

Cet article a été publié initialement sur le blog ParlonsData.
Dans la veine des travaux de Georgia Tech pour comprendre nos amis les poules et coqs, une équipe de data-scientists et de chercheurs en biologie marine s’est intéressée aux sifflements (ou clics) des dauphins pour mieux les identifier et les observer.
La nature reprend ses droits
Il est indéniable que les hommes ont un impact direct sur leur environnement : déforestation, construction d’îles artificielles, etc. Cette constatation s’est toujours faite a posteriori, l’Homme ne réalisant pas l’impact de ses activités industrielles sur les milieux naturels environnants. Il faut dire que les mécanismes entrant en jeu sont mal compris encore aujourd’hui.
Cependant, l’attitude de réaction — plutôt que de prévention — qui a prévalu jusqu’à maintenant, est de moins en moins justifiable. Par exemple, en 2017, deux fleuves emblématiques se sont vus dotés d’une personnalité juridique, et donc d’un droit à la protection : le Whanganui en Nouvelle-Zélande et le Gange en Inde. Dans ces conditions, le principe de neutralité face à la nature n’est plus une option, mais une obligation légale. Ces évolutions juridiques sont la conséquence d’une évolution de la conscience sociétale.
Prenons, dans cet article, l’exemple du golfe du Mexique, partagé par le pays éponyme et 5 états américains. D’un côté, l’administration Trump relance les exploitations offshore aux Etats-Unis. De l’autre, le gouverneur de la Floride entend préserver son patrimoine naturel, ayant toujours en souvenir l’accident de la plateforme Deepwater Horizon.
Comment anticiper au mieux l’impact que pourraient avoir des puits de pétrole en pleine mer sur les écosystèmes alentours ? Comment savoir si un forage perturbera la vie marine par la pollution sonore et environnementale qu’il engendre ?
Observer ce qui se passe sous l’eau
Une première étape consiste à savoir si une zone géographique donnée est densément peuplée par la vie aquatique. Une question compliquée sachant que le golfe représente presque 3 fois la France en terme de superficie.
Une équipe composée de data-scientists et de biologistes (Université de San Diego, Institut d’océanographie de La Jolla, Centre de recherche sur la vie marine de Miami) a donc envisagé une méthode passive, non-invasive et abordable : écouter la mer.

Qu’entend-on une fois la tête sous l’eau ? Du bruit, des bateaux, des animaux. Plus précisément, les animaux qui font du bruit. Un des plus connus est le dauphin : celui-ci émet des “clics” ou sifflements qui lui permet de se localiser, de communiquer, de se nourrir, etc.
Il semblerait que chaque espèce de dauphin ait sa propre manière de siffler. Ainsi, des experts sont capables de discerner des espèces en fonction de leurs sifflements, à la manière d’un ornithologue.
On peut alors imaginer disposer d’un réseau de micros, chacun enregistrerait les clics de dauphin aux alentours et les identifierait. Avec une zone densément quadrillée, on obtient une connaissance temporelle de la position de chaque espèce. En conséquence, il est possible d’identifier des couloirs de migrations ou à l’inverse, des zones désertes dans lesquelles privilégier des activités industrielles.
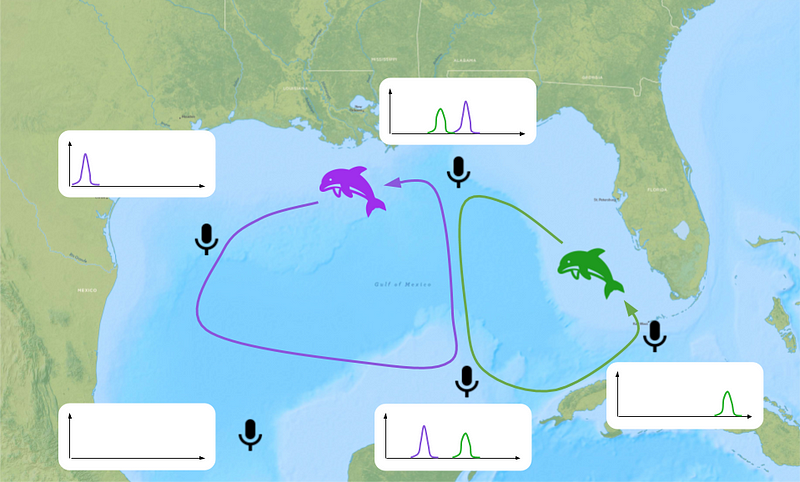
Néanmoins, tout cela sera possible lorsque l’étape d’identification sera fonctionnelle. Les obstacles à lever sont les suivants : comment savoir à quel clic appartient quel dauphin ? Peut-on discerner des clics lorsqu’une dizaine de dauphin se déplace en même temps ? Qui peut réaliser ce travail de fourmi ?
Et l’intelligence artificielle dans tout ça ?
Caractériser le sifflement d’une espèce de dauphin est long et fastidieux (phénomènes de propagation du son en pleine mer, variations propres aux individus de l’espèce, etc.) ; a fait l’objet de plusieurs articles de recherche ; et surtout, est toujours en cours. Autrement dit, les biologistes n’ont pas une connaissance exhaustive des clics des dauphins.
La question que l’on se pose alors : est-ce qu’un algorithme est capable de retrouver ces sifflements caractéristiques et d’en définir de nouveaux ?
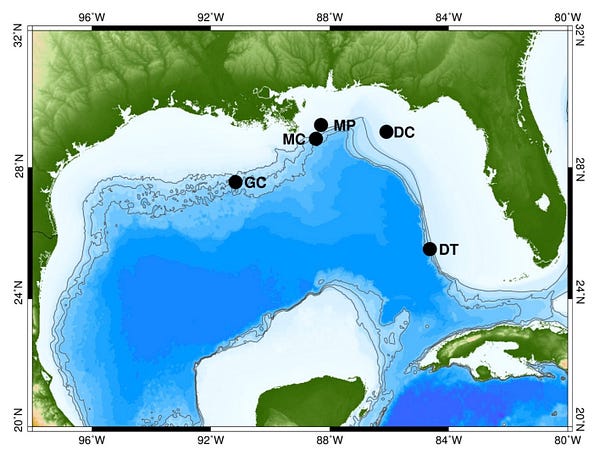
Pour ce faire, l’équipe a utilisé des micros installés sur plusieurs sites autour du golfe et enregistré les clics des dauphins alentours.
Ce sont 1629 jours entiers d’enregistrement qu’elles en ont retiré, chaque jour représentant entre 6000 et 67000 clics à catégoriser.
A partir de ces données, il était alors possible de séparer plusieurs profils de “clics”. Cet exercice est plus connu des data-scientists sous le nom de segmentation ou clustering.
Préparation des données
Mais comment faire pour extraire un clic de dauphin d’une durée de quelques dixièmes de seconde à partir de 39000 heures de données ? Voici le traitement que l’équipe a mis en place :
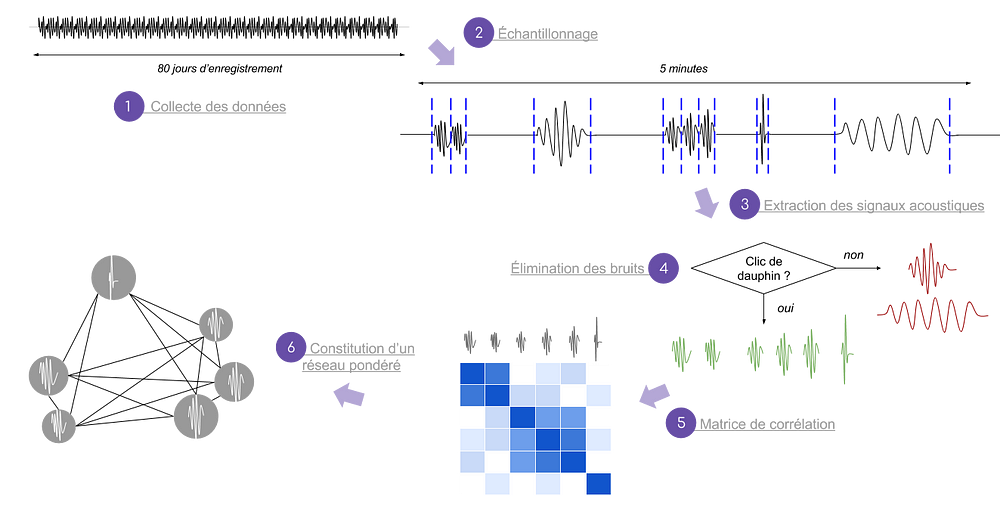
- (2) Les données initiales sont séparées en échantillons de cinq minutes d’enregistrement contenant au minimum 100 clics ;
- (3) Tous les signaux acoustiques dépassant un certain seuil d’énergie sont extraits ;
- (4) Les bruits parasites (bruits de crevette, chalutier, cachalot, etc.) sont éliminés grâce à un logiciel développé à cet effet par un des membres de l’équipe ;
- Enfin, un indice de corrélation est calculé entre les signaux sélectionnés (5). Cet indice de corrélation permet ensuite de calculer une distance entre les signaux, symbolisant leur similarité. Un réseau pondéré entre les différents clics est alors constitué (6) : plus deux noeuds sont proches, plus leur corrélation est forte.
C’est ensuite sur ce réseau que l’étape de segmentation s’opère : l’équipe a utilisé l’algorithme Chinese Whispers (CW) — un algorithme habituellement utilisé pour la compréhension du langage naturel — afin de délimiter des regroupements de clics.
Résultats
Cette segmentation est arrivée à la conclusion qu’il existe, dans les données enregistrées, 7 grands types de clics.
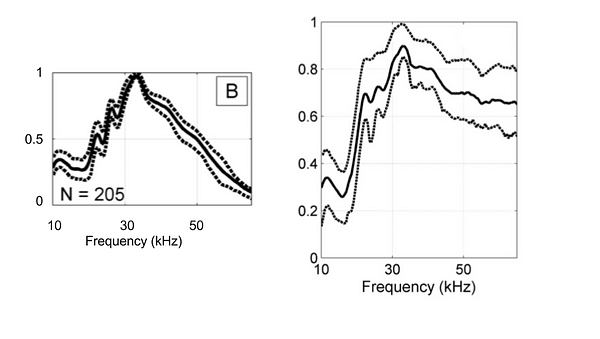
Des enregistrements références ont permis d’attribuer 4 de ces types de clics à 3 espèces différentes (voir exemple ci-contre), les 3 types restants n’ayant pas trouvé de propriétaire évident.
La performance globale est ensuite évaluée en confrontant la classification automatique à une classification humaine.
Pour cela, un biologiste et l’algorithme doivent catégoriser 658 jours de données selon les 7 grands types de clics identifiés par l’algorithme, leurs résultats sont ensuite confrontés. L’algorithme calcule pour chaque classification un indice de confiance (qui revient à calculer la corrélation entre un clic donné et chacun des 7 grands types de clics)
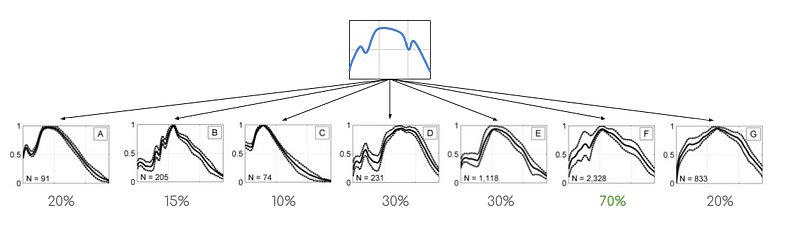
La performance calculée est alors le taux de classification en accord entre l’Homme et la machine. Les résultats sont les suivants :
- les deux “classifieurs” sont d’accord dans plus de 90% des cas lorsque l’algorithme a un indice de confiance supérieur à 50%.
- Néanmoins, la performance tombe à 60% lorsque l’indice de confiance est inférieur à 30%, l’équipe considérera alors que le résultat de la classification automatique n’est pas pertinente.
- En tout, l’algorithme a classifié avec confiance 97.3% des clics. Sur cette proportion de clics, 93.2% sont en accord avec la classification humaine.
L’algorithme est donc capable d’identifier l’appartenance d’un clic donné à une des 7 grandes catégories avec une pertinence satisfaisante.
Et ensuite ?
Aujourd’hui, il reste encore à attribuer les 3 types orphelins à des espèces de dauphin. Néanmoins, cette étude a prouvé qu’un traitement pertinent de signaux acoustiques associé à un algorithme de classification adapté permet d’identifier des espèces de dauphin simplement à partir de leurs sifflements.
Cette étude pourrait être étendue aux crevettes, aux cachalots, aux baleines. Cela permettrait de connaître le cycle de migrations d’une partie de la vie marine à faible coût dans le but de pratiquer une pêche plus intelligente, d’arranger au mieux la pose de câble sous-marins, de définir de nouveaux axes de transports maritimes, etc. Tout cela en minimisant notre impact sur les écosystèmes marins.
Si vous souhaitez en savoir plus sur les projets d’intelligence artificielle que nous menons chez Sicara, n’hésitez pas à nous contacter !









