Le groupe Intelligence visuelle et systèmes (VIS) dirigé par le professeur Fisher Yu, qui fait partie du laboratoire de vision par ordinateur du département de technologie de l’information et de génie électrique de l’ETH Zürich, se concentre sur l’apprentissage des représentations pour la reconnaissance d’objets et la compréhension du mouvement dans les images et les vidéos, ainsi que sur la construction de systèmes robotiques et logiciels perceptuels basés sur les représentations visuelles. Associé à d'autres chercheurs, notamment de l’Université des sciences et technologies de Hong Kong, il a récemment publié le document de recherche "Mask-Free Video Instance Segmentation" accepté par la CVPR 2023.
La segmentation d’instance vidéo (VIS) nécessite la détection, le suivi et la segmentation conjoints de tous les objets d’une vidéo à partir d'un ensemble donné de catégories. Pour y parvenir, les modèles VIS de pointe sont formés avec des annotations vidéo à partir d’ensembles de données VIS.
Les masques vidéo étant fastidieux et coûteux à annoter, ce qui limite l’échelle et la diversité des ensembles de données VIS existants, l'équipe de recherche s'est donnée pour objectif de supprimer l’exigence d’annotation de masque.
Elle présente MaskFreeVIS, qui permet d’obtenir des performances VIS très compétitives, tout en utilisant uniquement des annotations de cadre englobant pour l’état de l’objet.
[embed]https://youtu.be/4pdp0rsj8F0[/embed]
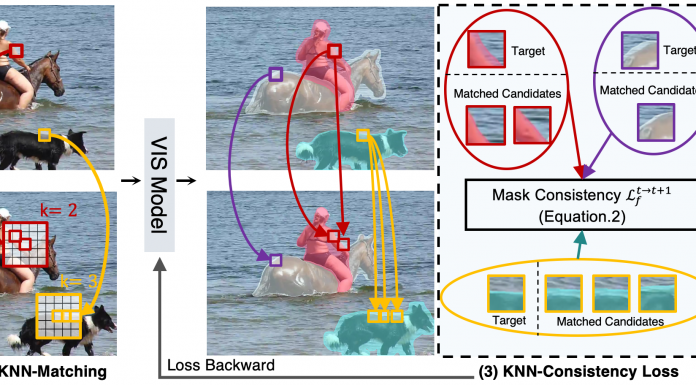
L'équipe a exploité les contraintes de cohérence temporelle du masque dans les vidéos en introduisant la perte de patch KNN temporelle (TK-Loss), offrant une supervision forte des masques sans aucune étiquette. Ce TK-Loss trouve des correspondances un-à-plusieurs entre les images, grâce à une étape efficace de correspondance des patchs suivie d’une sélection du plus proche voisin K. Une perte de cohérence est alors appliquée sur les correspondances trouvées.
 Le TK-Loss comporte quatre étapes :
1) Extraction des candidats au patch : recherche de candidats patch dans les images avec un rayon R.
2) Correspondance KNN temporelle : Faire correspondre k candidats à haut niveau de confiance par affinités de patch.
3) KNN-Consistency Loss : Appliquer l’objectif de cohérence du masque entre les matchs.
4) Connexion cyclique du tube : agrégation des pertes temporelles.
Le TK-Loss comporte quatre étapes :
1) Extraction des candidats au patch : recherche de candidats patch dans les images avec un rayon R.
2) Correspondance KNN temporelle : Faire correspondre k candidats à haut niveau de confiance par affinités de patch.
3) KNN-Consistency Loss : Appliquer l’objectif de cohérence du masque entre les matchs.
4) Connexion cyclique du tube : agrégation des pertes temporelles.
Le TK-Loss comporte quatre étapes :
1) Extraction des candidats au patch : recherche de candidats patch dans les images avec un rayon R.
2) Correspondance KNN temporelle : Faire correspondre k candidats à haut niveau de confiance par affinités de patch.
3) KNN-Consistency Loss : Appliquer l’objectif de cohérence du masque entre les matchs.
4) Connexion cyclique du tube : agrégation des pertes temporelles.