
Google DeepMind a récemment présenté RT-2, un nouveau modèle vision-langage-action (VLA) qui permet aux robots de comprendre et d'effectuer plus facilement des actions, que ce soit dans des situations familières ou totalement nouvelles.
Les robots doivent être capables de gérer des tâches complexes et abstraites dans des environnements très variables, y compris dans des situations auxquelles ils n'ont jamais été confrontés.
Selon Google, Robotics Transformer 2, ou RT-2, est un modèle de vision-langage-action unique en son genre. Basé sur Transformer, l'architecture de réseau neuronal basée sur un mécanisme d’auto-attention présentée par Google Research en 2017, il a été entraîné sur du texte et des images du Web et peut contrôler un robot..
RT-2 repose sur le modèle Robotic Transformer 1 (RT-1), qui a été entraîné à partir de démonstrations multitâches et a la capacité d'apprendre à partir d'associations de tâches et d'objets observées dans les données robotiques. Les chercheurs de Google avaient ainsi utilisé des ensembles de données de démonstrations robotiques collectés en utilisant 13 robots pendant 17 mois.
Alors que RT-1 était basé sur le programme de langage et de vision, EfficientNet-B3, un modèle pré-entraîné sur ImageNet, RT-2 s'appuie sur les VLM PaLI-X et PaLM-E, qui permettent aux robots de mieux appréhender leur environnement.
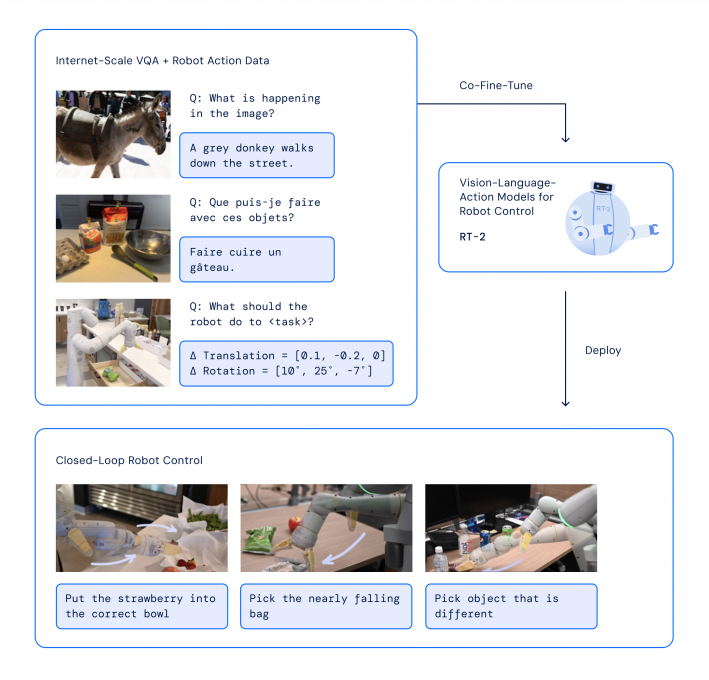 Le modèle RT-2 démontre des compétences accrues de généralisation, ainsi qu'une compréhension sémantique et visuelle qui dépasse les données robotiques qui lui ont été présentées, il est capable d'interpréter de nouvelles instructions et de répondre aux commandes des utilisateurs en effectuant un raisonnement rudimentaire. Ce raisonnement peut inclure la catégorisation d'objets ou la compréhension de descriptions globales.
L'intégration d'un raisonnement en chaîne permet à RT-2 d'effectuer ce raisonnement sémantique en plusieurs étapes. Par exemple, il peut décider quel objet pourrait être utilisé comme marteau improvisé (comme une pierre), ou déterminer le type de boisson le plus approprié pour une personne fatiguée (comme une boisson énergisante).
Avec une petite quantité de données d’entraînement de robots, le système est capable de transférer des concepts intégrés dans ses données d’apprentissage du langage et de la vision pour diriger les actions du robot, même pour des tâches pour lesquelles il n’a jamais été entraîné comme ci-dessous.
Le modèle RT-2 démontre des compétences accrues de généralisation, ainsi qu'une compréhension sémantique et visuelle qui dépasse les données robotiques qui lui ont été présentées, il est capable d'interpréter de nouvelles instructions et de répondre aux commandes des utilisateurs en effectuant un raisonnement rudimentaire. Ce raisonnement peut inclure la catégorisation d'objets ou la compréhension de descriptions globales.
L'intégration d'un raisonnement en chaîne permet à RT-2 d'effectuer ce raisonnement sémantique en plusieurs étapes. Par exemple, il peut décider quel objet pourrait être utilisé comme marteau improvisé (comme une pierre), ou déterminer le type de boisson le plus approprié pour une personne fatiguée (comme une boisson énergisante).
Avec une petite quantité de données d’entraînement de robots, le système est capable de transférer des concepts intégrés dans ses données d’apprentissage du langage et de la vision pour diriger les actions du robot, même pour des tâches pour lesquelles il n’a jamais été entraîné comme ci-dessous.

Le modèle RT-2 démontre des compétences accrues de généralisation, ainsi qu'une compréhension sémantique et visuelle qui dépasse les données robotiques qui lui ont été présentées, il est capable d'interpréter de nouvelles instructions et de répondre aux commandes des utilisateurs en effectuant un raisonnement rudimentaire. Ce raisonnement peut inclure la catégorisation d'objets ou la compréhension de descriptions globales.
L'intégration d'un raisonnement en chaîne permet à RT-2 d'effectuer ce raisonnement sémantique en plusieurs étapes. Par exemple, il peut décider quel objet pourrait être utilisé comme marteau improvisé (comme une pierre), ou déterminer le type de boisson le plus approprié pour une personne fatiguée (comme une boisson énergisante).
Avec une petite quantité de données d’entraînement de robots, le système est capable de transférer des concepts intégrés dans ses données d’apprentissage du langage et de la vision pour diriger les actions du robot, même pour des tâches pour lesquelles il n’a jamais été entraîné comme ci-dessous.
Les résultats
RT-2 montre que les modèles de langage de vision (VLM) peuvent être transformés en puissants modèles de vision-langage-action (VLA), qui peuvent contrôler directement un robot en combinant la pré-formation VLM avec des données robotiques. Dans toutes les catégories, les chercheurs ont observé une augmentation des performances de généralisation (amélioration de plus de 3x) par rapport aux lignes de base précédentes, telles que les modèles RT-1 précédents et les modèles comme Visual Cortex (VC-1), qui ont été pré-entraînés sur de grands ensembles de données visuelles. RT-2 a conservé les performances sur les tâches originales vues dans les données du robot et a amélioré les performances sur des scénarios inédits, et ce, jusqu'à 32%. Pour Google DeepMind :"RT-2 n’est pas seulement une modification simple et efficace par rapport aux modèles VLM existants, mais montre également la promesse de construire un robot physique à usage général capable de raisonner, de résoudre des problèmes et d’interpréter des informations pour effectuer un large éventail de tâches dans le monde réel".
Vincent Vanhoucke, chercheur et responsable de la robotique chez Google DeepMind, conclut :"Bien qu’il reste encore énormément de travail à faire pour permettre aux robots utiles de se déplacer dans des environnements centrés sur l’humain, RT-2 nous montre un avenir passionnant pour la robotique à portée de main".
Références : Blog Vincent Vanhoucke DeepMind Retrouver l'étude : "RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control"