
Ronny Votel et Na Li de Google Research ont annoncé sur le blog Tensorflow la publication d'un nouveau modèle de détection de postures intitulé MoveNet. Le modèle est compatible avec TensorFlow.js, le portage en Javascript de Tensorflow. La plateforme est capable d'analyser une image afin de fournir des données précises sur la plupart des poses qu'une personne peut réaliser. Ces informations peuvent être utilisées dans un cadre médical, sportif ou tout simplement pour améliorer son confort quotidien.
 À terme, l'outil pourra être exploité par les hôpitaux, l'armée ou les compagnies d'assurance pour permettre à des personnes ayant besoin de soins particuliers de les réaliser correctement et potentiellement à distance. Ryan Eder, fondateur et CEO d'IncludeHealth fait référence à cette possibilité dans ses propos :
À terme, l'outil pourra être exploité par les hôpitaux, l'armée ou les compagnies d'assurance pour permettre à des personnes ayant besoin de soins particuliers de les réaliser correctement et potentiellement à distance. Ryan Eder, fondateur et CEO d'IncludeHealth fait référence à cette possibilité dans ses propos :
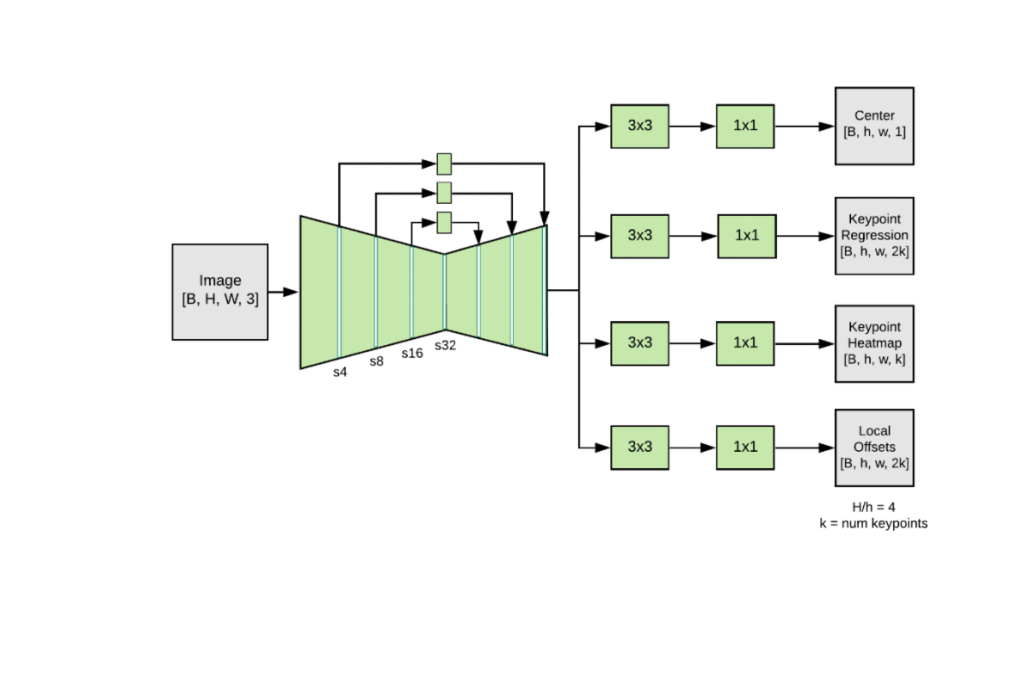 Chacune des têtes est à l'origine d'une étape de la séquence d'opérations qui permet le fonctionnement du modèle et donc, de définir l'ensemble des 17 points clés d'une posture :
Chacune des têtes est à l'origine d'une étape de la séquence d'opérations qui permet le fonctionnement du modèle et donc, de définir l'ensemble des 17 points clés d'une posture :

Une application pour fournir des soins à distance
MoveNet a été créé dans le cadre d'une collaboration avec IncludeHealth, une entreprise spécialisée dans la santé numérique. L'application offre la possibilité à un utilisateur d'analyser le positionnement de 17 points clés du corps humain. Grâce à cela, il pourrait être envisagé de proposer des soins à distance pour des patients ne pouvant pas se déplacer directement chez un kinésithérapeute par exemple. L'application guide les patients à travers une série de mouvements à réaliser quasi quotidiennement nommés "routines". Elles sont élaborées numériquement et prescrites par des physiothérapeutes afin de tester l'équilibre d'une personne ainsi que la force et l'amplitude des mouvements qu'il réalise. En parallèle, MoveNet analyse l'ensemble des points clés pour vérifier si le patient effectue correctement le mouvement.
À terme, l'outil pourra être exploité par les hôpitaux, l'armée ou les compagnies d'assurance pour permettre à des personnes ayant besoin de soins particuliers de les réaliser correctement et potentiellement à distance. Ryan Eder, fondateur et CEO d'IncludeHealth fait référence à cette possibilité dans ses propos :
"Le modèle MoveNet allie la vitesse à la précision, deux aspects nécessaires pour fournir des soins prescriptifs. Alors que d'autres modèles sont soit rapides, soit précis, MoveNet possède cet équilibre unique qui permettra d'insuffler la prochaine génération de prestation de soins. L'équipe Google a été un collaborateur fantastique dans cette quête."
L'architecture et le fonctionnement de MoveNet
Le modèle, proposé sur TensorFlow Hub, se décline en deux variantes selon les cas d'usage :- Lightning, destiné aux applications à latence critique.
- Thunder, pour les applications nécessitant une plus grande précision.
Chacune des têtes est à l'origine d'une étape de la séquence d'opérations qui permet le fonctionnement du modèle et donc, de définir l'ensemble des 17 points clés d'une posture :
- Carte thermique globale : prédiction du centre de gravité d'une personne. Cette donnée est ensuite prise en compte par les autres têtes prédictives.
- Champ de régression des points clés : En fonction du centre de gravité, le modèle fait la prédiction de l'ensemble des points clés d'une personne en fonction de sa position à l'instant T.
- Carte thermique des points clés : grâce au champ de régression, le système prédit ensuite l'emplacement de tous les points clés d'une personne, en ne prenant en compte que la personne en premier plan.
- Champ de décalage bidimensionnel : L'ensemble final des points clés est sélectionné en prenant en compte les prédictions de décalage 2D locales pour affiner le résultat final.
MoveNet : un modèle destiné à s'exécuter dans le navigateur
MoveNet a été entrainé l'aide de deux bases de données. La première intitulée COCO, est plus utile pour des postures plus naturelles, tandis que la seconde nommée Active, propre à Google, convient à une application pour la danse ou le fitness. Cette deuxième base de données a été conçue en étiquetant l'ensemble des points clés de personnes figurant sur des vidéos de yoga, de fitness ou de danse disponibles sur YouTube tout en s'inspirant des 17 points clés déjà identifiés par COCO. Afin d'assurer une exécution rapide avec TensorFlow.js, l'ensemble des sorties du modèle ont été regroupées dans un seul tenseur de sortie. De plus, le nombre de filtres de convolution utilisés dans chaque tête de prédiction a été grandement réduit afin d'améliorer les performances du modèle. 192 x 192 entrées (pour Lightning) ou 256 x 256 entrées (pour Thunder) sont exploitées par le modèle dans la même optique. Combiné à une caméra haute vitesse, le modèle peut même appliquer un lissage des points clés. Un filtre non linéaire est également utilisé pour supprimer les interférences haute fréquence et les valeurs anormales que pourraient générer des mouvements rapides, tout en maintenant un débit de bande passante élevée. Dans un avenir proche, les auteurs de MoveNet souhaitent qu'il puisse suivre le mouvement de plusieurs personnes à la fois pour qu'il soit utilisable en groupe. Sa compatibilité avec Tensorflow.js permet d'entrevoir une large diffusion du modèle et une multitude de cas d'usage puisqu'il peut s'exécuter directement depuis le navigateur. Il est d'ailleurs possible de le tester ici. Son intégration sur une page web ne nécessite que quelques lignes de Javascript : Chargement des librairies<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-core"></script> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter"></script> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-webgl"></script> <script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/pose-detection"></script>Création d'un détecteur :
const detector = await poseDetection.createDetector(poseDetection.SupportedModels.MoveNet);Transmission du flux vidéo au détecteur et estimation de la position :
const video = document.getElementById('video');
const poses = await detector.estimatePoses(video);
poses donne alors un tableau d'objets dont il est alors très simple d'obtenir les points-clés :
console.log(poses[0].keypoints);
// Outputs:
// [
// {x: 230, y: 220, score: 0.9, name: "nose"},
// {x: 212, y: 190, score: 0.8, name: "left_eye"},
// ...
// ]
Bien sûr, la compatibilité avec TensorFlow.js ne limite pas à un usage dans le navigateur et le modèle peut tout à fait être embarqué dans des applications.