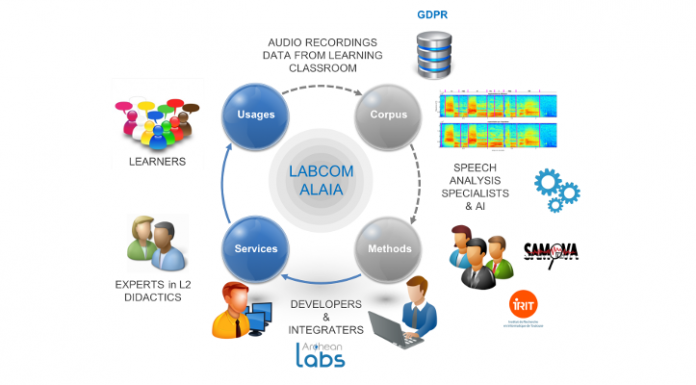
Le LabCom ALAIA, entre Archean Technologies et l’Institut de Recherche en Informatique de Toulouse (IRIT), travaille sur un programme de recherche et d’innovation dans le domaine des technologies informatiques pour l’apprentissage des langues étrangères, coordonné par Isabelle Ferrané (IRIT). Le projet, soutenu par l'ANR, a débuté en février 2019 pour une durée de 36 mois.
Le LabCom ALAIA, entre Archean Technologies et l’Institut de Recherche en Informatique de Toulouse (IRIT) vise à conduire un programme ambitieux de recherche et d’innovation dans le domaine des technologies informatiques pour l’apprentissage des langues étrangères.
Il explorera les techniques avancées d’intelligence artificielle (IA) pour le travail des compétences orales des apprenants — expression/compréhension orales. Ces techniques permettront de proposer, suivant les profils d’apprenants, les contenus (exercices/corrections) les plus adaptés et les plus efficaces pour l’acquisition de la langue cible.
Archean Technologies pourra, via le LabCom, développer des technologies en totale rupture avec les logiciels actuels d’apprentissage assisté par ordinateur et commercialiser ces solutions sous la forme de didacticiels, en mode B2C. L’IRIT, grâce à son expertise en IA et en analyse automatique de la parole, pourra exploiter les données mises à disposition par l’entreprise (enregistrements, données d’utilisation logicielle) dans le respect de la réglementation européenne sur la protection des données personnelles (RGPD). Ainsi, de nouveaux axes de recherche émergeront des problématiques de terrain. Les méthodes innovantes proposées seront exploitées au travers d’applications destinées aux apprenants, en organismes de formation ou en apprentissage en autonomie.
L’activité du LabCom s'insère parfaitement dans le volet innovation du plan pour la langue française et le plurilinguisme du 20 mars 2018, répondant aux urgences de formation linguistique des populations migrantes en France, pour leur insertion et accès à l’emploi. Initialement centré sur le français, le modèle proposé sera généralisé à d’autres langues cibles. De démonstrateurs en véritables solutions industrielles, les technologies développées suivront des jalons réguliers de développement et de production scientifique.
A court, moyen et long terme, le programme d’innovation du LabCom intégrera les multiples dimensions de l’apprentissage des langues :
- niveaux linguistiques : de la prononciation (phonétique-phonologie) aux niveaux lexico-grammatical, discursif et pragmatique ;
- authenticité des exercices : de tâches très contraintes (lecture/répétition) à la production spontanée ;
- précision visée : d’un travail global à un travail plus ciblé lié aux types d’erreurs détectées, à leur localisation et aux stratégies de remédiation possibles ;
- systèmes linguistiques source/cible : initiés pour le couple japonais/français et généralisés à d’autres couples de langues ;
- variété des apprenants et de leur niveau de compétences : interférences entre langue maternelle et langue cible ou difficultés de prononciation propres aux individus ;
- personnalisation des exercices de remédiation : grâce au potentiel discriminant des algorithmes d’IA et à la notion de profil ;
- modalités audiovisuelles : ressources complémentaires pour aider les populations non lettrées à se former et à appréhender des aspects plus socio-culturels.
- détection et localisation automatique d’erreurs à différents niveaux linguistiques ;
- caractérisation des erreurs en fonction de critères acoustiques, linguistiques, didactiques et choix de la stratégie de remédiation la plus adaptée ;
- production de feedback pour permettre à l’apprenant d’estimer sa performance, de mieux comprendre ses erreurs pour mieux les corriger ;
- saillance perceptive pour aider à renforcer le travail de production orale ;
- profilage automatique pour personnaliser l’apprentissage ;
- qualité de la production en situation d’interaction pour mesurer la capacité à communiquer avec un locuteur natif.