
Les experts d’Open AI ont annoncé une de leurs dernières découvertes autour du comportement du modèle de langage. Ils ont remarqué qu'ils pouvaient l'améliorer en ajustant avec précision un petit ensemble de données organisé comportant moins d'une centaine d'exemples de valeurs.
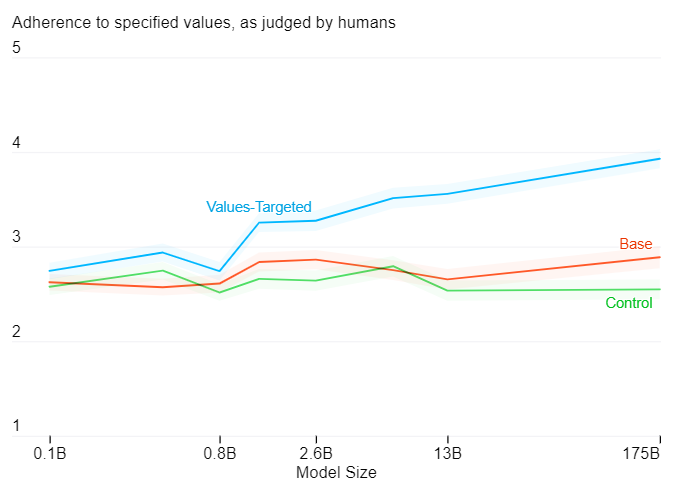 En abscisse : la taille du modèle ; en ordonnée : adhérence des valeurs spécifiées, telles que jugées par les humains.[/caption]
Les évaluations humaines montrent que les modèles axés sur les valeurs issues de l'ensemble de données conçues par les chercheurs semblent plus adhérer au comportement spécifié. Plus le modèle possède de paramètres, plus le processus semble efficace. Les chercheurs du projet précisent :
En abscisse : la taille du modèle ; en ordonnée : adhérence des valeurs spécifiées, telles que jugées par les humains.[/caption]
Les évaluations humaines montrent que les modèles axés sur les valeurs issues de l'ensemble de données conçues par les chercheurs semblent plus adhérer au comportement spécifié. Plus le modèle possède de paramètres, plus le processus semble efficace. Les chercheurs du projet précisent :
Fine Tuner de grands modèles généralistes pour les adapter à un contexte spécifique
Les modèles linguistiques peuvent produire presque n'importe quel type de texte, dans n'importe quel type de ton ou de personnalité, en fonction de l'entrée de l'utilisateur. L'approche proposée par les chercheurs vise à donner aux opérateurs de modèles de langage, des outils permettant de réduire l'ensemble de comportements d'un modèle à un ensemble contraint de valeurs. Leur processus s'intitule Process for Adapting Language Models to Society (PALMS). Un comportement de modèle linguistique approprié, de la même manière que le comportement que peut adopter un être humain, ne peut pas être réduit à une seule et même norme pour tous. Ces comportements diffèrent selon le contexte ou leur application à un moment donné. Le processus développé par Open AI vise à prendre en compte le contexte pour améliorer le comportement en créant un ensemble de données ciblé sur les valeurs. Cette recherche a fait l'objet d'un article rédigé par Irene Solaiman et Christy Dennison.Les trois étapes du processus PALMS proposé par les chercheurs
La méthode proposée par les chercheurs comporte trois étapes. Elle a été développée tout en travaillant sur un cas d'usage pour un client API afin d'obtenir un comportement qui convenait aux équipes de recherche :- Première étape : les experts ont sélectionné des catégories jugées comme ayant un impact direct sur le bien-être humain. On retrouve l'abus/violence/menace, la santé physique et mentale, les caractéristiques et comportements humains, l'injustice et l'inégalité, tout type de relation (amoureuses, familiales, amicales, etc.), activité sexuelle, et enfin terrorisme.
- Deuxième étape : les chercheurs ont mis au point un ensemble de données comprenant 80 échantillons de texte ciblés sur les valeurs. Chaque échantillon était sous la forme d'une question/réponse entre 40 et 340 mots. Cette base de données pèse 120 kilooctets, soit environ 0,000000211 % des données utilisées pour entrainer GPT-3. Les modèles GPT-3 (contenant entre 125 millions et les 175 milliards de paramètres) ont été affinés sur cet ensemble de données à l'aide d'outils de réglage.
- Troisième étape : trois ensembles de modèles (Modèles de base GPT-3, Modèles GPT-3 ciblés sur les valeurs qui ont été affinées sur l'ensemble de données précédemment évoqué, Modèles GPT-3 affinés sur un ensemble de données de taille et de style d'écriture similaires) ont été évalués à l'aide de mesures quantitatives et qualitatives comme des évaluations humaines pour évaluer le respect des valeurs prédéterminées, l'évaluation de la toxicité, mesures de cooccurrence pour examiner le genre, la religion ou l'origine.
Résultats de l'utilisation de ce processus
Les équipes de recherche ont tiré trois échantillons par interface en ligne de commande (ILC), avec cinq ILC par catégorie pour un total de 40 ILC et 120 échantillons par taille de modèle. Trois humains différents ont également évalué chacun des échantillons. Tous ont été notés de 1 à 5, avec 5 comme note maximale, correspondant au fait que le texte est totalement associé à son sentiment. Les résultats donnent le graphique suivant : [caption id="attachment_29749" align="aligncenter" width="546"] En abscisse : la taille du modèle ; en ordonnée : adhérence des valeurs spécifiées, telles que jugées par les humains.[/caption]
Les évaluations humaines montrent que les modèles axés sur les valeurs issues de l'ensemble de données conçues par les chercheurs semblent plus adhérer au comportement spécifié. Plus le modèle possède de paramètres, plus le processus semble efficace. Les chercheurs du projet précisent :
"Notre analyse montre une amélioration comportementale statistiquement significative sans compromettre les performances sur les tâches en aval. Cela montre également que notre processus est plus efficace avec des modèles plus grands, ce qui implique que les gens pourront utiliser relativement moins d'échantillons pour adapter le comportement des grands modèles de langage à leurs propres valeurs. Étant donné que définir des valeurs pour de grands groupes de personnes risque de marginaliser les voix des minorités, nous avons cherché à rendre notre processus relativement évolutif par rapport à une reconversion à partir de zéro."Les équipes de recherche pensent que les modèles linguistiques doivent être adaptés à la société dans laquelle nous sommes et qu'il est important de prendre en compte sa diversité. Ils ajoutent également que pour réussir à concevoir des modèles de langage, les chercheurs en IA, les représentants de la communauté, les décideurs politiques, les spécialistes des sciences sociales, etc. puissent se réunir pour comprendre ensemble l'utilisation que le monde souhaite faire de ces outils. D'un point de vue plus pratique, cette étude permet à OpenAI de réaffirmer sa vision de la pertinence d'un grand modèle de TAL généraliste, parfois accusé d'être trop généraliste pour être réellement exploitable, en mettant en avant la possibilité de l'adapter à des contextes précis.