
Différents articles consacrés aux derniers LLMs soulignent la supériorité de leurs performances par rapport à celles des humains dans des domaines spécifiques tels que le droit ou la chimie, mais qu'en est-il pour le raisonnement, la gestion multimodale, la navigation sur le Web et, de manière générale, la maîtrise de l’utilisation d’outils ? Pour le savoir, une équipe de chercheurs propose GAIA, un benchmark destiné à évaluer les réponses des assistants d'IA à l'instar de ChatGPT, à une série de questions du monde réel par rapport à celles des annotateurs humains.
Les benchmarks visent à évaluer la compréhension et la capacité de génération des modèles dans des domaines spécifiques : STEM met ainsi les LLMs à l'épreuve dans des tâches relevant des sciences, de la technologie, de l'ingénierie et des mathématiques, le benchmark MMLU, quant à lui, se penche sur la capacité d'un modèle à comprendre et à générer du langage dans le contexte de données multimodales, telles que des images associées à du texte, pour ne citer qu'eux.
Alors que de nombreux benchmarks d'IA privilégient des tâches de plus en plus difficiles pour les humains, l'équipe à l'origine de GAIA, composée de chercheurs de FAIR, HuggingFace, AutoGPT et Meta GenAI, repense l'évaluation des capacités des assistants d'IA en mettant l'accent sur leur capacité à résoudre des problèmes du monde réel, ce qui nécessite un ensemble diversifié de compétences.

 GAIA démontre les faibles performances des LLMs par rapport aux annotateurs humains mais pourrait ainsi permettre à leurs fournisseurs d'améliorer leurs produits, voire de se rapprocher de L'IAG.
Les chercheurs lui reconnaissent des limitations, la trace conduisant à la réponse n'est pas évaluée, les questions sont posées uniquement en anglais "standard", et les questions reposent principalement sur des pages web en anglais.
Ils déclarent dans leur article :
GAIA démontre les faibles performances des LLMs par rapport aux annotateurs humains mais pourrait ainsi permettre à leurs fournisseurs d'améliorer leurs produits, voire de se rapprocher de L'IAG.
Les chercheurs lui reconnaissent des limitations, la trace conduisant à la réponse n'est pas évaluée, les questions sont posées uniquement en anglais "standard", et les questions reposent principalement sur des pages web en anglais.
Ils déclarent dans leur article :
Évaluer les assistants d'IA grâce à GAIA
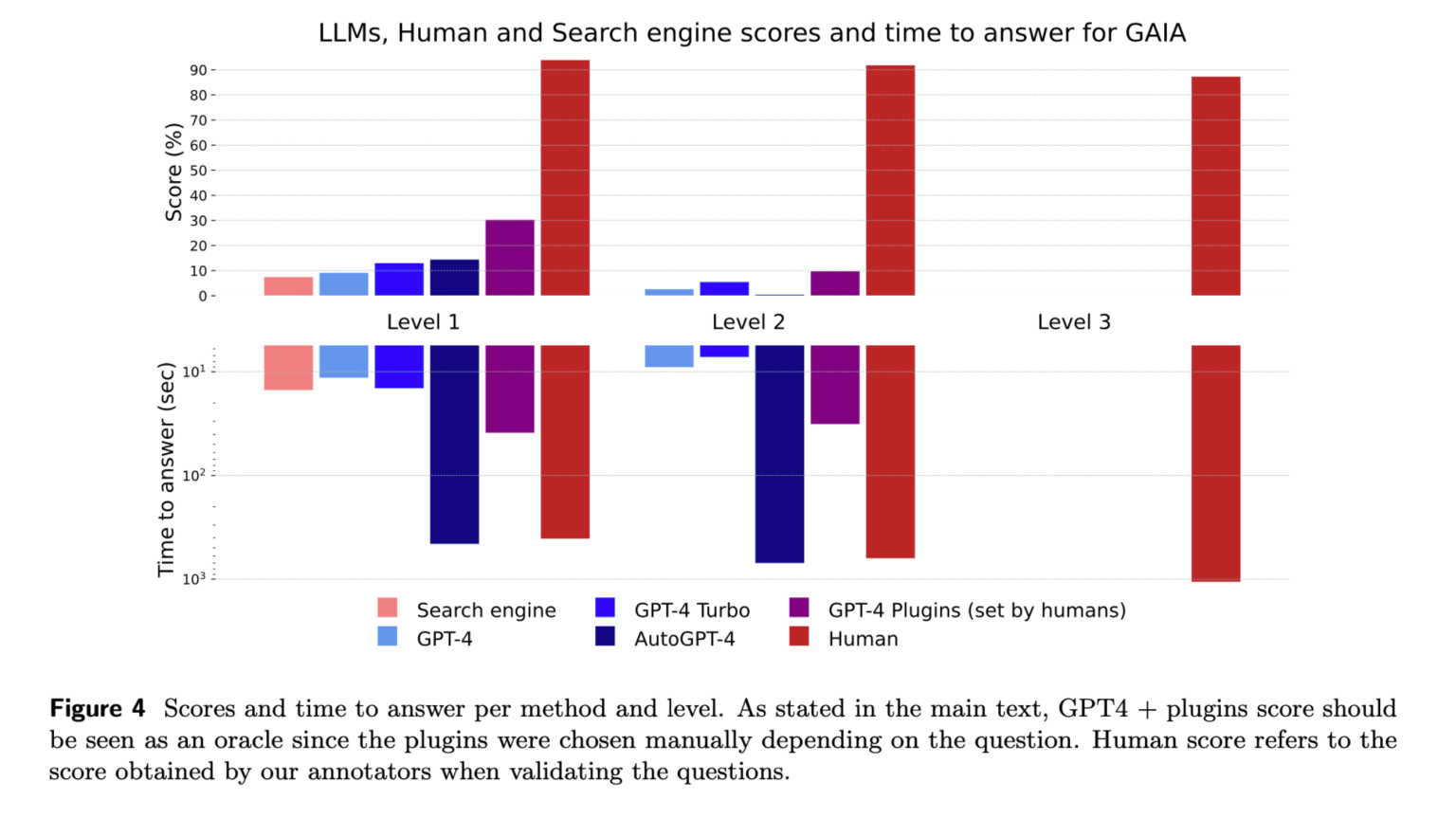
GAIA est un ensemble de 466 questions élaborées et annotées par des humains, "conceptuellement simples mais exigeantes pour les LLMs", rédigées sous forme de texte et pouvant parfois être accompagnées de fichiers supplémentaires, tels que des images ou des feuilles de calcul. Elles abordent divers scénarios d'utilisation des assistants d'IA, couvrant des aspects tels que les tâches quotidiennes personnelles, les domaines scientifiques ou les connaissances générales. La formulation des questions vise à admettre une réponse unique et factuelle, permettant une évaluation automatique simple et robuste. L'équipe les a classées en trois niveaux de difficulté croissante en fonction du nombre d'étapes et d'outils utilisés par les annotateurs lors de la création des questions. Le niveau 1 nécessite peu ou pas d'outils et jusqu'à 5 étapes, le niveau 2 implique généralement entre 5 et 10 étapes avec l'utilisation de différents outils, tandis que le niveau 3 est destiné à un assistant général quasi parfait, exigeant des séquences d'actions longues et l'utilisation de nombreux outils avec un accès global au monde.
L'évaluation de GPT-4
L'équipe a saisi les questions dans un moteur de recherche ce qui lui a d'ailleurs permis d'évaluer s'il était facile ou non de trouver la réponse sur le web. Les chercheurs ont comparé les scores et les temps de réponse du moteur de recherche, de GPT-4 avec ou sans l'ajout de plugins, GPT-4 turbo et AutoGPT-4 au score obtenu par les annotateurs lors de la validation des questions. Alors que ce dernier était de 92 %, GPT-4 avec des plugins n’a obtenu qu’un score de 15 %.
GAIA démontre les faibles performances des LLMs par rapport aux annotateurs humains mais pourrait ainsi permettre à leurs fournisseurs d'améliorer leurs produits, voire de se rapprocher de L'IAG.
Les chercheurs lui reconnaissent des limitations, la trace conduisant à la réponse n'est pas évaluée, les questions sont posées uniquement en anglais "standard", et les questions reposent principalement sur des pages web en anglais.
Ils déclarent dans leur article :
"Alors que les humains excellent à tous les niveaux, les meilleurs LLMs actuels s'en sortent mal. Dans l'ensemble, GAIA permet de classer clairement les assistants performants, tout en laissant beaucoup de place pour des améliorations dans les mois à venir et peut-être au cours des prochaines années"
Ajoutant :"Nous postulons que l’avènement de l’intelligence artificielle générale (AGI) dépend de la capacité d’un système à faire preuve d’une robustesse similaire à celle de l’humain moyen sur de telles questions".
Source de l'article : "GAIA: A Benchmark for General AI Assistants" https://arxiv.org/pdf/2311.12983.pdf Auteurs et affiliations : Grégoire Mialon, Yann LeCun, FAIR Meta Clémentine Fourrier, Thomas Wolf, HuggingFace Craig Swift, AutoGPT Thomas Scialom, GenAI Meta