
Après la génération d'images, celle d'audio, Stability AI, licorne basée à Londres et San Francisco, se lance dans celle de vidéos. Elle a présenté la semaine dernière le dernier ajout à sa suite de modèles open source : Stable Video Diffusion, basé sur le modèle text-to-image qui lui a apporté la notoriété, Stable Diffusion.
L'annonce de ce nouveau modèle de fondation, actuellement en preview, uniquement disponible à des fins de recherche, arrive tout juste un mois après celle de Stable Audio.
Stable Video Diffusion est un modèle de diffusion latente entraîné à générer de courts clips vidéo à partir d’un conditionnement d’image. Il se présente sous la forme de deux modèles image-to-video, SVD et SVD-XT : SVD qui génère 14 images par seconde à une résolution de 576 x 1024 avec une image contextuelle de la même taille tandis que SVD-XT porte le nombre d'images à 25.
Tous deux peuvent générer des clips de 4 secondes avec un nombre de 3 à 30 images par seconde (FPS) selon le choix de l’utilisateur et l'effet désiré. Le FPS mesurant la fluidité du mouvement vidéo, plus il est élevé, plus le mouvement semble lisse et naturel.
 Le modèle peut également générer ces clips à partir d'invites textuelles comme on peut le voir dans la vidéo ci-dessous.
[embed]https://youtu.be/G7mihAy691g?t=2[/embed]
Parallèlement à l'annonce de ce modèle, Stability AI a publié le papier de recherche qui souligne l'importance du choix des données pour obtenir un résultat de qualité.
L’équipe de Stability AI a utilisé un processus de curation systématique pour créer un ensemble de données d’entraînement composé de plus de 2 millions d’images et de plus de 300 000 vidéos provenant de sources variées comme Flickr, YouTube, Vimeo ...
Leur processus d'entraînement structuré comprend trois étapes : pré-entraînement texte-vers-image sur un ensemble de données diversifié, pré-entraînement vidéo à basse résolution, et ajustement fin sur des ensembles de données vidéo de haute qualité.
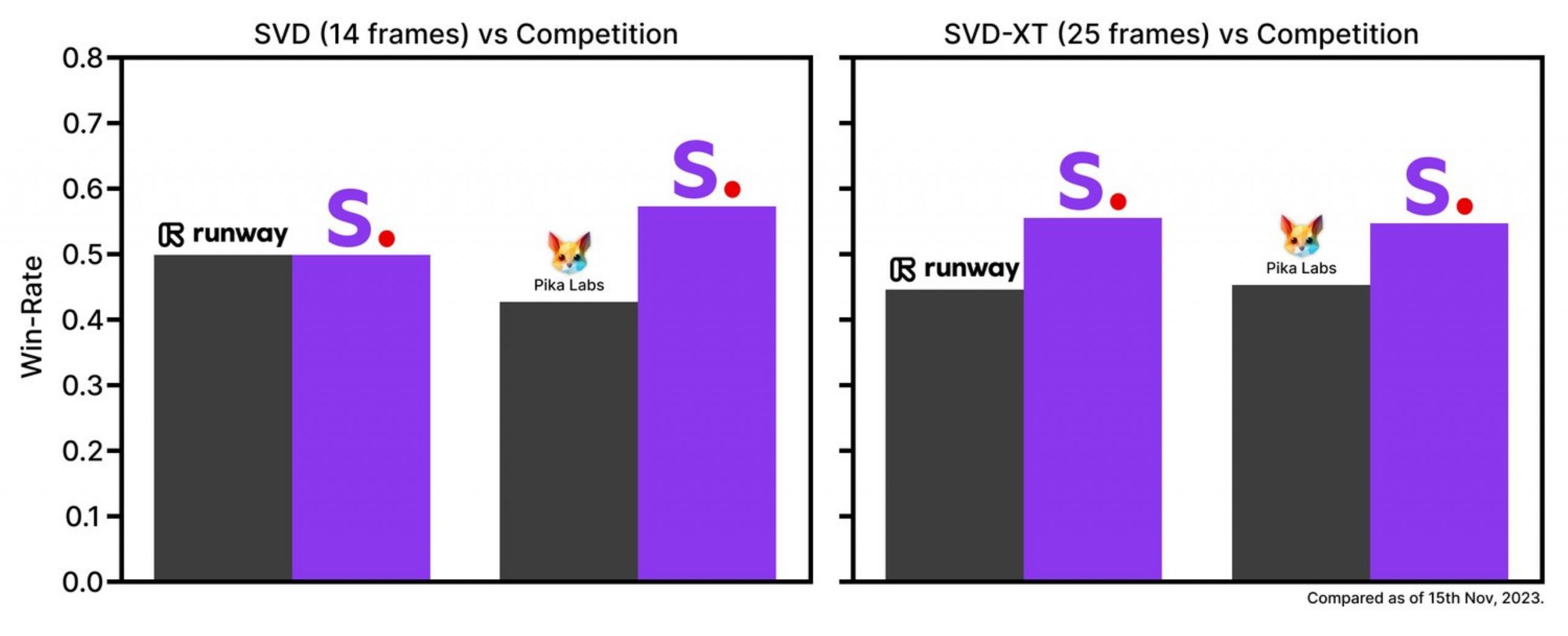
Dans des études de préférence utilisateur, il a surpassé les principaux modèles fermés Gen-2 de Runway et Pika Libs comme on peut le voir dans le graphique ci-dessous.
Le modèle peut également générer ces clips à partir d'invites textuelles comme on peut le voir dans la vidéo ci-dessous.
[embed]https://youtu.be/G7mihAy691g?t=2[/embed]
Parallèlement à l'annonce de ce modèle, Stability AI a publié le papier de recherche qui souligne l'importance du choix des données pour obtenir un résultat de qualité.
L’équipe de Stability AI a utilisé un processus de curation systématique pour créer un ensemble de données d’entraînement composé de plus de 2 millions d’images et de plus de 300 000 vidéos provenant de sources variées comme Flickr, YouTube, Vimeo ...
Leur processus d'entraînement structuré comprend trois étapes : pré-entraînement texte-vers-image sur un ensemble de données diversifié, pré-entraînement vidéo à basse résolution, et ajustement fin sur des ensembles de données vidéo de haute qualité.
Dans des études de préférence utilisateur, il a surpassé les principaux modèles fermés Gen-2 de Runway et Pika Libs comme on peut le voir dans le graphique ci-dessous.
Le modèle peut également générer ces clips à partir d'invites textuelles comme on peut le voir dans la vidéo ci-dessous.
[embed]https://youtu.be/G7mihAy691g?t=2[/embed]
Parallèlement à l'annonce de ce modèle, Stability AI a publié le papier de recherche qui souligne l'importance du choix des données pour obtenir un résultat de qualité.
L’équipe de Stability AI a utilisé un processus de curation systématique pour créer un ensemble de données d’entraînement composé de plus de 2 millions d’images et de plus de 300 000 vidéos provenant de sources variées comme Flickr, YouTube, Vimeo ...
Leur processus d'entraînement structuré comprend trois étapes : pré-entraînement texte-vers-image sur un ensemble de données diversifié, pré-entraînement vidéo à basse résolution, et ajustement fin sur des ensembles de données vidéo de haute qualité.
Dans des études de préférence utilisateur, il a surpassé les principaux modèles fermés Gen-2 de Runway et Pika Libs comme on peut le voir dans le graphique ci-dessous.
Limitations du modèle
Malgré une génération de vidéos de qualité, le modèle présente, selon les chercheurs, quelques limitations. Outre la durée des vidéos qui se limite pour l'instant à 4 secondes, il peut parfois générer des vidéos sans mouvement ou des panoramiques de caméra très lents. De plus, il a du mal à générer correctement les visages et les personnes, et à gérer les changements d’échelle, de perspective et d’illumination. Stability AI prévoit d'étendre les modèles SVD et SVD-XT, notamment avec un outil "texte-vidéo" qui apportera une invite textuelle aux modèles sur le Web. Stable Video Diffusion a des applications potentielles pour "la publicité, l’éducation, le divertissement et au-delà", ce qui lui permettra de le commercialiser. Le code de Stable Video Diffusion est disponible sur le dépôt GitHub de Stability AI, les poids requis pour exécuter le modèle localement peuvent être trouvés sur sa page Hugging Face. Il est possible de tester la création de vidéo à partir d’image en ligne à l’aide des solutions suivantes :- stable-video-diffusion sur Replicate qui permet de le tester en ligne et aussi de l’utiliser via une API.
- Ce Google Colab permet également de créer des vidéos sur le cloud (Cliquer sur Exécution → Tout exécuter et cliquez sur le lien
c0d34l34t01r3.gradio.livequi apparait environ 1 minute plus tard).