
Des chercheurs de l'Université de Californie, Berkeley, proposent une approche axée sur les données de points de contrôle de réseaux neuronaux pour optimiser ces derniers à l'aide de modèles génératifs entraînés sur ces paramètres. Leur étude intitulée « Learning to Learn with Generative Models of Neural Network Checkpoints » a été publiée sur arXiv fin septembre.
L’optimisation basée sur radient est le carburant de l’apprentissage profond moderne. Les méthodes d’optimisation basées sur le gradient telles que la descente de gradient stochastique (SGD, Robbins &Monro, 1951) ou Adam (Kingma &Ba, 2015) sont faciles à mettre en œuvre et obtiennent de très bons résultats, même dans les espaces de perte non convexes de grande dimension des réseaux neuronaux.
Au cours de la dernière décennie, elles ont permis des avancées impressionnantes, notamment en vision par ordinateur et traitement du langage naturel et, d'autre part, généré une quantité massive de points de contrôle de réseaux neuronaux. Cependant, elles souffrent d’une importante limitation : elles ne peuvent s’améliorer à partir de l’expérience passée. Par exemple, SGD ne converge pas plus rapidement lorsqu’il est utilisé pour optimiser une même architecture de réseau neuronal à partir de la même initialisation la 100ème fois que la première. Des optimiseurs apprenant à tirer parti de leurs expériences passées ont le potentiel de surmonter cette limitation et peuvent accélérer les progrès futurs du deep learning.
Le concept d'optimiseurs améliorés n’est pas nouveau et remonte au moins aux années 1980. Au cours des dernières années, des efforts importants ont été consacrés à la conception d’algorithmes qui apprennent via une méta-optimisation imbriquée, où la boucle interne optimise l’objectif au niveau de la tâche et la boucle externe apprend l’optimiseur. Certaines de ces approches se sont révélées plus performantes que les optimiseurs manuels mais leur dépendance vis à vis de l’optimisation non déroulée et de l’apprentissage par renforcement les rend difficiles à former dans la réalité.
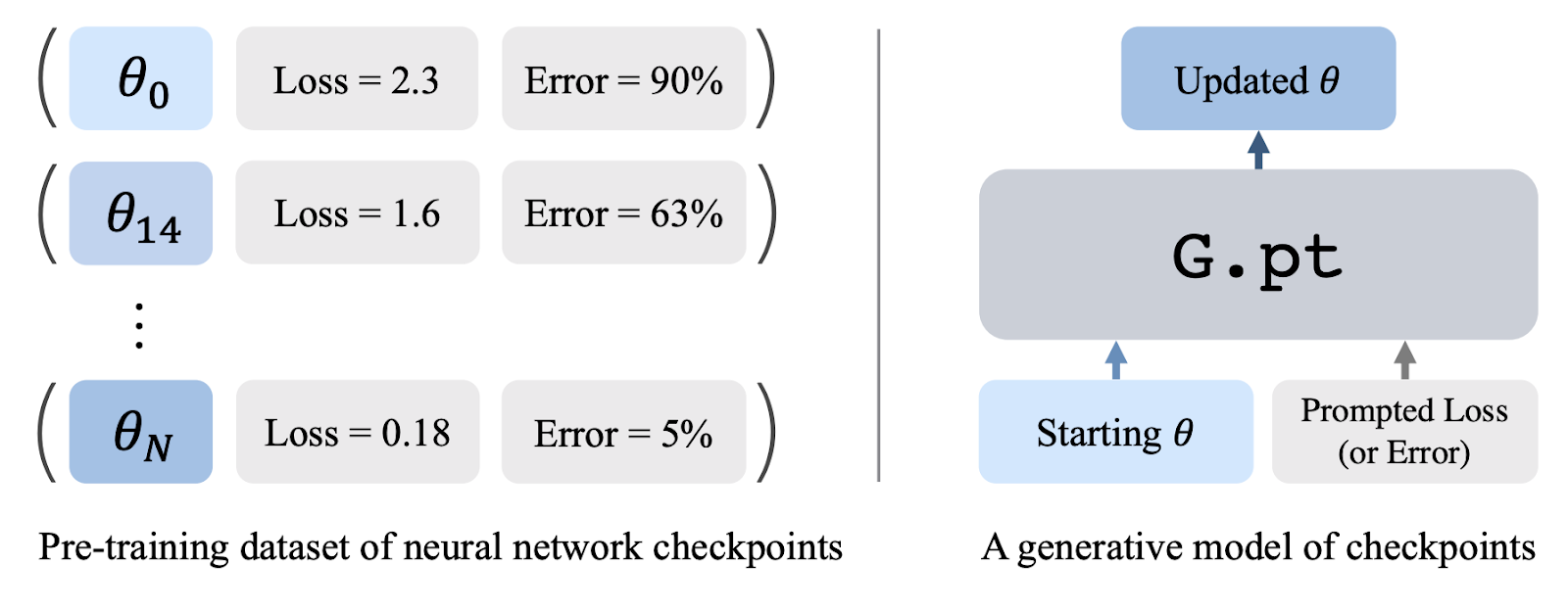 Pré-entraînement génératif à partir de points de contrôle. A gauche : construction d'un ensemble de données des points de contrôle de réseau neuronal. Chaque point de contrôle inclut les paramètres du réseau neuronal et métadonnées pertinentes (pertes et erreurs de test pour les tâches d’apprentissage supervisé, retours pour les tâches RL). A droite: G.pt, un modèle génératif de points de contrôle. G.pt prend un vecteur paramètre et une perte/erreur/retour invite en tant qu’entrée et prédit la distribution sur les paramètres mis à jour qui permettent d’obtenir l’invite.[/caption]
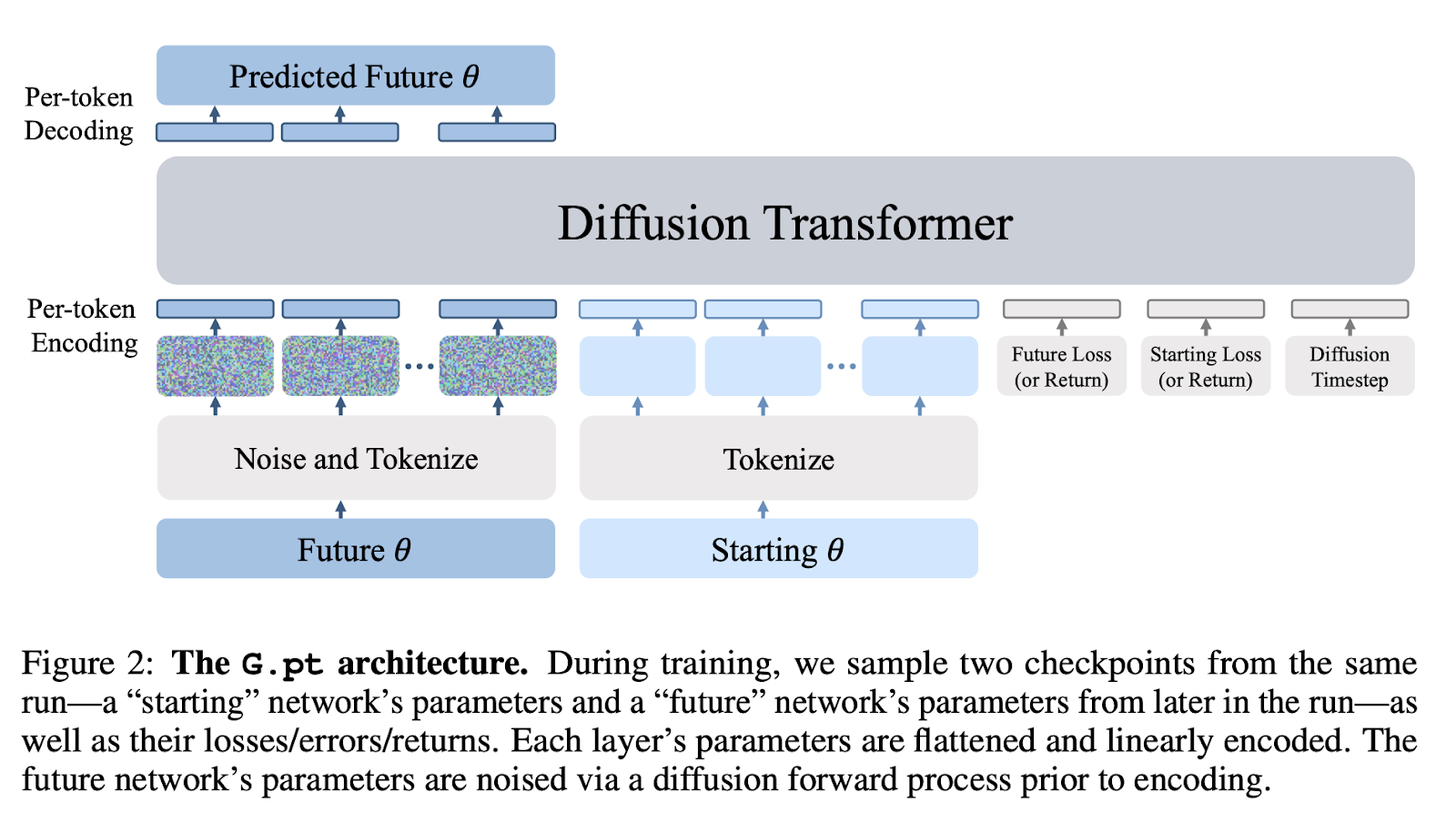
L’épine dorsale de leur modèle de diffusion est un transformateur qui opère sur des séquences de paramètres de réseaux de neurones.
Le modèle G.pt a été formé pour un ensemble de données, une métrique et une architecture donnés (par exemple, un modèle CNN CIFAR-10 conditionnel à la perte, un modèle MLP MNIST conditionnel à l’erreur...). L'épine dorsale de leur modèle de diffusion est un transformateur qui opère sur des séquences de paramètres de réseaux de neurones et utilise peu de biais inductifs spécifiques au domaine au-delà de la tokenisation.
Pré-entraînement génératif à partir de points de contrôle. A gauche : construction d'un ensemble de données des points de contrôle de réseau neuronal. Chaque point de contrôle inclut les paramètres du réseau neuronal et métadonnées pertinentes (pertes et erreurs de test pour les tâches d’apprentissage supervisé, retours pour les tâches RL). A droite: G.pt, un modèle génératif de points de contrôle. G.pt prend un vecteur paramètre et une perte/erreur/retour invite en tant qu’entrée et prédit la distribution sur les paramètres mis à jour qui permettent d’obtenir l’invite.[/caption]
L’épine dorsale de leur modèle de diffusion est un transformateur qui opère sur des séquences de paramètres de réseaux de neurones.
Le modèle G.pt a été formé pour un ensemble de données, une métrique et une architecture donnés (par exemple, un modèle CNN CIFAR-10 conditionnel à la perte, un modèle MLP MNIST conditionnel à l’erreur...). L'épine dorsale de leur modèle de diffusion est un transformateur qui opère sur des séquences de paramètres de réseaux de neurones et utilise peu de biais inductifs spécifiques au domaine au-delà de la tokenisation.
 Les chercheurs ont ainsi démontré que leur approche a un certain nombre de propriétés favorables. Tout d’abord, il peut entraîner rapidement des réseaux neuronaux à partir d’initialisations invisibles avec une seule mise à jour de paramètres. Deuxièmement, il peut générer des paramètres qui permettent d’obtenir un large éventail de pertes, d’erreurs et de retours provoqués. Troisièmement, il est capable de généraliser aux algorithmes d’initialisation du poids hors distribution. Quatrièmement, en tant que modèle génératif, il est capable d’échantillonner diverses solutions.
Un autre avantage de cette méthode par rapport aux optimiseurs traditionnels est qu’elle peut optimiser directement les métriques non différenciables, comme les erreurs de classification ou les retours RL. En effet, G.pt est formé comme un modèle de diffusion dans l’espace des paramètres, et les chercheurs n'ont pas été obligés de rétropropager à travers ces métriques afin de former leur modèle.
Sources de l'article :
LEARNING TO LEARN WITH GENERATIVE MODELS OF NEURAL NETWORK CHECKPOINTS
arXiv:2209.12892v1, 26 septembre 2022
Auteurs : William Peebles, Ilija Radosavovic, Tim Brooks, Alexei A. Efros, Jitendra Malik.
University of California, Berkeley
Les chercheurs ont ainsi démontré que leur approche a un certain nombre de propriétés favorables. Tout d’abord, il peut entraîner rapidement des réseaux neuronaux à partir d’initialisations invisibles avec une seule mise à jour de paramètres. Deuxièmement, il peut générer des paramètres qui permettent d’obtenir un large éventail de pertes, d’erreurs et de retours provoqués. Troisièmement, il est capable de généraliser aux algorithmes d’initialisation du poids hors distribution. Quatrièmement, en tant que modèle génératif, il est capable d’échantillonner diverses solutions.
Un autre avantage de cette méthode par rapport aux optimiseurs traditionnels est qu’elle peut optimiser directement les métriques non différenciables, comme les erreurs de classification ou les retours RL. En effet, G.pt est formé comme un modèle de diffusion dans l’espace des paramètres, et les chercheurs n'ont pas été obligés de rétropropager à travers ces métriques afin de former leur modèle.
Sources de l'article :
LEARNING TO LEARN WITH GENERATIVE MODELS OF NEURAL NETWORK CHECKPOINTS
arXiv:2209.12892v1, 26 septembre 2022
Auteurs : William Peebles, Ilija Radosavovic, Tim Brooks, Alexei A. Efros, Jitendra Malik.
University of California, Berkeley
Préformer un modèle génératif sur les points de contrôle
Au lieu de tirer parti d’ensembles de données à grande échelle d’images ou de texte, les chercheurs de l'université de Californie proposent d’apprendre à partir d'ensembles de données de points de contrôle enregistrés au cours de nombreuses courses d’entraînement. Les points de contrôle des réseaux neuronaux contiennent une mine d’informations : diverses configurations de paramètres et des métriques riches telles que les pertes de test, les erreurs de classification et les retours d’apprentissage par renforcement qui entraîne la qualité du point de contrôle. Les chercheurs ont préformé un modèle génératif sur des millions de points de contrôle et l'ont utilisé lors du test pour générer des paramètres pour un réseau neuronal qui résout une tâche en aval. Ils ont appelé leur modèle G.pt (G et .pt font respectivement référence aux modèles génératifs et aux extensions de points de contrôle). G.pt est formé comme un modèle de diffusion basé sur la transformation des paramètres du réseau neuronal. Il prend en entrée un vecteur de paramètre de départ (potentiellement initialisé de manière aléatoire), la perte/l’erreur/le retour de départ et le souhait de l’utilisateur : perte/erreur/retour. Une fois formé, il échantillonne une mise à jour de paramètres à partir du modèle qui correspond à la métrique demandée par l’utilisateur. Leur ensemble de données de pré-formation contient 23 millions de points de contrôle de réseau neuronal sur plus de 100 000 exécutions de formation. Il contient des données des réseaux neuronaux MLP et CNN formés pour les tâches de vision (MNIST, CIFAR-10) et les tâches de contrôle continu (Cartpole). [caption id="attachment_40224" align="alignnone" width="1600"] Pré-entraînement génératif à partir de points de contrôle. A gauche : construction d'un ensemble de données des points de contrôle de réseau neuronal. Chaque point de contrôle inclut les paramètres du réseau neuronal et métadonnées pertinentes (pertes et erreurs de test pour les tâches d’apprentissage supervisé, retours pour les tâches RL). A droite: G.pt, un modèle génératif de points de contrôle. G.pt prend un vecteur paramètre et une perte/erreur/retour invite en tant qu’entrée et prédit la distribution sur les paramètres mis à jour qui permettent d’obtenir l’invite.[/caption]
L’épine dorsale de leur modèle de diffusion est un transformateur qui opère sur des séquences de paramètres de réseaux de neurones.
Le modèle G.pt a été formé pour un ensemble de données, une métrique et une architecture donnés (par exemple, un modèle CNN CIFAR-10 conditionnel à la perte, un modèle MLP MNIST conditionnel à l’erreur...). L'épine dorsale de leur modèle de diffusion est un transformateur qui opère sur des séquences de paramètres de réseaux de neurones et utilise peu de biais inductifs spécifiques au domaine au-delà de la tokenisation.
Les chercheurs ont ainsi démontré que leur approche a un certain nombre de propriétés favorables. Tout d’abord, il peut entraîner rapidement des réseaux neuronaux à partir d’initialisations invisibles avec une seule mise à jour de paramètres. Deuxièmement, il peut générer des paramètres qui permettent d’obtenir un large éventail de pertes, d’erreurs et de retours provoqués. Troisièmement, il est capable de généraliser aux algorithmes d’initialisation du poids hors distribution. Quatrièmement, en tant que modèle génératif, il est capable d’échantillonner diverses solutions.
Un autre avantage de cette méthode par rapport aux optimiseurs traditionnels est qu’elle peut optimiser directement les métriques non différenciables, comme les erreurs de classification ou les retours RL. En effet, G.pt est formé comme un modèle de diffusion dans l’espace des paramètres, et les chercheurs n'ont pas été obligés de rétropropager à travers ces métriques afin de former leur modèle.
Sources de l'article :
LEARNING TO LEARN WITH GENERATIVE MODELS OF NEURAL NETWORK CHECKPOINTS
arXiv:2209.12892v1, 26 septembre 2022
Auteurs : William Peebles, Ilija Radosavovic, Tim Brooks, Alexei A. Efros, Jitendra Malik.
University of California, Berkeley