

Un réseau de neurones apprend grâce à des exemples (jeux d’entraînements) qui lui sont soumis. Le but de cet apprentissage est de permettre au réseau de tirer de ces exemples des généralités et de pouvoir les appliquer à de nouvelles données par la suite.
En intelligence artificielle, on parle de surapprentissage (le terme anglais est overfitting) quand un modèle a trop appris les particularités de chacun des exemples fournis en exemple. Il présente alors un taux de succès très important sur les données d’entraînement (pouvant atteindre jusqu’à 100%), au détriment de ses performances générales réelles.
Une courbe représentant la taille moyenne des hommes en fonction de leur age permet d’illustrer le phénomène :
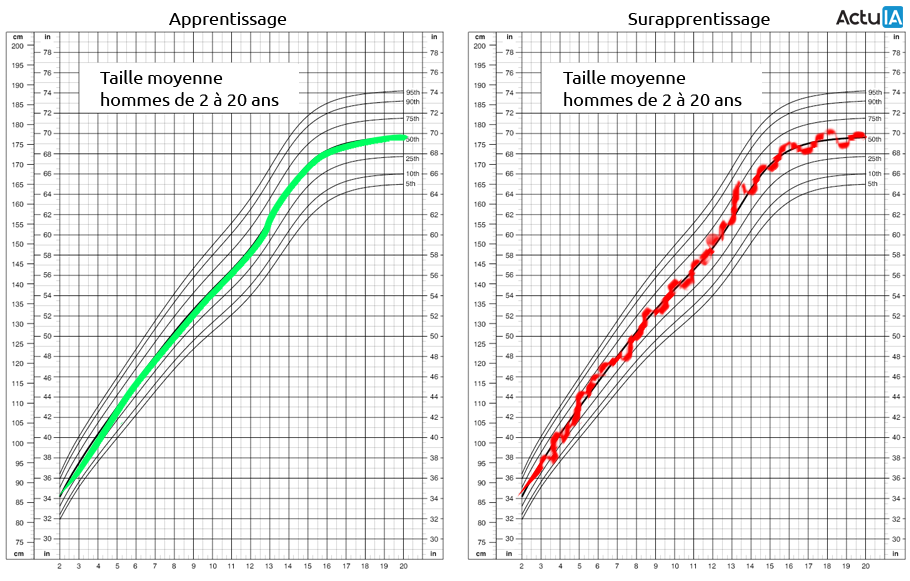
L’exemple de gauche montre un modèle performant, capable d’estimer de façon fiable la taille moyenne d’un homme en fonction de son age. L’exemple de droite quant à lui met en évidence une courbe dont le détail du tracé ne repose sur aucun fondement scientifique : à titre d’exemple, selon cette deuxième courbe un adolescent de 13 ans mesurerait 165cm, puis redescendrait à 162,5cm à 14 ans avant d’atteindre 168cm à 15 ans.
Le modèle reproduit en fait trop fidèlement chacun des échantillons d’entraînement plutôt que de dresser des tendances généralisées. La courbe met en lumière chacun des exemples qui ont été fournis et retranscrit ainsi ce que l’on appelle un “bruit” dans les résultats. Le surapprentissage peut résulter d’un problème de manque d’adéquation entre la complexité du modèle et le dimensionnement du jeu de données.
Lutter contre le surapprentissage
L’un des moyens les plus élémentaires mis en place pour lutter contre le surapprentissage est la séparation des données disponibles en deux jeux distincts : un jeu d’entraînement et un jeu de test. Les échantillons utilisés pour tester les performances du modèle sont alors différents de ceux utilisés pour l’entraîner. On mesure ainsi les capacités du modèle à généraliser les tendances apprises, plutôt qu’à fournir encore et toujours les mêmes résultats mémorisés.
Un modèle dont les performances sont largement inférieures sur le jeu de test que sur le jeu d’entraînement aura très certainement subi un surapprentissage.
Comme indiqué précédemment, le surapprentissage provient d’un manque d’adéquation entre la complexité du modèle et le dimensionnement du jeu de données. Les solutions qui nous viennent donc à l’esprit sont soit de simplifier le modèle (par exemple, en réduisant le nombre de features) soit de réussir à obtenir un plus grand jeu de données.
Cas concret de solution simple:
Reprenons notre exemple de système de prédiction de la taille en fonction de l’age. Cette prédiction devrait, dans la mesure du possible, se faire en reposant sur une moyenne calculée sur le plus grand nombre possible d’individus. Or, si notre dataset ne contient que quelques centaines d’individus et que nous cherchons à prédire la taille d’une personne en fonction de son age précis au jour près, il y a fort à parier que le modèle ait rencontré tout au plus un seul individu correspondant au cours de son apprentissage. Obtenir un plus grand dataset nous permettra de réduire les risques de cas uniques. Mais nous pourrions aussi envisager d’accepter de réduire la finesse de notre prédiction, et non plus nous baser sur la date de naissance de notre utilisateur au jour près, mais au trimestre près.
Il est également de ne pas entraîner un modèle trop longtemps et notamment d’être très attentif au moment où les performances sur jeu d’entraînement et les performances sur jeu de test se croisent.
La régularisation
Il est également possible de lutter algorithmiquement contre le surapprentissage, avec les méthodes de régularisation sur lesquelles nous reviendrons prochainement.








