
À l’occasion du Spark+AI Summit 2018, Databricks a présenté MLflow, un nouveau projet open source visant à construire une plateforme open ML. Matei Zaharia, professeur assistant en sciences informatiques à l’Université de Stanford et Chief Technologist chez Databricks, a expliqué comment profiter pleinement des fonctionnalités offertes par ce nouveau programme.
MLflow est un outil permettant d’industrialiser de bout en bout les process de mise au point de projets Machine Learning. Il se donne pour ambition de simplifier le développement de projets de Machine Learning en entreprise en facilitant le suivi, la reproduction, la gestion et le déploiement des modèles.
Les défis du workflow en machine learning
Databricks, qui a développé MLflow, collabore avec de nombreuses entreprises qui partagent les mêmes préoccupations :
- Il existe une myriade d’outils disjoints. Des centaines d’outils logiciels couvrent chaque phase du cycle de ML, de la préparation des données à l’entraînement du modèle. De plus, contrairement au développement logiciel traditionnel, où les équipes sélectionnent un outil pour chaque phase, en machine learning, il faut généralement essayer un grand nombre d’outils avant d’obtenir des résultats optimaux. Les développeurs ML doivent donc utiliser et produire des dizaines de bibliothèques.
- Il est difficile de suivre les expériences. Les algorithmes de machine learning ont des dizaines de paramètres configurables, et que vous travailliez seul ou en équipe, il est difficile de savoir quels paramètres, code et données sont entrés dans chaque expérience pour produire un modèle.
- Il est difficile de reproduire les résultats. Sans suivi détaillé, les équipes ont souvent du mal à obtenir le même code et le même ensemble de paramètres pour travailler par la suite. Pourtant reproduire les étapes du workflow ML est indispensable sous peine de ne pas pouvoir reproduire les mêmes résultats.
- Il est difficile de déployer un modèle de Machine Learning. Déplacer un modèle en production peut être difficile en raison de la pléthore d’outils de déploiement et d’environnements dans lequel il doit s’exécuter. Il n’existe aucun moyen standard de déplacer des modèles d’une bibliothèque vers n’importe lequel de ces outils, ce qui crée un nouveau risque à chaque nouveau déploiement.
MLflow: une plate-forme de machine learning ouverte
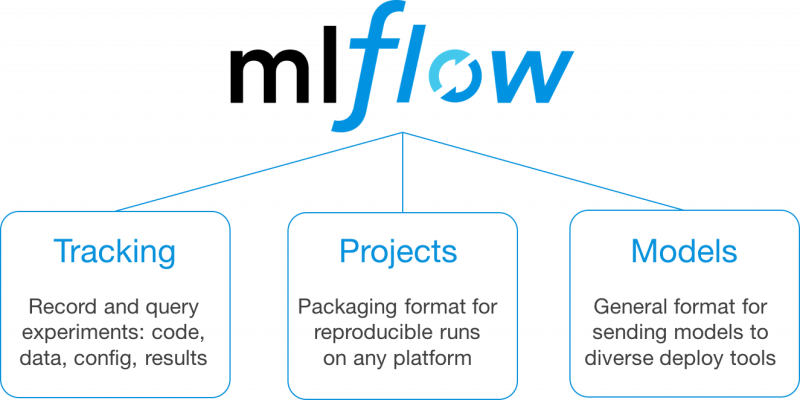
MLflow est conçu pour relever ces défis de flux de travail via un ensemble d’API et d’outils utilisable avec toute bibliothèque ML et base de code existante. Dans la version alpha actuelle, MLflow propose trois composants principaux :
- MLflow Tracking : API et interface utilisateur pour l’enregistrement de données sur les expériences, y compris les paramètres, les versions de code, les mesures d’évaluation et les fichiers de sortie utilisés.
- MLflow Projects : un format de packaging du code pour des exécutions reproductibles. En regroupant votre code dans un projet MLflow, vous pouvez spécifier ses dépendances et permettre à tout autre utilisateur de l’exécuter ultérieurement et de reproduire de manière fiable les résultats.
- MLflow Models : un format de modèle simple permettant de déployer des modèles sur de nombreux outils. Par exemple, si vous pouvez encapsuler votre modèle en tant que fonction Python, MLflow Models peut le déployer sur Docker ou Azure ML pour la distribution, Apache Spark pour le traitement par lots, etc.
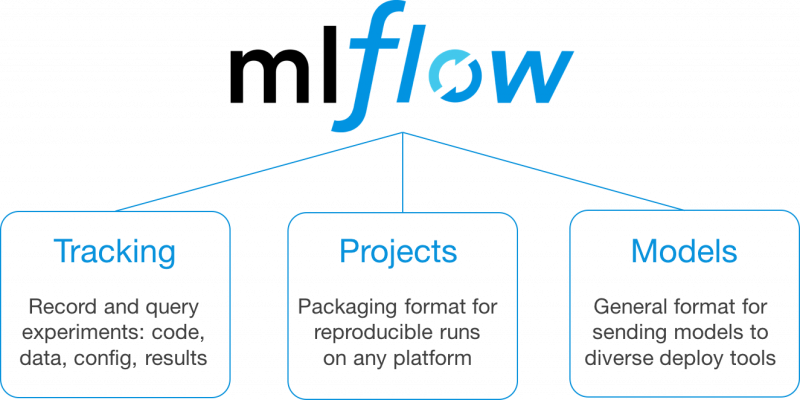
MLflow est conçu pour être modulaire, vous pouvez donc utiliser chacun de ces composants dans votre processus ML existant ou les combiner.
Démarrer avec MLflow
MLflow est open source et facile à installer à l’aide de pip install mlflow. Pour commencer à utiliser MLflow, suivez les instructions de la documentation MLflow ou consultez le code sur GitHub.
MLflow Tracking
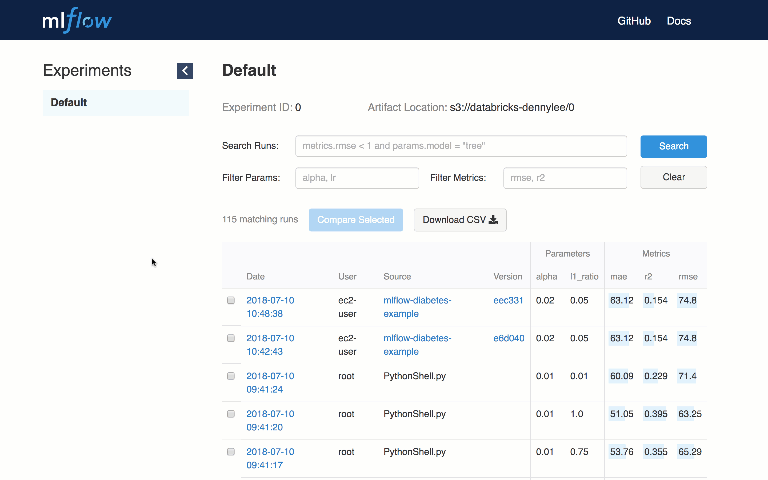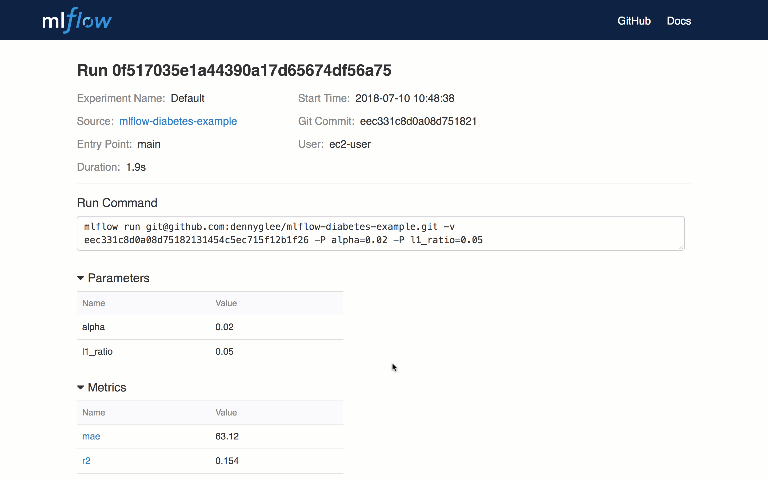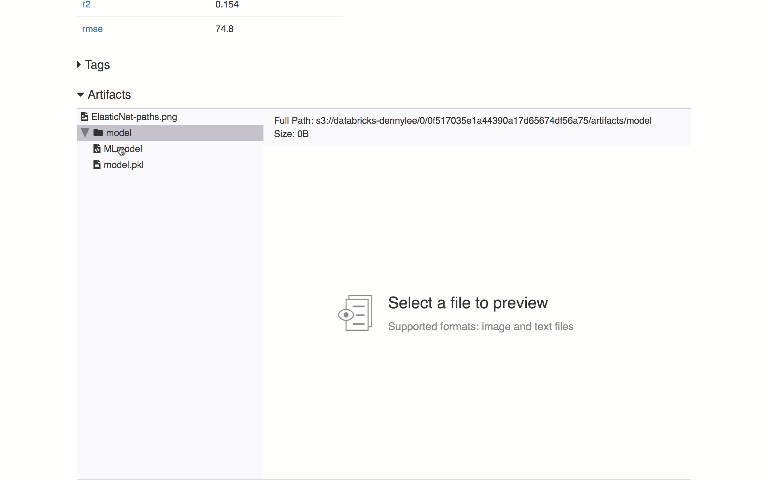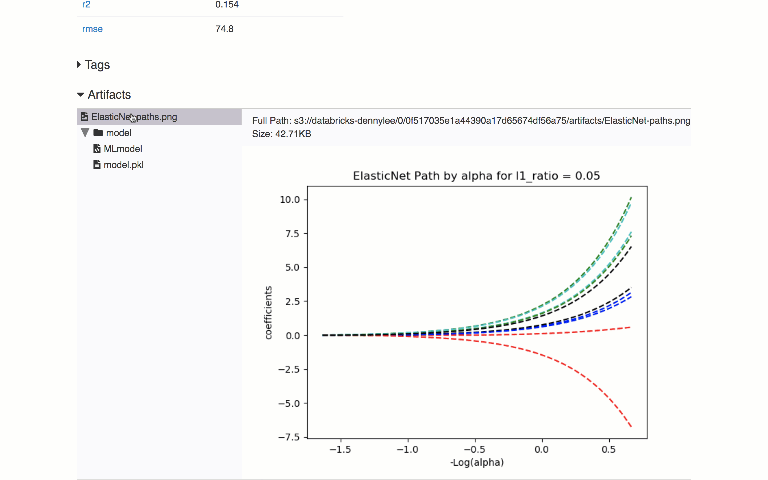
MLflow Tracking est une API et une UI permettant de consigner les paramètres, les versions de code, les métriques et les fichiers de sortie lors de l’exécution de votre code ML pour les visualiser ultérieurement.
Avec quelques lignes de code simples, vous pouvez suivre les paramètres, les métriques et les “artifacts” (fichiers de sortie arbitraires que vous souhaitez stocker). Vous pouvez utiliser MLflow Tracking dans n’importe quel environnement où vous pouvez exécuter du code (par exemple, un script autonome ou un bloc-notes) pour enregistrer des résultats dans des fichiers locaux ou sur un serveur, puis comparer plusieurs exécutions. À l’aide de l’interface utilisateur Web, vous pouvez afficher et comparer le résultat de plusieurs exécutions.
MLflow Projects
Le tracking des résultats est utile, mais vous devez aussi souvent les reproduire. MLflow Projects fournit un format standard pour réaliser un packaging réutilisable du data science code. Chaque projet est un répertoire avec un code ou un Git repository, et utilise un fichier descripteur pour spécifier ses dépendances et comment exécuter le code. Un MLflow Project est défini par un fichier YAML simple appelé MLproject.
Les projets peuvent spécifier leurs dépendances via un environnement Conda. Un projet peut également avoir plusieurs points d’entrée pour appeler des exécutions, avec des paramètres nommés. Vous pouvez exécuter des projets à l’aide de l’outil de ligne de commande mlflow run, à partir de fichiers locaux ou d’un Git repository.
MLflow configurera automatiquement l’environnement approprié pour le projet et l’exécutera. De plus, si vous utilisez l’API de suivi MLflow dans un projet, MLflow se souviendra de la version du projet exécutée (c’est-à-dire le Git commit) et de tous les paramètres. Vous pouvez alors facilement relancer exactement le même code. Le format de projet facilite ainsi le partage de data science code reproductible, que ce soit au sein d’une entreprise ou dans la communauté open source.
MLflow Models
Le troisième composant de MLflow est MLflow Models, un moyen simple mais puissant de réaliser le packaging des modèles. Bien que de nombreux formats de stockage de modèles (tels que ONNX et PMML) existent déjà, l’objectif de MLflow Models est différent : il s’agit de représenter la manière dont le modèle doit être appelé afin que de nombreux types d’outils de déploiement en aval puissent l’utiliser. Pour ce faire, MLflow Models peut stocker un modèle dans plusieurs formats appelés « flavors ». Ces versions peuvent être spécifiques à une bibliothèque (comme un TensorFlow graph) mais peuvent également être très génériques comme « Python function ».
Chaque modèle MLflow est simplement enregistré en tant que répertoire contenant des fichiers arbitraires et un fichier MLmodel YAML répertoriant les flavors dans lesquelles il peut être utilisé.
MLflow fournit des outils pour déployer de nombreux types de modèles communs sur diverses plates-formes. Par exemple, tout modèle prenant en charge le flavor python_function peut être déployé sur un server REST basé sur Docker, sur des plates-formes cloud telles qu’Azure ML et AWS SageMaker et comme une fonction définie dans Spark SQL pour l’inférence par lots et en continu. Si vous produisez des modèles MLflow en tant qu’artéfacts à l’aide de l’API MLflow Models, MLflow mémorisera également automatiquement du projet et de son exécution afin de pouvoir le reproduire ultérieurement.
Assembler ces outils
Bien que les composants individuels de MLflow soient simples, vous pouvez les combiner de manière très intéressante, que vous travailliez sur ML seul ou dans une grande équipe. Par exemple, vous pouvez utiliser MLflow pour:
- Enregistrer et visualiser le code, les données, les paramètres et les métriques lorsque vous développez un modèle sur votre ordinateur portable.
- Packager du code en tant que Projet MLflow pour l’exécuter à grande échelle dans un environnement cloud pour la recherche d’hyperparamètres.
- Créer un tableau de classement pour comparer les performances des différents modèles pour la même tâche au sein de votre équipe.
- Partager des algorithmes, des étapes de personnalisation et des modèles en tant que Projets ou Modèles MLflow que d’autres utilisateurs dans l’organisation pourront intégrer à un flux de travail.
- Déployer le même modèle pour le classement par lot et en temps réel sans le réécrire pour deux outils.
Et ensuite ?
MLflow sera mis à jour et l’équipe de développement prévoit d’ores et déjà d’y introduire de nouveaux composants majeurs (tels que la surveillance), des intégrations de bibliothèque et des liaisons de langage. Il y a quelques semaines, par exemple, elle a publié MLflow 0.2 avec le support TensorFlow intégré et plusieurs autres nouvelles fonctionnalités.
Source : www.oreilly.com
Article original de Matei Zaharia, assistant professor of computer science à l’Université de Stanford et Chief Technologist chez Databricks.
MLflow sera également présenté lors de la Strata Data Conference de New York, du 12 au 13 septembre prochain, lors de l’intervention de Mani Parkhe “MLflow : An Open platform to simplify the machine learning lifecycle“.
Plus d’informations :