
En juin 2023, Lisa Su, la CEO d’AMD, dévoilait le GPU Instinct MI300X, conçu pour l’IA générative et le HPC. Ce processeur graphique de nouvelle génération a démontré des performances impressionnantes lors des benchmarks MLPerf Inference v4.1, confirmant sa capacité à rivaliser avec les solutions de pointe de l’industrie, notamment le NVIDIA H100. Ces résultats marquent une avancée significative pour AMD, mettant en lumière la robustesse et la polyvalence de sa plateforme d'inférence full-stack.
 La clé du succès du MI300X réside dans plusieurs facteurs :
La clé du succès du MI300X réside dans plusieurs facteurs :
 Dans certains cas, le MI300X a même dépassé le H100, notamment grâce à l'optimisation du traitement des LLMs. Cette réussite positionne AMD comme un concurrent sérieux sur le marché des accélérateurs d'IA, où NVIDIA domine.
La société déclare sur LinkedIn :
Dans certains cas, le MI300X a même dépassé le H100, notamment grâce à l'optimisation du traitement des LLMs. Cette réussite positionne AMD comme un concurrent sérieux sur le marché des accélérateurs d'IA, où NVIDIA domine.
La société déclare sur LinkedIn :
L'importance des benchmarks MLPerf
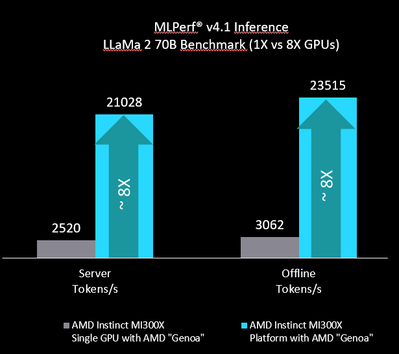
Les benchmarks MLPerf, développés par MLCommons, sont essentiels pour évaluer la performance des matériels et logiciels d'intelligence artificielle (IA). Alors que les modèles de langage deviennent de plus en plus complexes, la nécessité d’une puissance de calcul efficace et d’une optimisation logicielle rigoureuse devient primordiale. Pour les entreprises, performer dans ces benchmarks fournit des preuves tangibles de l'efficacité de leurs solutions d'IA dans des scénarios d'inférence et d'entraînement.Performances de l'AMD Instinct MI300X avec LLaMA2-70B
La soumission du GPU AMD Instinct MI300X au benchmark MLPerf Inference v4.1 a utilisé le modèle de langage LLaMA2-70B, reconnu pour ses performances élevées et sa polyvalence dans des applications réelles comme le traitement du langage naturel. Quatre tests ont été réalisés avec le GPU fonctionnant sur un système Supermicro AS-8125GS-TNMR2 dans deux scénarios distincts- deux dans le scénario hors ligne, destiné à maximiser le débit de traitement en jetons par seconde ;
- les deux autres dans le scénario de serveur, visant à simuler des requêtes en temps réel avec des contraintes de latence strictes.
Optimisations et Innovations
Instinct MI300X, compte 153 milliards de transistors, 192 Go de mémoire HBM3 à large bande passante et 12 chiplets. Le GPU dispose également d’une bande passante mémoire de 5,2 TB/s et de 896 Go/s de bande passante Infinity Fabric.
La clé du succès du MI300X réside dans plusieurs facteurs :
- Grande capacité mémoire : Avec 192 Go de mémoire HBM3, le GPU peut traiter des modèles de grande taille sans avoir besoin de les distribuer entre plusieurs unités, ce qui optimise le débit d'inférence ;
- Support du FP8 : AMD a intégré le format numérique FP8 dans sa pile logicielle ROCm, permettant une quantification précise des modèles sans perte significative de performance ;
- Optimisations logicielles : L'équipe d'AMD a travaillé sur l'optimisation du noyau, l'amélioration des algorithmes de planification dans vLLM, et l'amélioration de la gestion du cache KV, tout cela contribuant à une performance plus fluide et plus rapide.
Comparaison avec NVIDIA H100
La combinaison des GPU AMD Instinct MI300X et des processeurs AMD EPYC de 4ème génération montre une synergie efficace, optimisant les performances pour les charges de travail d’IA. Les performances de cette configuration sont très proches de celles du NVIDIA DGX H100, avec une différence de seulement 2 à 3 % dans les scénarios de serveur et hors ligne, en utilisant une précision FP8.
Dans certains cas, le MI300X a même dépassé le H100, notamment grâce à l'optimisation du traitement des LLMs. Cette réussite positionne AMD comme un concurrent sérieux sur le marché des accélérateurs d'IA, où NVIDIA domine.
La société déclare sur LinkedIn :
"De sa mémoire GPU massive, qui s’adapte à l’ensemble du modèle LLaMA2-70B sur un seul GPU avec de l’espace à revendre, à la prise en charge avancée de FP8 et aux optimisations logicielles de pointe, nous avons repoussé les limites des performances de l’IA. Exceller dans MLPerf Inference v4.1 est une étape importante pour AMD, soulignant notre engagement en faveur de la transparence et de la fourniture de données standardisées qui permettent aux entreprises de prendre des décisions éclairées".
AMD prévoit de lancer les prochaines itérations de la série AMD Instinct, avec entre autres avancées, de la mémoire supplémentaire, la prise en charge de types de données de faible précision et une puissance de calcul accrue, dans les prochains mois. Les futures versions de ROCm apporteront des améliorations logicielles, notamment des améliorations du noyau et une prise en charge avancée de la quantification.