Meta annonce le lancement de Code Llama 70B, disponible dans les mêmes versions que les modèles Code Llama publiés le 24 août dernier : CodeLlama - 70B, le modèle de code fondamental, CodeLlama - 70B - Python, comme son nom l'indique, spécialisé en Python, et Code Llama - 70B - Instruct 70B, affiné pour comprendre les instructions en langage naturel. Tous trois, comme leurs prédécesseurs, sont gratuits pour la recherche et une utilisation commerciale.
Llama 2, le modèle présenté par Meta en juillet dernier a été affiné sur ses ensembles de données spécifiques au code pour concevoir “Code Llama”, une famille de modèles capables de générer du code informatique et du langage naturel lié au code, à partir d’invites en code ou en langage naturel.
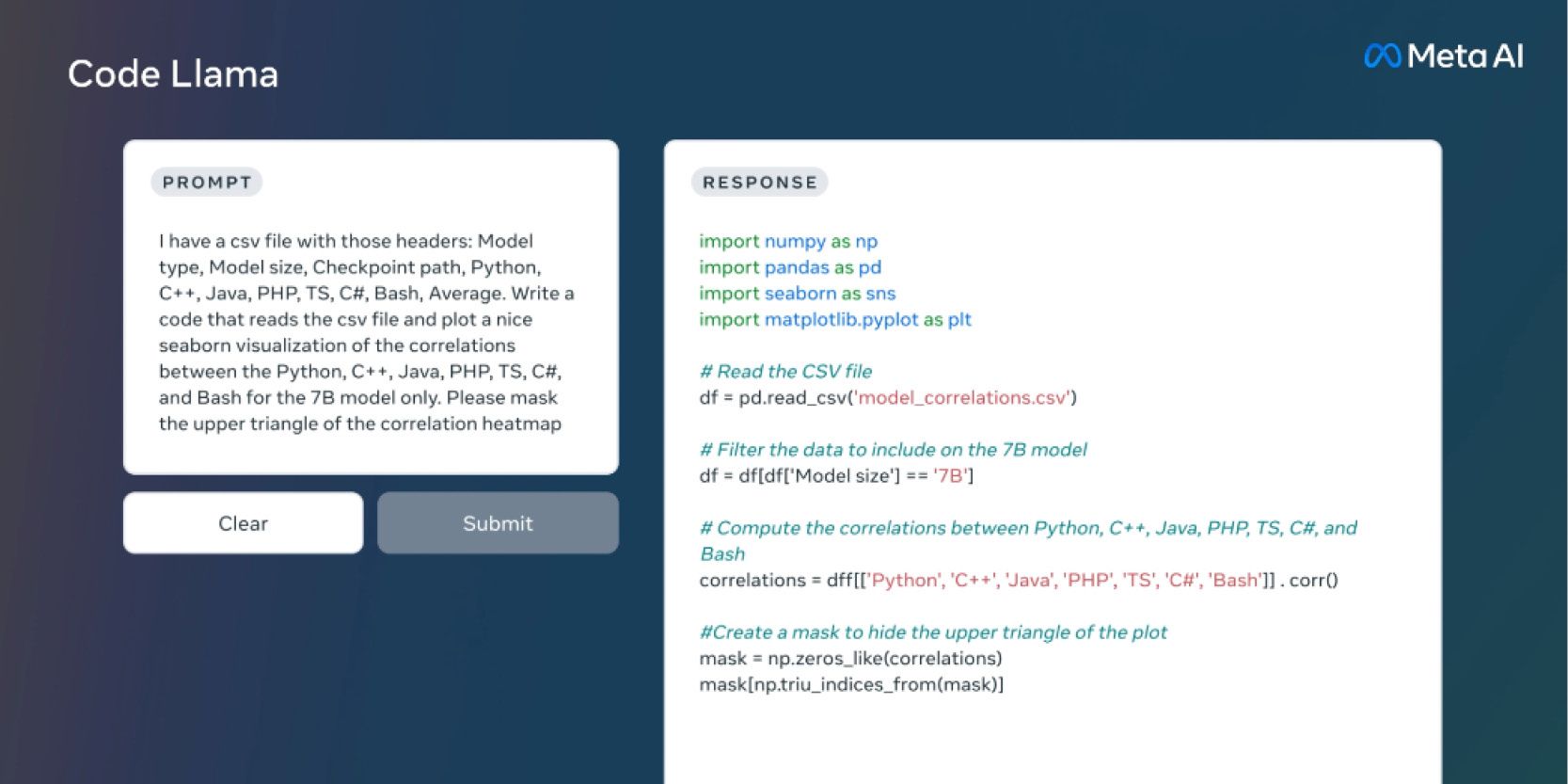
Code Llama, qui peut également être utilisé pour la complétion de code et le débogage, prend en charge la plupart des langages de programmation les plus populaires utilisés aujourd’hui, notamment Python, C ++, Java, PHP, Typescript (Javascript), C #, Bash.
En août dernier, le modèle était disponible en trois tailles: 7, 13 et 34 milliards de paramètres, la famille s'agrandit avec Code Llama 70B, le plus performant selon Meta. Les versions précédentes ont été entraînées sur 500 milliards de jetons de code et de données liées au code, la dernière sur 1000 milliards. Les modèles 7B et 13B ont également été formés avec la capacité de remplissage au milieu (FIM), ce qui leur permet d’insérer du code dans un code existant.
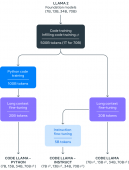 Les modèles répondent à différents besoins de service et de latence. Les modèles 34B et 70B donnent les meilleurs résultats et permettent une meilleure assistance au codage, mais les modèles plus petits de 7B, qui peut être servi sur un seul GPU, et 13B sont plus rapides et plus adaptés aux tâches nécessitant une faible latence, comme l'achèvement de code en temps réel.
Les modèles répondent à différents besoins de service et de latence. Les modèles 34B et 70B donnent les meilleurs résultats et permettent une meilleure assistance au codage, mais les modèles plus petits de 7B, qui peut être servi sur un seul GPU, et 13B sont plus rapides et plus adaptés aux tâches nécessitant une faible latence, comme l'achèvement de code en temps réel.

Les modèles répondent à différents besoins de service et de latence. Les modèles 34B et 70B donnent les meilleurs résultats et permettent une meilleure assistance au codage, mais les modèles plus petits de 7B, qui peut être servi sur un seul GPU, et 13B sont plus rapides et plus adaptés aux tâches nécessitant une faible latence, comme l'achèvement de code en temps réel.