
Des expériences ont montré que les modèles de langage entraînés sur des ensembles de données de courrier électronique peuvent encoder des informations sensibles dans les données d'entraînement et peuvent ainsi révéler les données d'un utilisateur spécifique. Pour pallier à cette problématique, la plupart des datascientists utilisent l'apprentissage fédéré. Les chercheurs de Google AI ont décidé d'appliquer la confidentialité différentielle (Differential Privacy) à la classification ImageNet pour démontrer l'efficacité d'une telle approche.
Les applications basées sur le ML sont de plus en plus nombreuses. La masse de données nécessaires à l'entraînement des algorithmes a soulevé de nombreuses inquiétudes quant à la protection des données personnelles. L'apprentissage fédéré offre de meilleures garanties sur leur confidentialité.
 Source : https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
Source : https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
 Source : https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
Les chercheurs de Google espèrent que ces premiers résultats et le code source donneront une impulsion à d'autres chercheurs pour travailler à l'amélioration de DP et leur recommandent de commencer par une base de référence qui intègre une formation par lots complets et un apprentissage par transfert.
Sources de l'article: "Toward Training at ImageNet Scale with Differential Privacy"
Source : https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
Les chercheurs de Google espèrent que ces premiers résultats et le code source donneront une impulsion à d'autres chercheurs pour travailler à l'amélioration de DP et leur recommandent de commencer par une base de référence qui intègre une formation par lots complets et un apprentissage par transfert.
Sources de l'article: "Toward Training at ImageNet Scale with Differential Privacy"
L'apprentissage fédéré et la confidentialité différentielle
En 2017, Google a mis au point un concept de Deep Learning distribué sur les terminaux : le Federated Learning, ou apprentissage fédéré, une solution qui permet un traitement directement embarqué sur les périphériques Android des données à analyser. Pour fonctionner, un modèle de Deep Learning n’a pas besoin de données, celles-ci sont uniquement utilisées de manière à procéder à l’ajustement des poids des liaisons reliant les neurones artificiels au cours de la phase d’apprentissage. Ainsi, l'apprentissage fédéré permet aux téléphones mobiles d'apprendre en collaboration tout en dissociant la capacité d'apprentissage automatique de la nécessité de stocker les données dans le cloud. La confidentialité différentielle (Differential Privacy ou DP) empêche les modèles de stocker des données spécifiques d'individus et leur permet seulement d'apprendre des comportements statistiques. Grâce à elle, la protection des données sensibles est garantie via l’entraînement d’un modèle d’apprentissage fédéré puisque déduire des données d’entraînement sur sa base ou restaurer les ensembles de données d’origine devient quasi impossible. Dans le cadre DP, les garanties de confidentialité d'un système sont généralement caractérisées par un paramètre positif ε, appelé perte de confidentialité, avec un ε plus petit correspondant à une meilleure confidentialité. On peut former un modèle avec des garanties DP à l'aide de DP-SGD (descente de gradient stochastique avec confidentialité différentielle), un algorithme de formation spécialisé qui fournit des garanties DP pour le modèle formé. Cependant, cette formation est peu utilisée car elle présente généralement deux inconvénients majeurs: la lenteur ainsi que l'inefficacité des implémentations et un impact négatif sur l'utilité (telle que la précision du modèle). En conséquence, la plupart des articles de recherche DP présentent les algorithmes DP sur de très petits ensembles de données et n'essaient même pas d'effectuer une évaluation d'ensembles de données plus volumineux, tels que Image Net. Les chercheurs de Google ont publié les premiers résultats de leur recherche à l'aide de DP qui s'intitule : "Toward Training at ImageNet Scale with Differential Privacy"Test de confidentialité différentielle sur ImageNet
Les chercheurs ont choisi la classification ImageNet comme démonstration de la praticité et de l'efficacité de DP parce que les recherches sur la confidentialité différentielle dans ce domaine sont très rares et ne connaissent que peu d'avancées et que d'autres chercheurs auront l'opportunité d'améliorer collectivement l'utilité de la formation réelle du DP. La classification sur ImageNet est un défi pour DP car elle nécessite de grands réseaux avec de nombreux paramètres. Cela se traduit par une quantité importante de bruit ajoutée au calcul, car le bruit ajouté est proportionnel à la taille du modèle.Mise à l'échelle de la confidentialité différentielle avec JAX
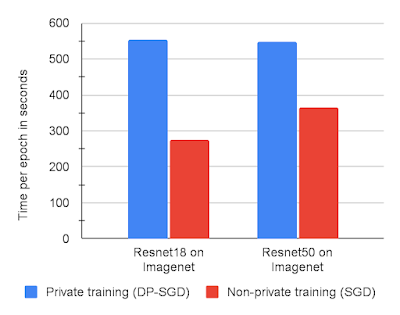
Les chercheurs, pour gagner du temps, ont utilisé JAX, une bibliothèque de calcul haute performance basée sur XLA qui peut effectuer une vectorisation automatique efficace et une compilation à la volée des calculs mathématiques, recommandée pour accélérer DP-SGD dans le contexte d'ensembles de données plus petits tels que CIFAR-10. Leur implémentation de DP-SGD sur JAX a été comparée au grand ensemble de données ImageNet. Bien que relativement simple, elle a entraîné des gains de performances notables simplement en raison de l'utilisation du compilateur XLA par rapport à d'autres implémentations de DP-SGD, telles que celle de Tensorflow Privacy. XLA est généralement encore plus rapide que le PyTorch Opacus personnalisé et optimisé. Chaque étape de l'implémentation DP-SGD nécessite environ deux passages aller-retour à travers le réseau. Alors que la formation non privée ne demande qu'un seul passage, l'approche de Google est la plus efficace pour l'entraînement avec les gradients nécessaire pour DP- SGD. Les chercheurs ont jugé DP-SGD sur JAX suffisamment rapide pour effectuer de grandes expériences simplement en réduisant légèrement le nombre d'exécutions de formation utilisées pour trouver des hyperparamètres optimaux par rapport à la formation non privée. Une nette amélioration par rapport à Tensorflow Privacy, 5 à 10 fois plus lent sur CIFAR10 et MNIST. Le graphique ci-dessous montre les temps d'exécution de formation pour deux modèles sur ImageNet avec DP-SGD par rapport à SGD non privé, chacun sur JAX.
Source : https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
Transférer l'apprentissage à partir de données publiques
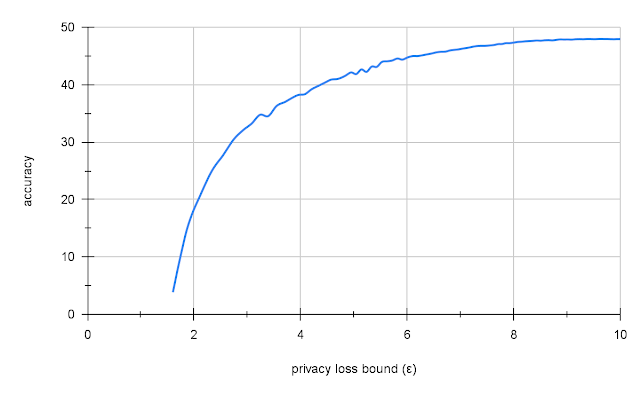
Il a été démontré qu'une formation préalable sur les données publiques suivie d'un ajustement du DP sur les données privées améliore la précision sur d'autres points de référence mais le problème est de trouver quelles données publiques utiliser pour une tâche donnée afin d'optimiser l'apprentissage par transfert. Les chercheurs de Google ont simulé une séparation des données privées/publiques en utilisant ImageNet comme données "privées" et en utilisant Places365, un autre ensemble de données de classification d'images, comme proxy pour les données "publiques". Dans ce but, ils ont préformé leurs modèles sur Places365 avant de les affiner avec DP-SGD sur ImageNet. Places365 ne présente que des images de paysages et de bâtiments, et non pas d'animaux comme ImageNet, ce qui en fait un bon candidat pour démontrer la capacité du modèle à se transférer dans un domaine différent mais connexe. L'apprentissage par transfert de Places365 a donné une précision de 47,5 % sur ImageNet avec un niveau de confidentialité raisonnable (ε = 10). C'est faible par rapport à la précision de 70 % d'un modèle non privé similaire, mais par rapport à la formation DP naïve sur ImageNet, qui donne une précision très faible (2 - 5 %) ou aucune confidentialité (ε = 10 ), c'est un bon résultat.Source : https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
Les chercheurs de Google espèrent que ces premiers résultats et le code source donneront une impulsion à d'autres chercheurs pour travailler à l'amélioration de DP et leur recommandent de commencer par une base de référence qui intègre une formation par lots complets et un apprentissage par transfert.
Sources de l'article: "Toward Training at ImageNet Scale with Differential Privacy"