
On apprenait en juillet dernier qu'Apple faisait discrètement ses premiers pas dans le domaine de l'IA générative avec le chatbot "Apple GPT", utilisé seulement en interne par ses collaborateurs. Ferret, un LLM conçu spécifiquement pour ses smartphones, n'a pas fait davantage l'objet de publicité de la part de la firme. Développé par des experts en IA d'Apple en collaboration avec des chercheurs de l'Université de Columbia, le modèle de langage multimodal open source a toutefois été présenté dans un article de recherche sur arXiv.
Apple a pu sembler à la traîne par rapport aux autres GAFAM dans le déploiement de l'IA générative, Tim Cook, son directeur général, considérait que la GenAI a un potentiel énorme mais, pour lui, certains problèmes restaient à régler.
La société avait ainsi décidé de restreindre à ses employés l’utilisation non seulement de ChatGPT mais d’autres outils d’IA, dont l’assistant de programmation GitHub Copilot pour raison de sécurité. Elle n'entendait pas pour autant se priver des revenus que pouvait lui apporter la technologie, et une de ses équipes travaillait au développement de LLMs, sous la direction de John Giannandrea, son Vice-Président senior de la stratégie d’apprentissage automatique et d’IA, recruté en 2018 après avoir dirigé les divisions de recherche et intelligence artificielle durant 8 ans chez Google. Les employés d’Apple ayant reçu une approbation spéciale ont pu avoir accès à Apple GPT mais sans pouvoir l’utiliser pour développer des fonctionnalités destinées aux clients.
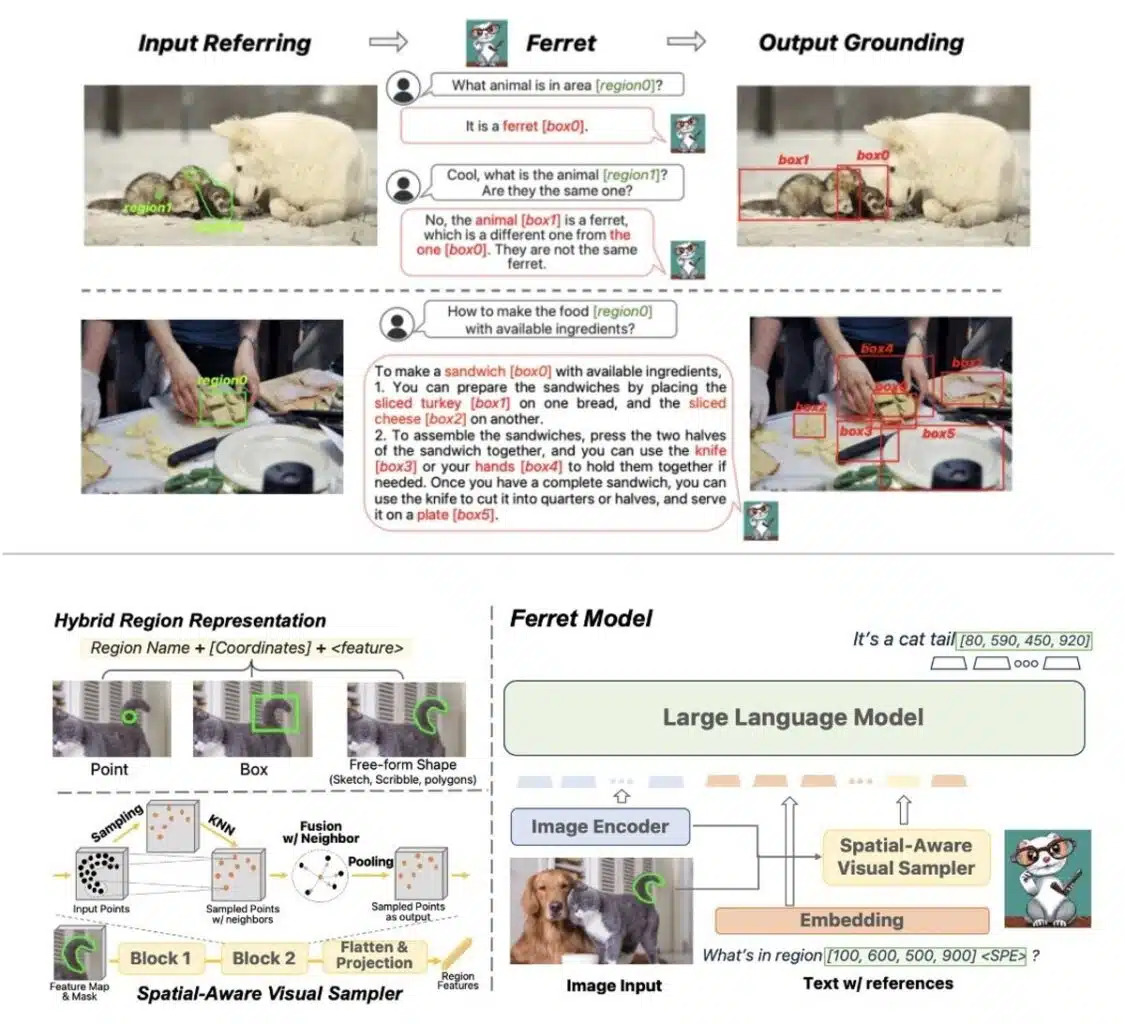 Comme représenté dans la figure ci-dessus, Ferret se compose d'un encodeur d'image pour extraire des embeddings d'image, d'un échantillonneur visuel conscient de l'espace proposé pour extraire des caractéristiques continues régionales, et d'un MLLM pour modéliser conjointement les caractéristiques de l'image, du texte et de la région.
Comme représenté dans la figure ci-dessus, Ferret se compose d'un encodeur d'image pour extraire des embeddings d'image, d'un échantillonneur visuel conscient de l'espace proposé pour extraire des caractéristiques continues régionales, et d'un MLLM pour modéliser conjointement les caractéristiques de l'image, du texte et de la région.
Ferret, un LLM multimodal open source
Ferret, entraîné à l’aide de 8 GPU Nvidia A100, se démarque d'autres modèles multimodaux existants en excellant dans les tâches de référence et de mise à la terre. Il n'analyse pas une image dans son ensemble, mais des régions spécifiques soumises par un utilisateur, qu'elles se réfèrent à des objets ou à des textes, que ce soit sous forme de point, de boîte ou autre forme libre et les incorpore aux requêtes.
Comme représenté dans la figure ci-dessus, Ferret se compose d'un encodeur d'image pour extraire des embeddings d'image, d'un échantillonneur visuel conscient de l'espace proposé pour extraire des caractéristiques continues régionales, et d'un MLLM pour modéliser conjointement les caractéristiques de l'image, du texte et de la région.