche explore les coûts substantiels associés aux LLM en termes de calcul, d'énergie et d'inférence. Les modèles d'aujourd'hui, composés de dizaines de milliards de paramètres et entraînés sur des trillions de tokens, imposent des défis considérables en matière de coûts de calcul et d'énergie.
En effet, plus un modèle a de paramètres, plus il a besoin de données d’entraînement et de temps de calcul pour apprendre. De même, plus un modèle a de paramètres, plus il a besoin d’opérations en virgule flottante (FLOPs) pour générer du texte. Les FLOPs sont une mesure de la complexité d’un algorithme, qui correspond au nombre d’opérations arithmétiques effectuées par seconde.
Le coût de production et de déploiement des LLM pose donc un problème pour les développeurs et les utilisateurs de ces systèmes, qui doivent trouver un compromis entre la qualité du texte généré et le coût d’inférence. Comment choisir la taille optimale d’un modèle de langage, qui maximise la qualité tout en minimisant le coût ?
Les lois d'échelle des LLM, notamment les lois d’échelle de Chinchilla, estiment la qualité d’un LLM en fonction du nombre de paramètres et de données d’entraînement mais ne tiennent compte que des coûts de calcul de l'entraînement. Les auteurs de l’étude ont donc modifié les lois d’échelle de Chinchilla pour y inclure le nombre de FLOPs nécessaires pour l’inférence.
[caption id="attachment_54605" align="alignnone" width="902"]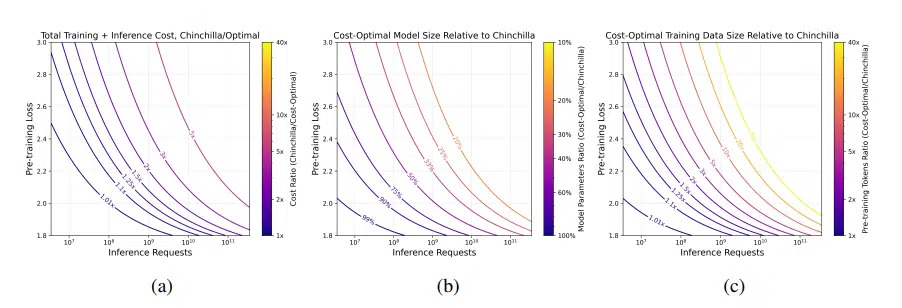 Crédit MosaicML. Légende : Rapports de (a) FLOPs totaux, (b) paramètres du modèle, et (c) jetons de pré-entraînement, pour des modèles optimaux estimés par notre méthode par rapport aux modèles de style Chinchilla. Pour chaque point (x, y) dans les figures, nous calculons le nombre de paramètres du modèle Chinchilla et les données d'entraînement nécessaires pour atteindre la perte y, ainsi que le nombre total de FLOPs requis pour l'entraînement et l'inférence de x jetons en utilisant le modèle Chinchilla. Ensuite, nous calculons les mêmes valeurs (FLOPs totaux, nombre de paramètres, taille des données d'entraînement) pour les modèles optimaux en termes de calcul retournés par notre méthode, et nous représentons les rapports.[/caption]
Ils montrent que, pour une qualité donnée et une demande d’inférence élevée, il est plus rentable d'entraîner des modèles plus petits et plus longtemps que les modèles de style Chinchilla. En effet, les modèles plus petits ont un coût d’inférence plus faible, ce qui compense le coût d’entraînement plus élevé. Des validations expérimentales et des recherches futures sont toutefois nécessaires pour explorer davantage ces propositions dans des plages de données et de modèles extrêmes.
Cette étude apporte une contribution importante pour le domaine des LLM, en proposant une méthode pour minimiser le coût de production et de déploiement de ces systèmes. Elle ouvre aussi des perspectives pour de futures recherches, comme la validation expérimentale des formules proposées, la prise en compte des contraintes de latence, ou l’adaptation de la méthode à d’autres types de modèles.
Références de l'article : "Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws" arXiv:2401.00448v1
Auteurs : Nikhil Sardana et Jonathan Frankle, MosaicML
Crédit MosaicML. Légende : Rapports de (a) FLOPs totaux, (b) paramètres du modèle, et (c) jetons de pré-entraînement, pour des modèles optimaux estimés par notre méthode par rapport aux modèles de style Chinchilla. Pour chaque point (x, y) dans les figures, nous calculons le nombre de paramètres du modèle Chinchilla et les données d'entraînement nécessaires pour atteindre la perte y, ainsi que le nombre total de FLOPs requis pour l'entraînement et l'inférence de x jetons en utilisant le modèle Chinchilla. Ensuite, nous calculons les mêmes valeurs (FLOPs totaux, nombre de paramètres, taille des données d'entraînement) pour les modèles optimaux en termes de calcul retournés par notre méthode, et nous représentons les rapports.[/caption]
Ils montrent que, pour une qualité donnée et une demande d’inférence élevée, il est plus rentable d'entraîner des modèles plus petits et plus longtemps que les modèles de style Chinchilla. En effet, les modèles plus petits ont un coût d’inférence plus faible, ce qui compense le coût d’entraînement plus élevé. Des validations expérimentales et des recherches futures sont toutefois nécessaires pour explorer davantage ces propositions dans des plages de données et de modèles extrêmes.
Cette étude apporte une contribution importante pour le domaine des LLM, en proposant une méthode pour minimiser le coût de production et de déploiement de ces systèmes. Elle ouvre aussi des perspectives pour de futures recherches, comme la validation expérimentale des formules proposées, la prise en compte des contraintes de latence, ou l’adaptation de la méthode à d’autres types de modèles.
Références de l'article : "Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws" arXiv:2401.00448v1
Auteurs : Nikhil Sardana et Jonathan Frankle, MosaicML
Crédit MosaicML. Légende : Rapports de (a) FLOPs totaux, (b) paramètres du modèle, et (c) jetons de pré-entraînement, pour des modèles optimaux estimés par notre méthode par rapport aux modèles de style Chinchilla. Pour chaque point (x, y) dans les figures, nous calculons le nombre de paramètres du modèle Chinchilla et les données d'entraînement nécessaires pour atteindre la perte y, ainsi que le nombre total de FLOPs requis pour l'entraînement et l'inférence de x jetons en utilisant le modèle Chinchilla. Ensuite, nous calculons les mêmes valeurs (FLOPs totaux, nombre de paramètres, taille des données d'entraînement) pour les modèles optimaux en termes de calcul retournés par notre méthode, et nous représentons les rapports.[/caption]
Ils montrent que, pour une qualité donnée et une demande d’inférence élevée, il est plus rentable d'entraîner des modèles plus petits et plus longtemps que les modèles de style Chinchilla. En effet, les modèles plus petits ont un coût d’inférence plus faible, ce qui compense le coût d’entraînement plus élevé. Des validations expérimentales et des recherches futures sont toutefois nécessaires pour explorer davantage ces propositions dans des plages de données et de modèles extrêmes.
Cette étude apporte une contribution importante pour le domaine des LLM, en proposant une méthode pour minimiser le coût de production et de déploiement de ces systèmes. Elle ouvre aussi des perspectives pour de futures recherches, comme la validation expérimentale des formules proposées, la prise en compte des contraintes de latence, ou l’adaptation de la méthode à d’autres types de modèles.
Références de l'article : "Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws" arXiv:2401.00448v1
Auteurs : Nikhil Sardana et Jonathan Frankle, MosaicML