
Google présente Gemma, une famille de modèles légers de pointe conçus à partir des mêmes recherches et technologies que celles utilisées pour créer les modèles Gemini, les plus performants de la firme. L'avantage pour les développeurs et les chercheurs de ces modèles ouverts bien que non open source est qu'ils peuvent fonctionner sur un ordinateur portable, un poste de travail ou Google Cloud avec un déploiement facile sur Vertex AI et Google Kubernetes Engine (GKE).
Google, un des principaux acteurs de l'IA, a accusé le coup à l'arrivée de ChatGPT et fait tout depuis l'introduction de Bard pour revenir dans la course à l'IA générative. En décembre dernier, il dévoilait le fruit des travaux des équipes de DeepMind et Google Research : le modèle multimodal Gemini que Sundar Pichai présentait comme “le modèle le plus performant et le plus général que nous ayons jamais construit”.
Le modèle se décline en trois tailles : Gemini Nano, Gemini Pro et Gemini Ultra, ce dernier surpassant selon Google GPT-4 d'OpenAI, ce que Microsoft réfute d'ailleurs.
Avec un score de 90,0 % contre 86,4 % pour GPT-4, Gemini Ultra est le premier modèle à surpasser les experts humains en MMLU (Massive Multitask Language Understanding), qui utilise une combinaison de 57 matières telles que les mathématiques, la physique, l’histoire, le droit, la médecine et l’éthique pour tester à la fois les connaissances du monde et les capacités de résolution de problèmes.
Google l’a également comparé à GPT-4 sur différents benchmarks, notamment pour le code, le raisonnement, Gemini Ultra le surpasse sauf pour l’inférence de sens commun dans HellaSwag.
Début février, après avoir annoncé apporté l'IA générative à Google Maps, Google rebaptisait Bard en Google Gemini et déployait Gemini Ultra.
 Google présente Gemma comme un modèle responsable et a en effet mis en place des techniques et des outils pour garantir la sécurité, la fiabilité et l’éthique de Gemma.
Par exemple, Google a utilisé des méthodes automatisées pour filtrer les données sensibles ou personnelles des jeux de données d’entraînement, et a appliqué un apprentissage par renforcement à partir des commentaires humains (RLHF) pour aligner les modèles réglés par instruction sur des comportements responsables. Il a également évalué le profil de risque de Gemma à travers des tests manuels et automatisés, et a publié une carte de modèle qui décrit les capacités et les limites de Gemma. Enfin, Google a fourni une boîte à outils pour l’IA générative responsable, qui comprend des classificateurs de sécurité, des outils de débogage et des conseils pour les constructeurs de modèles.
Google présente Gemma comme un modèle responsable et a en effet mis en place des techniques et des outils pour garantir la sécurité, la fiabilité et l’éthique de Gemma.
Par exemple, Google a utilisé des méthodes automatisées pour filtrer les données sensibles ou personnelles des jeux de données d’entraînement, et a appliqué un apprentissage par renforcement à partir des commentaires humains (RLHF) pour aligner les modèles réglés par instruction sur des comportements responsables. Il a également évalué le profil de risque de Gemma à travers des tests manuels et automatisés, et a publié une carte de modèle qui décrit les capacités et les limites de Gemma. Enfin, Google a fourni une boîte à outils pour l’IA générative responsable, qui comprend des classificateurs de sécurité, des outils de débogage et des conseils pour les constructeurs de modèles.
Gemma, un modèle ouvert et responsable
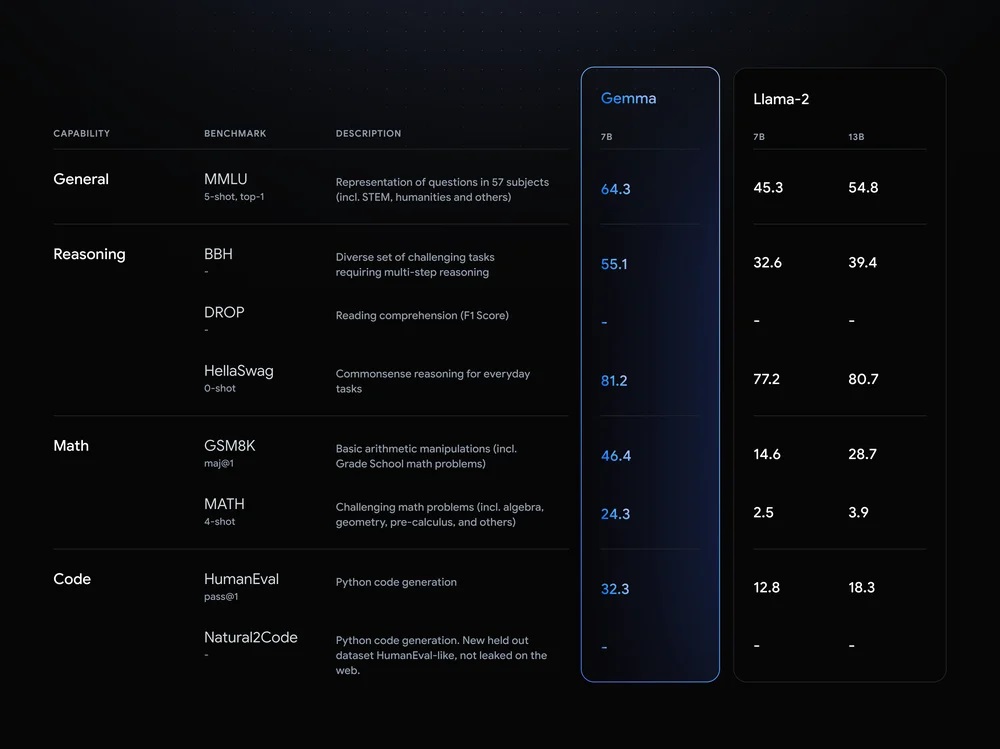
Bien qu'ouvert, Gemma n'est pas un modèle open source au sens strict du terme. Pour Google, le concept d’open source n’est pas toujours applicable aux systèmes d’IA, qui soulèvent des questions nouvelles et complexes sur la sécurité, la propriété intellectuelle et l’éthique. Il a donc publié Gemma avec des conditions d’utilisation qui visent à promouvoir une utilisation responsable et à éviter les abus. Le modèle est présenté en 2 tailles : Gemma 2B et 7B entraînés respectivement sur 2T (trillions) et 6T de jetons, principalement en anglais, provenant de documents web, de mathématiques et de code. Contrairement à Gemini, ces modèles ne sont pas multimodaux et n'ont pas été entraînés pour des performances de pointe sur des tâches multilingues. Chaque taille est publiée pour le texte et le code avec des variantes pré-entraînées et adaptées aux instructions. Sur le benchmark MMLU, si Gemma 7B surpasse toutes les alternatives ouvertes de sa taille, il surpasse également plusieurs modèles plus grands, notamment compris LLaMA2 13B. Il démontre aussi de solides performances sur les benchmarks de mathématiques et de code.
Google présente Gemma comme un modèle responsable et a en effet mis en place des techniques et des outils pour garantir la sécurité, la fiabilité et l’éthique de Gemma.
Par exemple, Google a utilisé des méthodes automatisées pour filtrer les données sensibles ou personnelles des jeux de données d’entraînement, et a appliqué un apprentissage par renforcement à partir des commentaires humains (RLHF) pour aligner les modèles réglés par instruction sur des comportements responsables. Il a également évalué le profil de risque de Gemma à travers des tests manuels et automatisés, et a publié une carte de modèle qui décrit les capacités et les limites de Gemma. Enfin, Google a fourni une boîte à outils pour l’IA générative responsable, qui comprend des classificateurs de sécurité, des outils de débogage et des conseils pour les constructeurs de modèles.