
“Les animaux humains et non humains semblent capables d’acquérir d’énormes quantités de connaissances de base sur la façon dont le monde fonctionne grâce à l’observation et à travers une quantité incompréhensible d’interactions d’une manière indépendante des tâches et non supervisée. On peut émettre l’hypothèse que ces connaissances accumulées peuvent constituer la base de ce que l’on appelle souvent le bon sens.”
Il ajoutait :"Et le bon sens peut être vu comme une collection de modèles du monde qui peuvent guider sur ce qui est probable, ce qui est plausible et ce qui est impossible".
Selon lui, pour construire une IA de niveau humain, les systèmes doivent ainsi apprendre des "modèles mondiaux". Sa vision est donc de créer des machines capables d’apprendre des modèles internes du fonctionnement du monde afin qu’elles puissent apprendre beaucoup plus rapidement, planifier comment accomplir des tâches complexes et s’adapter facilement à des situations inconnues. L'équipe de recherche déclare :"Par exemple, nous entraînons un modèle de transformateur visuel de 632 millions de paramètres à l'aide de 16 GPU A100 en moins de 72 heures, et il atteint des performances de pointe pour la classification low-shot sur ImageNet, avec seulement 12 exemples étiquetés par classe. D'autres méthodes prennent généralement deux à 10 fois plus d'heures GPU et obtiennent des taux d'erreur plus faibles lorsqu'elles sont entraînées avec la même quantité de données".
Faire en sorte que les systèmes d'IA apprennent et raisonnent comme les animaux et les humains avec un apprentissage auto-supervisé
Les chercheurs de Meta AI ont développé des algorithmes d'apprentissage qui capturent les connaissances de base du sens commun sur le monde, puis les codent dans une représentation numérique à laquelle l'algorithme peut accéder plus tard. Pour être efficace, le système doit apprendre ces représentations de manière auto-supervisée, directement à partir de données non étiquetées telles que des images ou des sons, plutôt qu'à partir d'ensembles de données étiquetés assemblés manuellement. Les architectures génératives apprennent en supprimant ou en déformant des parties de l'entrée du modèle' par exemple, en effaçant une partie d'une photo ou en masquant certains mots dans un passage de texte. Ils essaient ensuite de prédire les pixels ou les mots manquants. Le modèle I-JEPA vise à prédire la représentation d'une partie d'une entrée (telle qu'une image ou un morceau de texte) à partir de la représentation d'autres parties de la même entrée plutôt qu'en prédisant directement les valeurs des pixels.Une architecture prédictive d'intégration performante
Le but recherché était que la prédiction des informations manquantes dans une représentation abstraite soit la plus proche possible de la compréhension générale des gens. Par rapport aux méthodes génératives qui prédisent dans l'espace pixel/token, I-JEPA utilise des cibles de prédiction abstraites pour lesquelles les détails inutiles au niveau du pixel sont potentiellement éliminés, amenant ainsi le modèle à apprendre davantage de caractéristiques sémantiques. Un autre choix de conception pour guider I-JEPA vers la production de représentations sémantiques est la stratégie de masquage multi-blocs proposée. Les chercheurs ont ainsi démontré l'importance de prédire de grands blocs contenant des informations sémantiques (avec une échelle suffisamment grande), en utilisant un contexte informatif (distribué dans l'espace).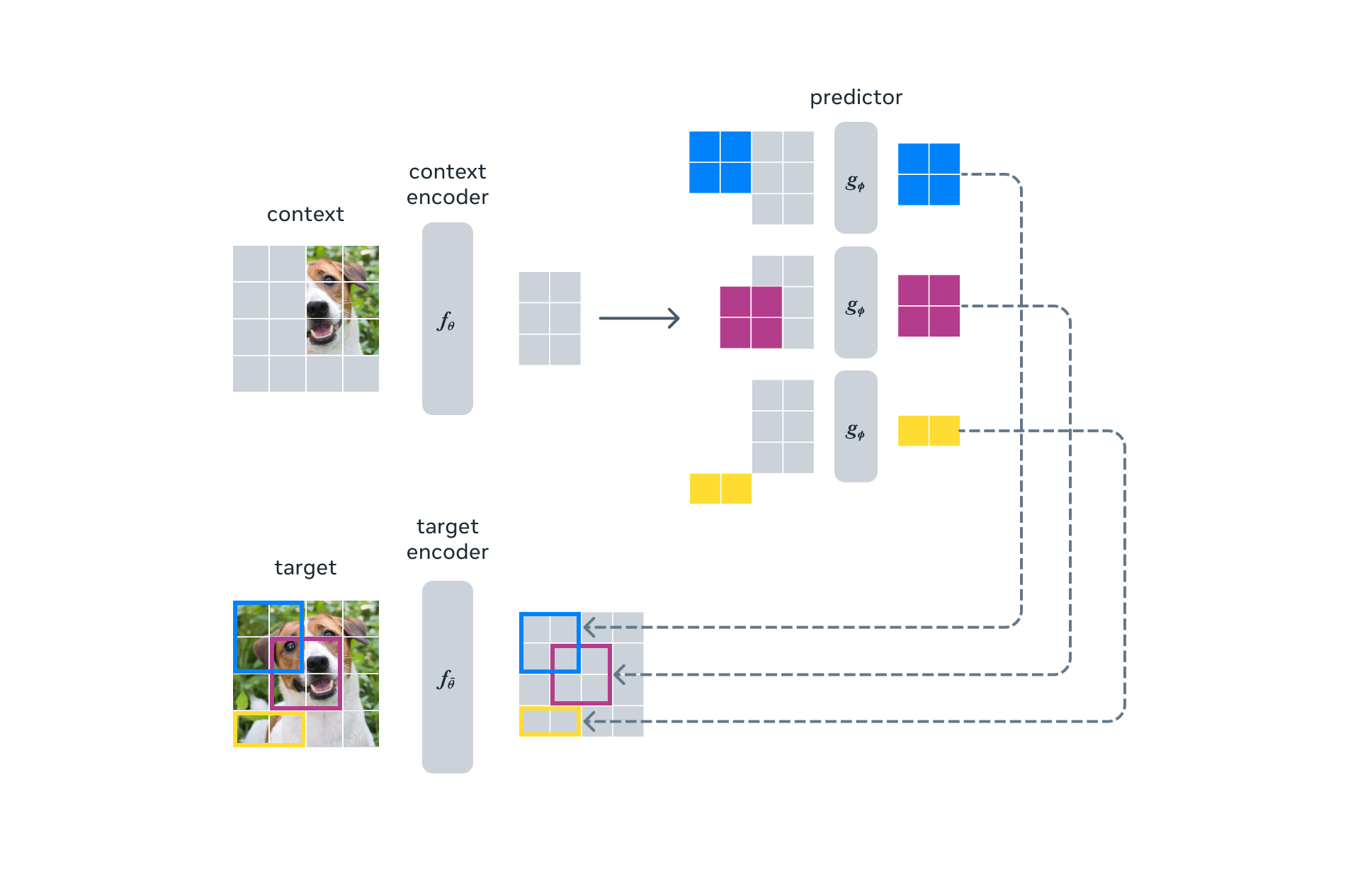 I-JEPA utilise un seul bloc de contexte pour prédire les représentations de différents blocs cibles provenant de la même image. L'encodeur de contexte, un Vision Transformer (ViT), ne traite que les patchs de contexte visibles. Le prédicteur, un ViT étroit, prend la sortie de l'encodeur de contexte et prédit les représentations d'un bloc cible à un emplacement spécifique, en fonction des jetons positionnels de la cible (affichés en couleur). Les représentations cibles correspondent aux sorties de l'encodeur-cible dont les poids sont mis à jour à chaque itération via une moyenne glissante exponentielle des poids de l'encodeur de contexte.
I-JEPA utilise un seul bloc de contexte pour prédire les représentations de différents blocs cibles provenant de la même image. L'encodeur de contexte, un Vision Transformer (ViT), ne traite que les patchs de contexte visibles. Le prédicteur, un ViT étroit, prend la sortie de l'encodeur de contexte et prédit les représentations d'un bloc cible à un emplacement spécifique, en fonction des jetons positionnels de la cible (affichés en couleur). Les représentations cibles correspondent aux sorties de l'encodeur-cible dont les poids sont mis à jour à chaque itération via une moyenne glissante exponentielle des poids de l'encodeur de contexte.
 Exemples de prédiction de parties d'images manquantes
Les chercheurs vont à présent travailler pour étendre l'approche JEPA à d'autres domaines, comme les données couplées image-texte et les données vidéo. Selon eux, "A l'avenir, les modèles JEPA pourraient avoir des applications intéressantes pour des tâches telles que la compréhension vidéo. Il s'agit d'une étape importante vers l'application et la mise à l'échelle de méthodes auto-supervisées pour l'apprentissage d'un modèle général du monde".
Références de l'article : Blog Meta AI
Retrouver l'article de recherche : https://doi.org/10.48550/arXiv.2301.08243
Code d'entraînement et points de contrôle du modèle.
Exemples de prédiction de parties d'images manquantes
Les chercheurs vont à présent travailler pour étendre l'approche JEPA à d'autres domaines, comme les données couplées image-texte et les données vidéo. Selon eux, "A l'avenir, les modèles JEPA pourraient avoir des applications intéressantes pour des tâches telles que la compréhension vidéo. Il s'agit d'une étape importante vers l'application et la mise à l'échelle de méthodes auto-supervisées pour l'apprentissage d'un modèle général du monde".
Références de l'article : Blog Meta AI
Retrouver l'article de recherche : https://doi.org/10.48550/arXiv.2301.08243
Code d'entraînement et points de contrôle du modèle.