Prédire une série chronologique nécessite de trouver son chemin dans la jungle des modèles de séries temporelles. Parcourons les points à considérer pour faire le bon choix et simplifier cette tâche souvent fastidieuse.
Chaque série temporelle est différente
Lorsqu'on est confronté à des données du monde réel, chaque spécialiste des données se rendra vite compte que l’on n’est jamais confronté deux fois aux mêmes types de données, surtout lorsqu'il s'agit de séries temporelles (ou séries chronologiques). Une multitude de variables et d'événements externes donneront pour résultat des données non continues.
Ce constat implique qu’il n’existe pas de solution unique pour construire des modèles qui donneront lieu à des prédictions de haute précision.
Cependant, il existe quelques caractéristiques qui peuvent être facilement identifiées et exploitées pour converger plus rapidement vers le modèle le plus efficient.
Continuité
En évoquant les séries temporelles, on tient généralement pour acquis qu'il s'agit de données fluides et continues. Malheureusement, le monde réel n'est pas si simple et linéaire.
Prenons à titre d’exemple les données collectées sur les éoliennes. En l’absence de vent, certaines d’entre elles n'enregistrent pas de données, afin d’économiser de l'énergie. D’autres sont situées dans des zones peu peuplées où la connexion Internet n'est pas stable. Les pertes de connexion sont donc courantes, entraînant des lacunes et ainsi des discontinuités.
Leur traitement ne peut donc se faire à l’aide de modèles dits « continus » tels que ARIMA, SARIMA, Exponential Smooth par exemple. A l’inverse, les méthodes de Gradient Boosting telles que CatBoost sont de bonnes alternatives. Leur structure sous-jacente, basée sur des arbres de décision, est parfaitement adaptée pour capturer des motifs discontinus dans les données.
Données indépendantes du temps
Lorsqu'on traite des séries temporelles, il est généralement nécessaire d'ajouter au modèle des données exogènes et indépendantes du temps pour atteindre un niveau de précision élevé.
Alors qu’on parle d’une série temporelle - par conséquent basée sur le temps - comment intégrer des données indépendantes du temps ? La clé est de s’appuyer sur un modèle dont la variable principale n’est justement pas le temps. On privilégiera alors un prétraitement des données pour en extraire des caractéristiques temporelles et des algorithmes comme SVM qui peuvent donner de bons résultats.
Le volume
L’autre point clé à prendre en compte est la quantité de données à traiter. On ne peut envisager d’entraîner des réseaux de neurones LSTM (Long Short Term Memory) basés sur des données chronologiques avec seulement quelques centaines de points de données. Un volume beaucoup plus important est indispensable.
Stationnarité
Il faudra aussi tenir compte de la stationnarité des données : est-ce que la moyenne et l'écart type de la quantité à prédire évoluent avec le temps ? Le cas échéant, il peut être nécessaire de prétraiter les données, généralement en utilisant une différenciation temporelle, c’est à dire en travaillant avec les variations entre instants de mesure, pour s'assurer que c'est le cas.
Alors, comment choisir le bon modèle ?
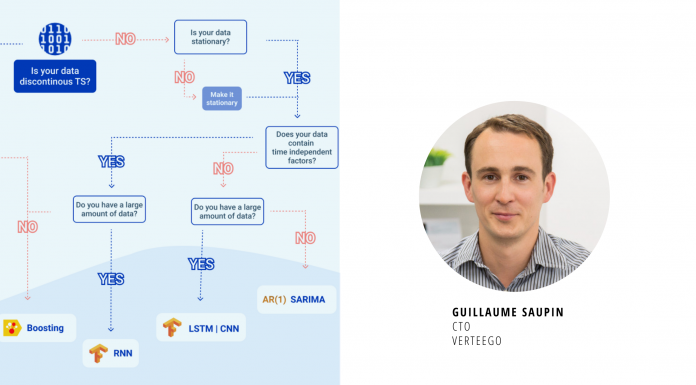
Le schéma ci-dessous résume les paramètres à prendre en compte pour choisir le bon modèle selon la nature des données à disposition.
C'est un bon point de départ pour obtenir un modèle décent. Aller plus loin et atteindre des niveaux de précision plus élevés nécessitera une approche beaucoup plus complexe, conjuguant divers modèles entraînés sur des clusters construits en amont.
On pourra également utiliser de grands réseaux de neurones, conçus pour identifier automatiquement ces clusters et concevoir les meilleures features. En combinant toutes ces étapes en une seule étape d’optimisation, vous n'aurez plus à choisir un modèle de série temporelle.




{kind=link}