
L’apprentissage par renforcement (Reinforcement Learning) est une méthode de machine learning qui nécessite la plupart du temps une supervision et une instrumentation approfondies pour le monde réel. Des chercheurs de BAIR (Berkeley AI Research) l'ont appliqué à la robotique et présentent ReLMM, un système qui peut apprendre en continu à la fois la navigation et la manipulation, mais de manière autonome, sans intervention humaine ou instrumentation environnementale. Leur étude "Fully Autonomous Real-World Reinforcement Learning with Applications to Mobile Manipulation"a été publiée sur arXiv.
En robotique, le reinforcement learning est utilisé pour permettre au robot de créer un système de contrôle adaptatif efficace pour lui-même à partir de sa propre expérience. Contrairement à l'apprentissage automatique supervisé ou non supervisé automatique, l'agent autonome n'a pas ou très peu de données sur l'environnement où il se trouve.
Les chercheurs de BAIR ont étudié comment les manipulateurs mobiles peuvent apprendre de manière autonome les compétences que nécessitent une combinaison de navigation et de préhension. Ces difficultés ont souvent été évitées, limitant le robot à la manipulation ou à la navigation et recourant à l'intervention humaine pour fournir des démonstrations, des réinitialisations / randomisations de tâches et l’étiquetage des données pendant le processus de formation.
Ils ont conçu un système d’apprentissage, ReLMM, qui atteint cet objectif grâce à une politique modulaire de saisie et de navigation où l’incertitude sur la politique de préhension conduit à l’exploration, et la navigation n’est récompensée que par le succès de la saisie.
Ils ont évalué cette méthode sur une tâche de nettoyage, où le robot doit naviguer et ramasser des objets éparpillés sur le sol dans plusieurs pièces.
Après une brève phase de pré-entraînement (environ 40 heures dans le monde réel), le robot peut apprendre à naviguer et à nettoyer une pièce de manière autonome.
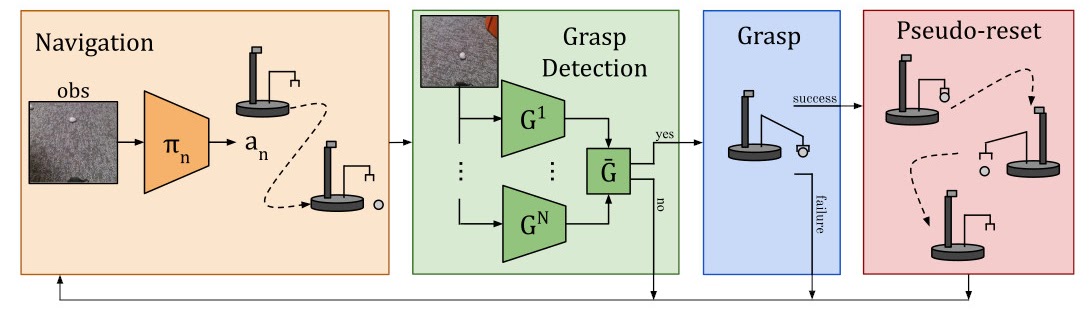 ReLMM partitionne le manipulateur mobile dans une politique de navigation et une seconde de préhension. Les deux sont récompensées lorsqu’un objet est saisi.
Les chercheurs ont formé un ensemble de politiques de préhension pour mesurer l’incertitude et concentrer l’exploration dans de nouveaux états.
Si le succès de la saisie est probable, une action de saisie est échantillonné à partir des prédicteurs de saisie et exécuté. Si la prise est réussie pendant l’entraînement, le robot exécute une pseudo-réinitialisation en replaçant l’objet collecté dans un emplacement aléatoire.
Les politiques ont été directement formées à partir de l’entrée de la caméra, ce qui leur a évité d'utiliser des cartes, des instruments ou un étiquetage humain. Les seules interventions humaines nécessaires pendant l’entraînement ont été d’échanger les batteries et d’éloigner les objets des positions insaisissables vers lesquelles ils auraient pu être poussés.
ReLMM partitionne le manipulateur mobile dans une politique de navigation et une seconde de préhension. Les deux sont récompensées lorsqu’un objet est saisi.
Les chercheurs ont formé un ensemble de politiques de préhension pour mesurer l’incertitude et concentrer l’exploration dans de nouveaux états.
Si le succès de la saisie est probable, une action de saisie est échantillonné à partir des prédicteurs de saisie et exécuté. Si la prise est réussie pendant l’entraînement, le robot exécute une pseudo-réinitialisation en replaçant l’objet collecté dans un emplacement aléatoire.
Les politiques ont été directement formées à partir de l’entrée de la caméra, ce qui leur a évité d'utiliser des cartes, des instruments ou un étiquetage humain. Les seules interventions humaines nécessaires pendant l’entraînement ont été d’échanger les batteries et d’éloigner les objets des positions insaisissables vers lesquelles ils auraient pu être poussés.
Vue d’ensemble de la méthode
ReLMM partitionne le manipulateur mobile dans une politique de navigation et une seconde de préhension. Les deux sont récompensées lorsqu’un objet est saisi.
Les chercheurs ont formé un ensemble de politiques de préhension pour mesurer l’incertitude et concentrer l’exploration dans de nouveaux états.
Si le succès de la saisie est probable, une action de saisie est échantillonné à partir des prédicteurs de saisie et exécuté. Si la prise est réussie pendant l’entraînement, le robot exécute une pseudo-réinitialisation en replaçant l’objet collecté dans un emplacement aléatoire.
Les politiques ont été directement formées à partir de l’entrée de la caméra, ce qui leur a évité d'utiliser des cartes, des instruments ou un étiquetage humain. Les seules interventions humaines nécessaires pendant l’entraînement ont été d’échanger les batteries et d’éloigner les objets des positions insaisissables vers lesquelles ils auraient pu être poussés.
Pourquoi le choix d'une politique modulaire ?
Les robots modulaires peuvent être configurés pour exécuter plusieurs fonctions. Les chercheurs ont encouragé le robot à donner la priorité à la formation de compétences de préhension avant l'acquisition de nouvelles compétences, ici pour la navigation. Cette méthode, plus efficace que l'apprentissage des deux compétences en même temps, présente deux avantages pour la robotique : un agent se concentrant sur l’apprentissage d’une compétence est plus efficace pour collecter des données autour de la distribution de l’état local pour cette compétence. Selon les chercheurs, le second avantage de cette approche est qu'ils peuvent inspecter les modèles entraînés pour différentes tâches et leur poser des questions, comme "pouvez-vous saisir tout objet maintenant?", ce qui s’avère utile pour l’entraînement de navigation. Un tel modèle estimant l’incertitude dans sa réussite de préhension peut être utilisé pour améliorer l’exploration de navigation (en évitant les aires ne comportant pas d’objets saisissables) mais aussi pour réétiqueter les données pendant l’entraînement au cas où le modèle de préhension n’aurait pas réussi à saisir un objet à sa portée... Les chercheurs ont évalué leur méthode sur différentes tâches dont la difficulté augmentait. le robot devait ramasser des formes indistinctes blanches uniformes qui se trouvent sur le sol sans qu’il y ait d’obstacles, tandis que d’autres pièces comportent des objets de formes et de couleurs diverses, des obstacles qui augmentent la difficulté de navigation et cachent les objets et des tapis à motifs qui rendent la visibilité des objets sur le sol difficile.Le système s'améliore au fil du temps, allant jusqu'à dépasser les systèmes codés à la main
Une limite importante des contrôleurs conçus à la main est qu’ils sont réglés pour une tâche particulière, par exemple, saisir des objets blancs. Lorsque divers objets aux couleurs et aux formes différentes sont introduits, le réglage initial peut ne plus être optimal. ReLMM est en mesure de s’adapter à diverses tâches en recueillant sa propre expérience et finit par dépasser le contrôleur conçu à la main par les chercheurs, bien qu'experts en la matière. Ces derniers ont ainsi constaté que le robot était de plus en plus performant, allant jusqu'à dépasser la politique prédéfinie quant à la préhension rapide des objets qui se trouvent dans la pièce. Références : "Fully Autonomous Real-World Reinforcement Learning with Applications to Mobile Manipulation" arXiv:2107.13545v3Auteurs : Charles Sun, Jędrzej Orbik, Coline Devin, Brian Yang, Abhishek Gupta, Glen Berseth, Sergey Levine.
Affiliation : Berkeley AI Research