
Meta présente MusicGen, un modèle de langage simple open source générant de la musique à partir d'invites textuelles et musicales. Similaire au modèle MusicLM de Google Research, MusicGen surpasserait celui-ci à la fois en termes de qualité audio et d’adhérence à la description textuelle fournie selon les auditeurs humains dans les évaluations de l'article de recherche publié sur arXiv.
Le document de recherche "Simple and Controllable Music Generation" a été publié le 8 juin dernier. Felix Kreuk, l'un des auteurs, l'annonçait sur Twitter le lendemain :
[embed]https://twitter.com/i/status/1667086356927901696[/embed]
MusicGen est un décodeur basé sur un transformateur auto-régressif à un étage entraîné avec un tokenizer EnCodec de 32 kHz publié précédemment par Meta et quatre livres de codes de 50 Hz. MusicGen, contrairement aux modèles précédents, ne nécessite pas de représentation sémantique auto-supervisée et crée les quatre livres de codes en même temps. Les chercheurs ont introduit un petit délai entre les livres de codes, ce qui se traduit par seulement 50 étapes audio auto-régressives par seconde.
Il a été entraîné sur 20 000 heures de musique sous licence, notamment sur 10 000 pistes musicales provenant de la base de données interne de Facebook, et 390 000 de Shutterstock et Pond5, une banque de musique en ligne.
MusicGen est disponible en trois tailles : 300M (millions) de paramètres, 1.5B (milliards) et 3.3B. Les 2 modèles plus grands fournissent un son de meilleure qualité, et bien que le modèle 1,5 B ait été le mieux noté par les humains, le modèle 3,3B s'est révélé le plus précis, avec des sorties audio très proches de la description fournie en entrée.
Ces trois modèles génèrent de la musique à partir d'invites textuelles, un 4ème modèle, lui aussi de 1,5B, nommé Melody, y associe des invites audio.
Après avoir testé leur modèle, les auteurs ont ensuite utilisé le benchmark MusicCaps, un ensemble de données composé de 5,5 K exemples et d’un sous-ensemble d’exemples 1 K équilibrés entre les genres, pour l'évaluer par rapport à Riffusion, Mousai, MusicLM et Noise2Music.
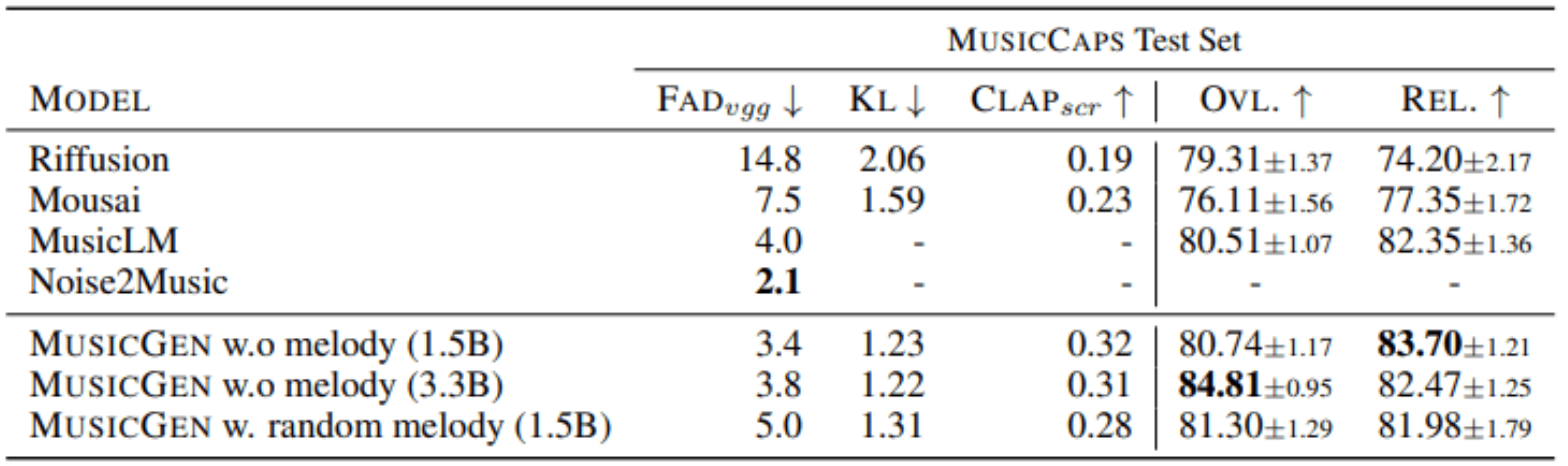 Ils ont comparé leurs métriques objectives et subjectives : FAD, la distance audio Fréchet , KL, la divergence de Kullback-Leibler et le Score CLAP. Les mesures subjectives concernent la qualité globale (OVL) et la pertinence de l'audio générée par rapport à l'invite textuelle évaluée par les humains (REL) notés de 1 à 100.
MusicGen s'est révélé plus performant que ces modèles.
Références :
Github: https://github.com/facebookresearch/audiocraft
Article arXiv :"Simple and Controllable Music Generation" https://arxiv.org/abs/2306.05284
Auteurs : Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, Alexandre Défossez.
Le code et les modèles sont disponibles sur GitHub
HuggingFace: https://huggingface.co/spaces/facebook/MusicGen
Ils ont comparé leurs métriques objectives et subjectives : FAD, la distance audio Fréchet , KL, la divergence de Kullback-Leibler et le Score CLAP. Les mesures subjectives concernent la qualité globale (OVL) et la pertinence de l'audio générée par rapport à l'invite textuelle évaluée par les humains (REL) notés de 1 à 100.
MusicGen s'est révélé plus performant que ces modèles.
Références :
Github: https://github.com/facebookresearch/audiocraft
Article arXiv :"Simple and Controllable Music Generation" https://arxiv.org/abs/2306.05284
Auteurs : Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, Alexandre Défossez.
Le code et les modèles sont disponibles sur GitHub
HuggingFace: https://huggingface.co/spaces/facebook/MusicGen
Ils ont comparé leurs métriques objectives et subjectives : FAD, la distance audio Fréchet , KL, la divergence de Kullback-Leibler et le Score CLAP. Les mesures subjectives concernent la qualité globale (OVL) et la pertinence de l'audio générée par rapport à l'invite textuelle évaluée par les humains (REL) notés de 1 à 100.
MusicGen s'est révélé plus performant que ces modèles.
Références :
Github: https://github.com/facebookresearch/audiocraft
Article arXiv :"Simple and Controllable Music Generation" https://arxiv.org/abs/2306.05284
Auteurs : Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, Alexandre Défossez.
Le code et les modèles sont disponibles sur GitHub
HuggingFace: https://huggingface.co/spaces/facebook/MusicGen