
Cerebras Systems, start-up californienne, a annoncé fin mars dernier la sortie open source de Cerebras-GPT, une famille de sept modèles GPT allant de 111 millions à 13 milliards de paramètres. Formés à l'aide de la formule d'entrainement de Chinchilla, Cerebras-GPT a, selon la société, des temps de formation plus rapides, des coûts de formation inférieurs et consomme moins d'énergie que n'importe quel modèle disponible au public à ce jour. C’est la première fois qu’une entreprise utilise des systèmes d’IA non basés sur GPU pour entraîner des LLM
Cerebras a beaucoup fait parler d'elle en 2019 avec le développement d'un processeur de taille record destiné à accélérer la capacité de calcul pour l'IA et le deep learning. Cette puce, Cerebras WSE (Wafer Scale Engine), était alors 56 fois plus grande que la plus grande puce du marché et comptait 1,2 billion de transistors, 400.000 cœurs et 18 gigaoctets de mémoire.
Deux ans plus tard, la start-up en présentait la seconde version, WSE-2, qui compte 850 000 cœurs pour les opérations de tenseur clairsemées, une mémoire sur puce massive à bande passante élevée et des ordres de grandeur d'interconnexion plus rapides qu'un cluster traditionnel ne pourrait le faire, selon elle.
Ils alimentent les systèmes CS-2, les nouvelles versions de superordinateur de Cerebras, qui font partie du supercalculateur Andromeda AI.
En lançant cette famille de modèles, Cerebras poursuit deux objectifs :
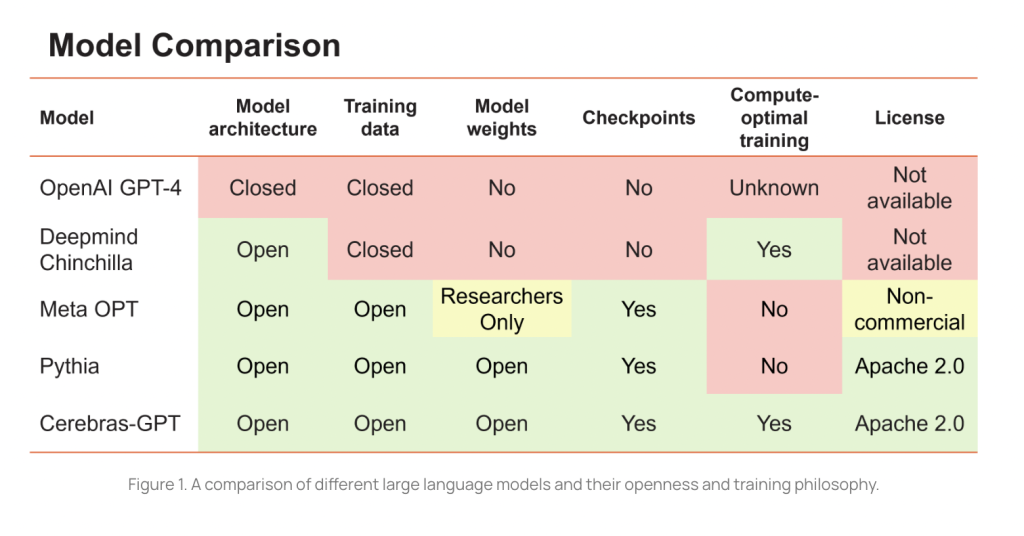 Comparaison de différents grands modèles linguistiques et de leur philosophie d'ouverture et d'entraînement.[/caption]
« Pour que les LLM soient une technologie ouverte et accessible, nous pensons qu'il est important d'avoir accès à des modèles de pointe ouverts, reproductibles et libres de droits pour la recherche et les applications commerciales ».
Les modèles Eleuther's Pythia sont open source mais ne sont pas formés de manière optimale pour le calcul car ils ont été entraînés avec un nombre fixe de jetons pour toutes les tailles.
L'étude Chinchilla de Deepmind a démontré que, pour une formation optimale des LLM pour le calcul, la taille du modèle et la taille du jeu de données d’apprentissage doivent être mises à l’échelle de manière égale.
Cerebras-GPT a été conçu pour couvrir une large gamme de tailles de modèles en utilisant le même ensemble de données que la suite Pythia, la Pile d’EleutherAI, notamment pour établir une loi de mise à l'échelle. Elle se compose de sept modèles :111M, 256M, 590M, 1.3B, 2.7B, 6.7B et 13B, qui sont tous entraînés à l'aide de 20 jetons par paramètre. En utilisant les jetons d'entraînement optimaux pour chaque taille de modèle, Cerebras-GPT atteint la perte la plus faible par unité de calcul pour toutes les tailles de modèle.
[caption id="attachment_42918" align="alignnone" width="784"]
Comparaison de différents grands modèles linguistiques et de leur philosophie d'ouverture et d'entraînement.[/caption]
« Pour que les LLM soient une technologie ouverte et accessible, nous pensons qu'il est important d'avoir accès à des modèles de pointe ouverts, reproductibles et libres de droits pour la recherche et les applications commerciales ».
Les modèles Eleuther's Pythia sont open source mais ne sont pas formés de manière optimale pour le calcul car ils ont été entraînés avec un nombre fixe de jetons pour toutes les tailles.
L'étude Chinchilla de Deepmind a démontré que, pour une formation optimale des LLM pour le calcul, la taille du modèle et la taille du jeu de données d’apprentissage doivent être mises à l’échelle de manière égale.
Cerebras-GPT a été conçu pour couvrir une large gamme de tailles de modèles en utilisant le même ensemble de données que la suite Pythia, la Pile d’EleutherAI, notamment pour établir une loi de mise à l'échelle. Elle se compose de sept modèles :111M, 256M, 590M, 1.3B, 2.7B, 6.7B et 13B, qui sont tous entraînés à l'aide de 20 jetons par paramètre. En utilisant les jetons d'entraînement optimaux pour chaque taille de modèle, Cerebras-GPT atteint la perte la plus faible par unité de calcul pour toutes les tailles de modèle.
[caption id="attachment_42918" align="alignnone" width="784"]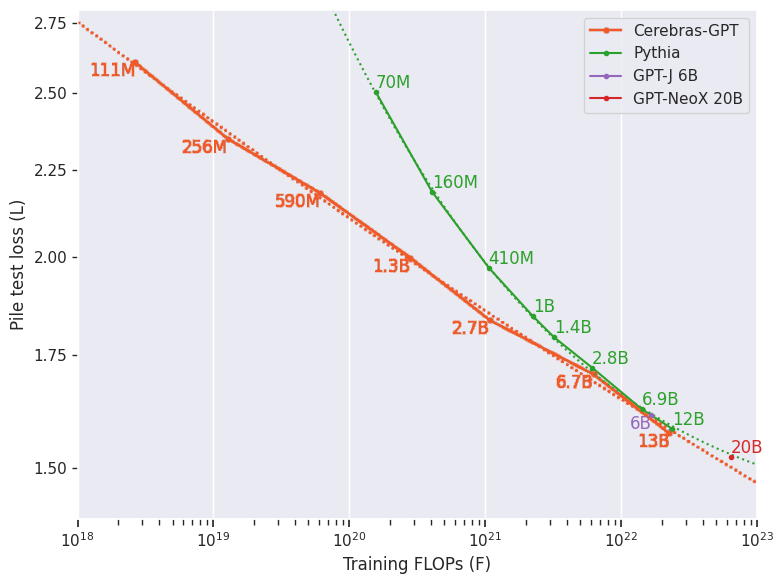 Comparaison Cerebras-GPT vs Pythie (Les courbes inférieures montrent une plus grande efficacité de calcul pour un niveau de perte donné).[/caption]
Comparaison Cerebras-GPT vs Pythie (Les courbes inférieures montrent une plus grande efficacité de calcul pour un niveau de perte donné).[/caption]
 Pour promouvoir la recherche ouverte et l’accès, Cerebras publie les sept modèles, la méthodologie d’entraînement et les poids d’entraînement à la communauté de recherche sous la licence permissive Apache 2.0. Cette version offre plusieurs avantages :
Pour promouvoir la recherche ouverte et l’accès, Cerebras publie les sept modèles, la méthodologie d’entraînement et les poids d’entraînement à la communauté de recherche sous la licence permissive Apache 2.0. Cette version offre plusieurs avantages :
- faciliter la recherche sur les lois de mise à l’échelle LLM en utilisant des architectures et des ensembles de données ouverts ;
- démontrer la simplicité et l’évolutivité de la formation LLM sur la pile logicielle et matérielle Cerebras.
Cerebras-GPT : une famille de modèles pour le développement d'un LLM ouvert
L'entraînement des LLM nécessite des ressources considérables en termes de temps, d'expertise et de coûts de calcul. Les rares organisations qui ont les moyens d'investir dans l’entraînement de ces modèles peuvent donc choisir de ne pas les partager en open source pour protéger leur investissement, une tendance qui semble se confirmer... Cerebras déclare dans son blog : [caption id="attachment_42915" align="alignnone" width="1024"] Comparaison de différents grands modèles linguistiques et de leur philosophie d'ouverture et d'entraînement.[/caption]
« Pour que les LLM soient une technologie ouverte et accessible, nous pensons qu'il est important d'avoir accès à des modèles de pointe ouverts, reproductibles et libres de droits pour la recherche et les applications commerciales ».
Les modèles Eleuther's Pythia sont open source mais ne sont pas formés de manière optimale pour le calcul car ils ont été entraînés avec un nombre fixe de jetons pour toutes les tailles.
L'étude Chinchilla de Deepmind a démontré que, pour une formation optimale des LLM pour le calcul, la taille du modèle et la taille du jeu de données d’apprentissage doivent être mises à l’échelle de manière égale.
Cerebras-GPT a été conçu pour couvrir une large gamme de tailles de modèles en utilisant le même ensemble de données que la suite Pythia, la Pile d’EleutherAI, notamment pour établir une loi de mise à l'échelle. Elle se compose de sept modèles :111M, 256M, 590M, 1.3B, 2.7B, 6.7B et 13B, qui sont tous entraînés à l'aide de 20 jetons par paramètre. En utilisant les jetons d'entraînement optimaux pour chaque taille de modèle, Cerebras-GPT atteint la perte la plus faible par unité de calcul pour toutes les tailles de modèle.
[caption id="attachment_42918" align="alignnone" width="784"] Comparaison Cerebras-GPT vs Pythie (Les courbes inférieures montrent une plus grande efficacité de calcul pour un niveau de perte donné).[/caption]
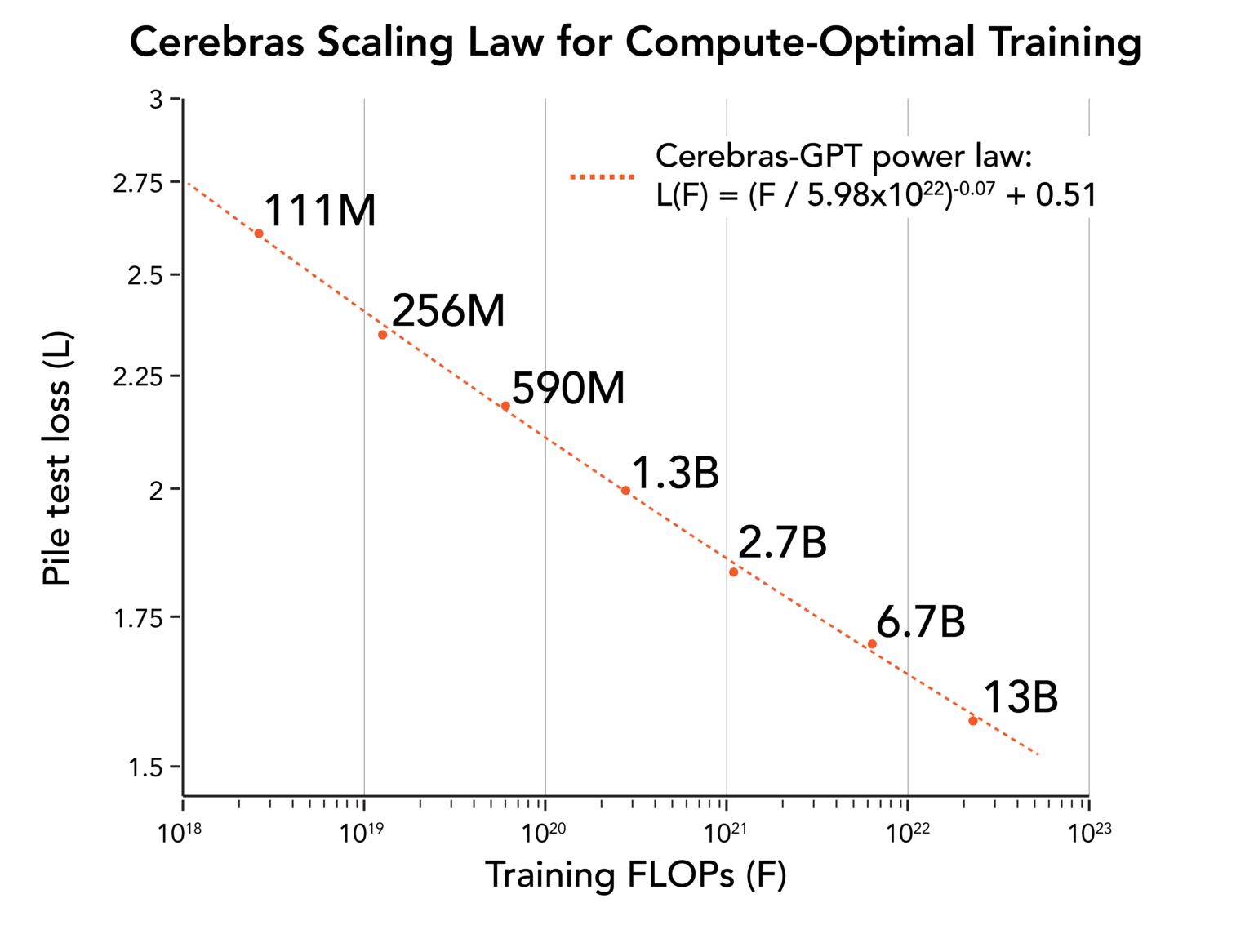
La loi d'échelle de Cerebras
Tous les modèles ont été entraînés sur les systèmes CS2 d'Andromeda à l'aide d'une architecture de flux de poids simple et parallèle aux données. N'ayant pas à se soucier du partitionnement des modèles, Cerebras a pu former ces modèles en quelques semaines seulement et dériver une nouvelle loi d'échelle. Les lois de mise à l’échelle sont aussi fondamentales pour l’IA que la loi de Moore l’est pour les semi-conducteurs : elles permettent aux chercheurs de prédire comment un budget de formation de calcul donné se traduit en performances de modèle. La loi de mise à l’échelle de Cerebras qui étend les travaux antérieurs effectués par OpenAI et DeepMind, est la première loi de mise à l’échelle dérivée à l’aide d’un ensemble de données ouvert, ce qui la rend reproductible par la communauté de l’IA.
Pour promouvoir la recherche ouverte et l’accès, Cerebras publie les sept modèles, la méthodologie d’entraînement et les poids d’entraînement à la communauté de recherche sous la licence permissive Apache 2.0. Cette version offre plusieurs avantages :
- Les poids d’entraînement fournissent un modèle pré-entraîné très précis pour un réglage fin. En appliquant une quantité modeste de données personnalisées, n’importe qui peut créer des applications puissantes et spécifiques à l’industrie avec un minimum de travail.
- Les différentes tailles des modèles et les points de contrôle qui les accompagnent permettent aux chercheurs en IA de créer et de tester de nouvelles optimisations et flux de travail qui profitent largement à la communauté.
- En publiant sous la licence standard de l’industrie Apache 2.0, ces modèles peuvent être utilisés pour la recherche ou les entreprises commerciales sans redevances.