
Meta AI a pour ambition de démocratiser la segmentation, une tâche essentielle en vision par ordinateur utilisée dans un large éventail d’applications. Dans ce but, la société présente Segment Anything (SAM), un modèle d'IA qui peut identifier et « découper n’importe quel objet, dans n’importe quelle image, en un seul clic ». Ce modèle, disponible sous une licence ouverte permissive (Apache 2.0), fait partie du projet « Segment Anything » qui a fait l'objet d'une publication sur arXiv le 5 avril dernier.
La segmentation, c'est-à-dire l'identification des pixels d'une image qui appartiennent à un objet, est une tâche importante de la vision par ordinateur, utilisée dans de nombreuses d'applications, de l'analyse de l'imagerie scientifique à la retouche de photos. Cependant, la création d'un modèle de segmentation précis pour des tâches spécifiques nécessite généralement un travail hautement spécialisé de la part d'experts techniques ayant accès à une infrastructure d'entraînement à l'IA et à de grands volumes de données soigneusement annotées dans le domaine.
Le projet Segment Anything vise à réduire les besoins en expertise de modélisation spécifique à une tâche, en calcul d'entraînement et en annotation de données personnalisées pour la segmentation d'images.
L’objectif pour les chercheurs était de construire un modèle de base pour la segmentation en introduisant trois composants interconnectés: une tâche de segmentation rapide, un modèle de segmentation (SAM) qui alimente l’annotation des données et permet un transfert sans tir vers une plage de tâches via une ingénierie rapide, et un moteur de données pour la collecte.
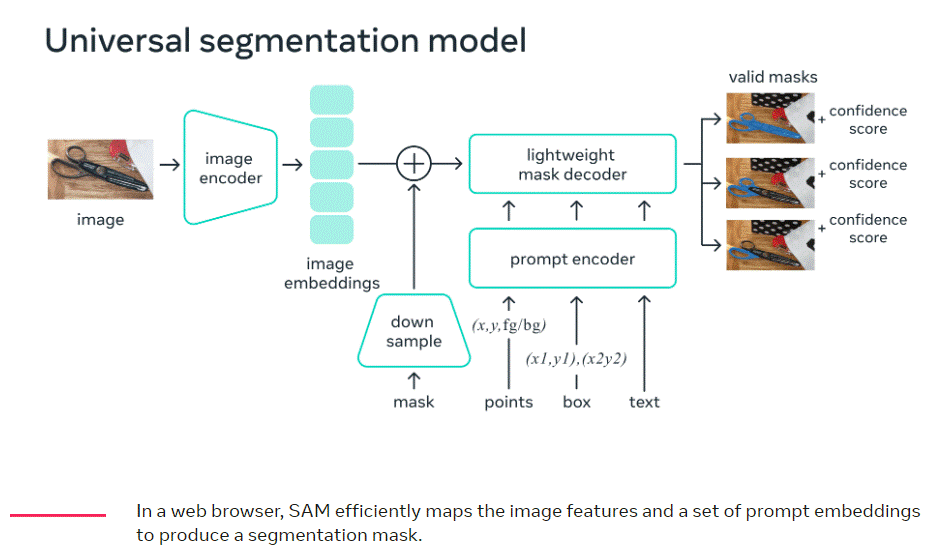 Selon le blog que Meta consacre à SAM, les données de segmentation nécessaires à l'entraînement d'un tel modèle ne sont pas facilement disponibles en ligne ou ailleurs, contrairement aux images, aux vidéos et aux textes, qui sont abondants sur Internet.
Les chercheurs ont choisi de développer un modèle de segmentation général entraîné sur des données diverses qui puisse s'adapter à des tâches spécifiques, de manière analogue à la façon dont l'entraînement est utilisé dans les modèles de traitement du langage naturel et l'ont l'utilisé pour créer un ensemble de données de segmentation d'une ampleur sans précédent, selon eux.
SAM a appris une notion générale de ce que sont les objets, et peut générer des masques pour n'importe quel objet dans n'importe quelle image ou vidéo, y compris des objets et des types d'images qu'il n'a pas rencontrés pendant la formation. Il est suffisamment général pour couvrir un large éventail de cas d'utilisation et peut être utilisé d'emblée sur de nouveaux "domaines" d'images, qu'il s'agisse de photos sous-marines ou de microscopie cellulaire, sans nécessiter de formation supplémentaire.
Selon le blog que Meta consacre à SAM, les données de segmentation nécessaires à l'entraînement d'un tel modèle ne sont pas facilement disponibles en ligne ou ailleurs, contrairement aux images, aux vidéos et aux textes, qui sont abondants sur Internet.
Les chercheurs ont choisi de développer un modèle de segmentation général entraîné sur des données diverses qui puisse s'adapter à des tâches spécifiques, de manière analogue à la façon dont l'entraînement est utilisé dans les modèles de traitement du langage naturel et l'ont l'utilisé pour créer un ensemble de données de segmentation d'une ampleur sans précédent, selon eux.
SAM a appris une notion générale de ce que sont les objets, et peut générer des masques pour n'importe quel objet dans n'importe quelle image ou vidéo, y compris des objets et des types d'images qu'il n'a pas rencontrés pendant la formation. Il est suffisamment général pour couvrir un large éventail de cas d'utilisation et peut être utilisé d'emblée sur de nouveaux "domaines" d'images, qu'il s'agisse de photos sous-marines ou de microscopie cellulaire, sans nécessiter de formation supplémentaire.
SAM, un modèle de base pour la segmentation
Selon le blog que Meta consacre à SAM, les données de segmentation nécessaires à l'entraînement d'un tel modèle ne sont pas facilement disponibles en ligne ou ailleurs, contrairement aux images, aux vidéos et aux textes, qui sont abondants sur Internet.
Les chercheurs ont choisi de développer un modèle de segmentation général entraîné sur des données diverses qui puisse s'adapter à des tâches spécifiques, de manière analogue à la façon dont l'entraînement est utilisé dans les modèles de traitement du langage naturel et l'ont l'utilisé pour créer un ensemble de données de segmentation d'une ampleur sans précédent, selon eux.
SAM a appris une notion générale de ce que sont les objets, et peut générer des masques pour n'importe quel objet dans n'importe quelle image ou vidéo, y compris des objets et des types d'images qu'il n'a pas rencontrés pendant la formation. Il est suffisamment général pour couvrir un large éventail de cas d'utilisation et peut être utilisé d'emblée sur de nouveaux "domaines" d'images, qu'il s'agisse de photos sous-marines ou de microscopie cellulaire, sans nécessiter de formation supplémentaire.