
Développé par Meta AI, PyTorch est l’un des frameworks ML open source les plus utilisés. Soumith Chintala, l’un de ses créateurs, a annoncé le 12 septembre 2022, la création de la Fondation PyTorch au sein de la Linux Foundation, dont la principale mission est le développement collaboratif de logiciels open source. Le même jour, AMD (Advanced Micro Devices) fabricant américain de semi-conducteurs, microprocesseurs, cartes graphiques, annonçait qu’il rejoignait la Fondation PyTorch nouvellement créée en tant que membre fondateur. Tous deux partagent les mises à jour développées depuis.
La fondation Pytorch vise à démocratiser l’adoption des outils d’IA en favorisant et en soutenant un écosystème de projets open source avec PyTorch, le framework logiciel ML créé et encouragé à l’origine par Meta.
Son conseil d’administration se compose de représentants de Meta mais aussi, d’AMD, Amazon Web Services, Google, Microsoft et NVidia qui ont contribué à l’essor de PyTorch.
AMD, ainsi que les principaux développeurs de la base de code PyTorch, notamment ceux de Meta AI, ont fourni un ensemble de mises à jour de la plateforme logicielle ouverte ROCm qui apporte un support stable pour les accélérateurs AMD Instinct ainsi que de nombreux GPU Radeon.
Soumith Chintala déclare :
« Nous sommes ravis de voir l’impact significatif des développeurs d’AMD pour contribuer et étendre les fonctionnalités de PyTorch afin de rendre les modèles d’IA plus performants, efficaces et évolutifs. Un bon exemple de ceci est le leadership éclairé autour des approches de mémoire unifiée entre le framework et les futurs systèmes matériels, et nous sommes impatients de voir cette fonctionnalité progresser ».
Les améliorations progressives apportées à l’architecture AMD CDNA ainsi qu’à ROCm et PyTorch montrent une augmentation du débit du modèle GPU unique d’AMD Instinct MI100 vers les GPU de la famille AMD Instinct MI200 de dernière génération passant de ROCm 4.2 à ROCm 5.3 et de PyTorch 1.7 à PyTorch 1.12.
[caption id="attachment_42634" align="alignnone" width="800"]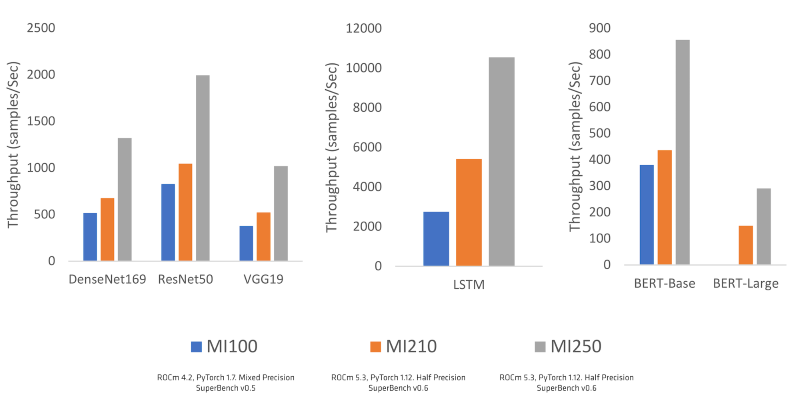 Performances du modèle ML sur génération à l’aide de Microsoft Superbench Suit[/caption]
Performances du modèle ML sur génération à l’aide de Microsoft Superbench Suit[/caption]
Performances du modèle ML sur génération à l’aide de Microsoft Superbench Suit[/caption]
Les principales mises à jour pour la prise en charge de ROCm depuis la version 1.12 de PyTorch
Intégration continue (IC) complète pour ROCm sur PyTorch
Avec le passage de la prise en charge ROCm de PyTorch de « Bêta » à « Stable », toutes les fonctions et fonctionnalités sont désormais vérifiées par un processus complet d’intégration continue (CI). Le processus CI permet de garantir le processus de construction et de test approprié avant une sortie attendue de la roue Docker et PIP avec des engagements stables à venir.Prise en charge de Kineto Profiler
L’ajout de la prise en charge du profileur Kineto au ROCm aide désormais les développeurs et les utilisateurs à comprendre les goulots d’étranglement des performances grâce à des outils de diagnostic et de profilage efficaces. L’outil fournit également des recommandations pour améliorer les problèmes connus et la visualisation via l’interface utilisateur TensorBoard.Prise en charge des bibliothèques clés de Pytorch
Les bibliothèques de l’écosystème PyTorch comme TorchText (classification de texte), TorchRec (bibliothèques pour les systèmes de recommandation - RecSys), TorchVision (Vision par ordinateur), TorchAudio (traitement audio et du signal) sont entièrement prises en charge depuis ROCm 5.1 et en amont avec PyTorch 1.12. Les bibliothèques clés fournies avec la pile logicielle ROCm, y compris MIOpen (modèles Convolution), RCCL (ROCm Collective Communications) et rocBLAS (BLAS pour transformateurs) ont été optimisées pour offrir de nouvelles efficacités potentielles et des performances supérieures. MIOpen innove sur plusieurs fronts :- la mise en œuvre de la fusion pour optimiser la bande passante mémoire et les frais généraux de lancement GPU;
- la fourniture d’une infrastructure de réglage automatique pour surmonter le grand espace de conception des configurations de problèmes;
- la mise en œuvre de différents algorithmes pour optimiser les circonvolutions pour différentes tailles de filtre et d’entrée.