Le mois dernier, FAIR présentait SaLinA, une librairie légère utilisant notamment une approche basée sur des agents pour mettre en œuvre des modèles de décision séquentiels, y compris (mais pas seulement) des algorithmes reinforcement learning. Pour en savoir plus, nous avons échangé avec Ludovic Denoyer, chercheur scientifique à FAIR Paris - précédemment professeur à Sorbonne Université - et auteur avec Alfredo de la Fuente, Song Duong, Jean-Baptiste Gaya, Pierre-Alexandre Kamienny et Daniel H. Thompson de SaLinA.
ActuIA : En quoi consiste la librairie SaLinA ?
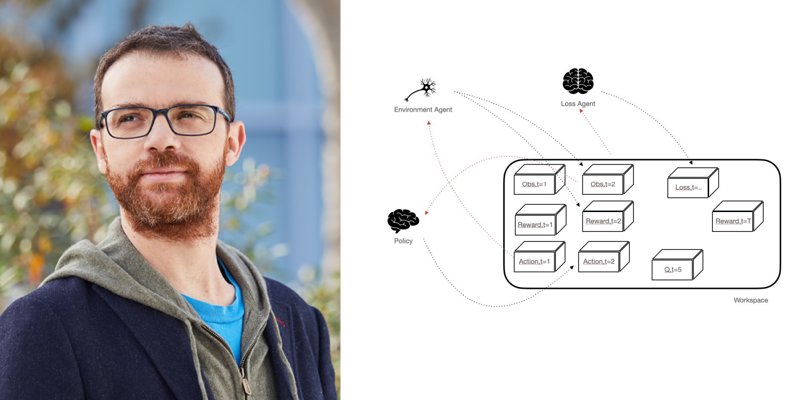
Ludovic Denoyer : La librairie SaLinA est une librairie légère qui peut être vue comme une extension de PyTorch permettant la prise en compte de la séquentialité dans le processus de traitement d’information. Elle permet de rajouter à PyTorch la capacité de naturellement prendre en compte la dimension temporelle dans les données et les traitements et fournit un cadre pour l'implémentation de systèmes de décision séquentiels, particulièrement d’algorithmes d’apprentissage par renforcement.
Quel est l'intérêt de l'approche basée sur des agents pour cette librairie ?
Concrètement, là ou PyTorch permet de composer des ‘modules’ afin de construire des réseaux de neurones complexes, SaLinA permet de composer des ‘agents’ pour construire des agents complexes, un agent correspondant à un modèle séquentiel. De plus, là ou PyTorch établit une séparation claire entre modèle et données (par l’utilisation de différentes classes comme les DataLoader), SaLinA unifie complètement ces deux aspects, les données tout comme les prédictions étant générées par des agents. Par exemple, c’est un agent qui s’occupe de charger les données d’un dataset en mémoire, ou bien c’est aussi un agent qui modélise un environnement d’apprentissage.
Cette unification a deux avantages : elle simplifie grandement la compréhension des codes produits (une seule abstraction), et elle permet de modéliser des cadres complexes d’apprentissage, comme par exemple le model-based RL ou bien le batch-RL qui peuvent être traités simplement en changeant les agents impliqués dans le processus d’apprentissage, sans changer l’algorithme lui même. On obtient ainsi une séparation nette entre l’algorithme d’apprentissage et l’architecture des modèles engagés dans cet apprentissage (comme PyTorch l’autorise en deep learning classique), ce qui est une caractéristique majeure de la librairie, là ou les autres librairies d’apprentissage par renforcement proposent usuellement des algorithmes spécifiques à certaines architectures.
Concrètement, tous les algorithmes que nous fournissons avec SaLinA fonctionnent avec des perceptrons, des réseaux de neurones récurrents, des transformers, sans besoin de changer le code de l’algorithme.
Malgré l'influence forte du reinforcement learning dans la conception même de SaLinA, son utilisation ne se limite pas au RL. Quelles sont ses utilisations possibles ?
Aujourd’hui, deux mondes coexistent : les tenants de l’apprentissage supervisé qui modélisent leurs processus de décision à travers des fonctions dites « atomiques » apprises sur des jeux de données, et les tenants de l’apprentissage par renforcement qui modélisent des processus séquentiels en interaction avec des environnement. SaLinA crée un pont entre les deux mondes, autorisant par exemple le développement d’algorithmes séquentiels sur des jeux de données, ou sur des mélanges d’environnements et de données.
Du point de vue des chercheurs en apprentissage supervisé, cela ouvre la possibilité de développer des algorithmes plus séquentiels (e.g des modèles de cascade par exemple, ou des modèles d’attention complexes). Du côté des chercheurs en apprentissage par renforcement, cela facilite l’utilisation de données (e.g trajectoires collectées sur des utilisateurs), et augmente donc le champ des possibles. De plus, tout le monde peut utiliser la même librairie, et l'échange d’informations entre les communautés est donc simplifié.
La librairie SaLinA est actuellement très légère (300 lignes de code), mais le découplage et la structuration qu'elle permet facilitent tant l'expérimentation que l'industrialisation. La légèreté de la librairie est-elle au cœur de son ADN ou envisagez-vous de la faire évoluer progressivement vers un framework de plus en plus outillé ?
SaLinA est plus une extension de PyTorch - fournie avec de nombreux exemples d’algorithmes - qu’une librairie en tant que tel. Notre volonté est de la garder la plus simple possible, et de faire grandir le nombre des algorithmes l’utilisant. L'intérêt de la conserver aussi simple est d’une part d’en garder la facilité d’adoption, mais aussi de permettre l’utilisation de tous les outils de l'écosystème de PyTorch (e.g pytorch lightning). Ainsi, la mise en production d’algorithmes développés en SaLinA peut aujourd’hui être effectuée en utilisant les mêmes outils que la mise en production de modèles PyTorch, ce qui nous permet de nous focaliser sur le développement des algorithmes sans créer un nouvel écosystème dont la maintenance serait compliquée.
Les axes de développement sont doubles : d’une part le développement d’agents complexes (e.g transformers optimisés, agents en interaction avec des utilisateurs réels, etc.), et d’autre part l'implémentation de multiples algorithmes permettant de reproduire l'état de l’art, mais aussi pouvant servir de base à la construction de nouveaux modèles.
Un grand merci à Ludovic Denoyer ainsi qu'à FAIR pour leurs réponses.
Plus d'information : https://arxiv.org/pdf/2110.07910.pdf et https://github.com/facebookresearch/salina
PyTorch : La librairie SaLinA expliquée par Ludovic Denoyer (FAIR)
Acteurs cités
Sur le même sujet
Skills agentiques : quatre cadres de compétences pour LLM publiés en mai 2026, sans protocole commun
01/06/2026
Etude EPFL : les limites des LLMs face aux attaques adaptatives
23/12/2024
De la donnée à l’action : la trajectoire agentique de Qlik vers une intelligence décisionnelle intégrée
28/05/2025
L'Hebdo ActuIA
Inscription confirmée, à très vite !