
Lors de sa conférence Google I/O 2024, Google a présenté VEO, un modèle text-to-video mais les vidéos qu'il génère manquent d'une composante essentielle : le son, ce à quoi DeepMind travaille. Il a dernièrement partagé les avancées de sa technologie vidéo-audio (V2A) qui combine des pixels vidéo avec des invites textuelles pour générer des bandes sonores synchronisées.
Si le modèle V2A peut être associé à des modèles de génération vidéo comme Veo pour créer des effets sonores, de la musique et des dialogues adaptés à chaque scène, il peut également ajouter des bandes sonores à des séquences variées, telles que des films muets, des documents d’archives et plus encore, élargissant ainsi les possibilités créatives.
 crédit Google DeepMind[/caption]
Pour améliorer la qualité et la pertinence des sons générés, V2A utilise des annotations et des transcriptions détaillées lors de son entraînement. Cette méthode permet au système d'apprendre à associer des événements audio spécifiques à diverses scènes visuelles, créant ainsi une synchronisation audio-vidéo convaincante.
crédit Google DeepMind[/caption]
Pour améliorer la qualité et la pertinence des sons générés, V2A utilise des annotations et des transcriptions détaillées lors de son entraînement. Cette méthode permet au système d'apprendre à associer des événements audio spécifiques à diverses scènes visuelles, créant ainsi une synchronisation audio-vidéo convaincante.
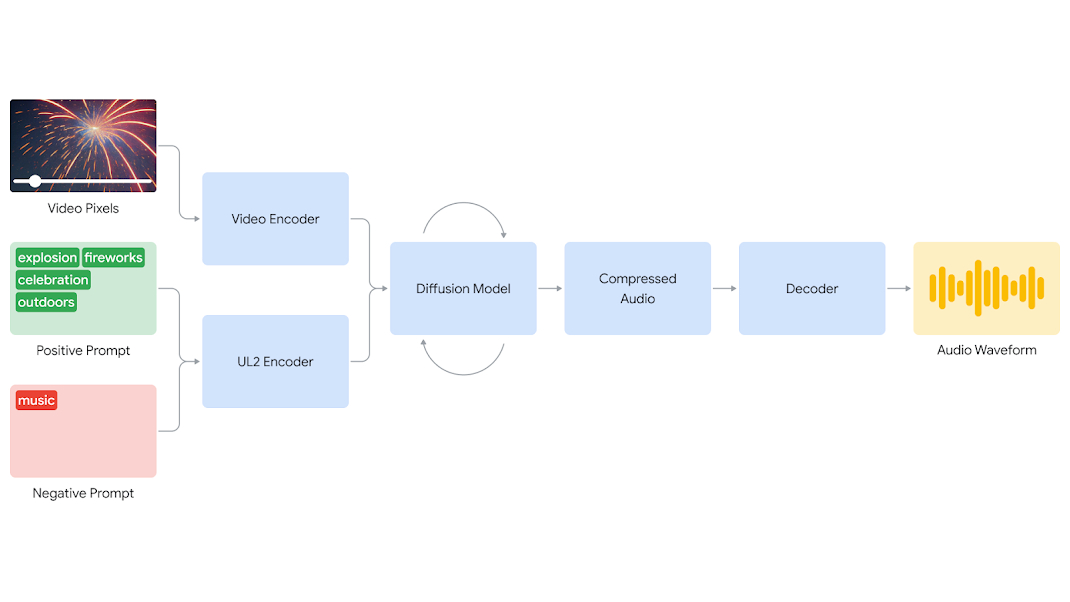
V2A permet aux utilisateurs d'avoir un contrôle précis sur la sortie audio. Grâce à des invites positives et négatives, les créateurs peuvent orienter la génération sonore vers des sons spécifiques ou éviter ceux qui ne conviennent pas. Cette flexibilité facilite l'expérimentation rapide de différentes options audio, permettant ainsi de choisir la meilleure correspondance pour chaque vidéo.
[embed]https://youtu.be/9Q0-t8D9XFI[/embed]Processus de Génération
Le système V2A commence par encoder l'entrée vidéo dans une représentation compressée. Ensuite, un modèle de diffusion affine de manière itérative l'audio à partir de bruit aléatoire, guidé par les pixels vidéo et les invites textuelles. Finalement, l'audio généré est décodé en une forme d'onde et synchronisé avec la vidéo. [caption id="attachment_58587" align="alignnone" width="1070"] crédit Google DeepMind[/caption]
Pour améliorer la qualité et la pertinence des sons générés, V2A utilise des annotations et des transcriptions détaillées lors de son entraînement. Cette méthode permet au système d'apprendre à associer des événements audio spécifiques à diverses scènes visuelles, créant ainsi une synchronisation audio-vidéo convaincante.