
Vocaliser un texte écrit a été un objectif de recherche durant des décennies, notamment chez Google. Deux des chercheurs de Google Research (Google Brain et Machine Perception), Jonathan Shen et Ruoming Pang, ont annoncé la création de Tacotron 2, un système de synthèse vocale au son très naturel.
Il y a eu de grands progrès dans la recherche sur la synthèse vocale au cours des dernières années et de nombreux améliorations ont été apportées pour pouvoir créer un système performant. C'est en se basant sur des travaux de recherche antérieurs, dont Tacotron et WaveNet, que l'équipe de recherche a développé Tacotron 2. Dans son approche, elle n'a pas utilisé de caractéristiques linguistiques et acoustiques complexes en tant qu'input. Au lieu de cela, elle a travaillé pour que le système parvienne à générer un discours similaire à celui d'un humain à partir de texte en utilisant des réseaux de neurones entrainés uniquement avec des exemples de discours et les transcriptions écrites correspondantes.
Les chercheurs ont publié un autre article expliquant de façon plus détaillée leurs travaux “Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions” sur arXiv.org. Dans le communiqué, ils schématisent le fonctionnement de leur système et indiquent s'être basés sur un modèle séquence-à-séquence optimisé pour la synthèse vocale afin d'effectuer la correspondance entre les lettres d'une séquence et une séquence de caractéristiques qui encodent le son.
Ces caractéristiques sont représentées sous forme de spectrogramme avec un échantillonnage toutes les 12,5 millisecondes, afin de capter non seulement la prononciation des mots mais également les subtilités du langage humain telles que le volume sonore, la vitesse et l'intonation. Enfin, ces caractéristiques sont converties en une forme d'onde de 24 kHz utilisant une architecture de type WaveNet.
[caption id="attachment_3714" align="alignnone" width="640"]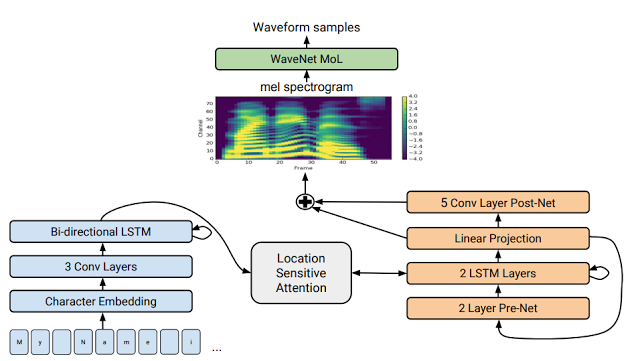 Google Research[/caption]
Les chercheurs ont mis à disposition du public, sur GitHub, des échantillons audio créés à partir de Tacotron 2, pour que l'on puisse découvrir les résultats qu'offre ce nouveau système assez pointu. Afin d'évaluer les performances de Tacotron 2, ils ont demandé à des auditeurs humains de noter le naturel de la voix générée. Le score obtenu s'est avéré comparable à celui d'enregistrements professionnels.
Même si les résultats sont encourageants, les chercheurs reconnaissent qu'ils restent toujours confrontés à des problèmes complexes. Le système doit en effet encore être amélioré pour pouvoir prononcer des mots difficiles comme decorum ou merlot. Parallèlement, il semble qu'il génère d'étranges bruits dans certains cas. Ils souhaitent également pouvoir le développer pour qu'il soit capable de générer un audio en temps réel et pouvoir le contrôler pour qu'il semble triste ou joyeux.
Pour plus d'informations sur la synthèse vocale, n'hésitez pas à consulter notre dossier sur le sujet: Si l’histoire de la synthèse vocale m’était contée.
Google Research[/caption]
Les chercheurs ont mis à disposition du public, sur GitHub, des échantillons audio créés à partir de Tacotron 2, pour que l'on puisse découvrir les résultats qu'offre ce nouveau système assez pointu. Afin d'évaluer les performances de Tacotron 2, ils ont demandé à des auditeurs humains de noter le naturel de la voix générée. Le score obtenu s'est avéré comparable à celui d'enregistrements professionnels.
Même si les résultats sont encourageants, les chercheurs reconnaissent qu'ils restent toujours confrontés à des problèmes complexes. Le système doit en effet encore être amélioré pour pouvoir prononcer des mots difficiles comme decorum ou merlot. Parallèlement, il semble qu'il génère d'étranges bruits dans certains cas. Ils souhaitent également pouvoir le développer pour qu'il soit capable de générer un audio en temps réel et pouvoir le contrôler pour qu'il semble triste ou joyeux.
Pour plus d'informations sur la synthèse vocale, n'hésitez pas à consulter notre dossier sur le sujet: Si l’histoire de la synthèse vocale m’était contée.
Google Research[/caption]
Les chercheurs ont mis à disposition du public, sur GitHub, des échantillons audio créés à partir de Tacotron 2, pour que l'on puisse découvrir les résultats qu'offre ce nouveau système assez pointu. Afin d'évaluer les performances de Tacotron 2, ils ont demandé à des auditeurs humains de noter le naturel de la voix générée. Le score obtenu s'est avéré comparable à celui d'enregistrements professionnels.
Même si les résultats sont encourageants, les chercheurs reconnaissent qu'ils restent toujours confrontés à des problèmes complexes. Le système doit en effet encore être amélioré pour pouvoir prononcer des mots difficiles comme decorum ou merlot. Parallèlement, il semble qu'il génère d'étranges bruits dans certains cas. Ils souhaitent également pouvoir le développer pour qu'il soit capable de générer un audio en temps réel et pouvoir le contrôler pour qu'il semble triste ou joyeux.
Pour plus d'informations sur la synthèse vocale, n'hésitez pas à consulter notre dossier sur le sujet: Si l’histoire de la synthèse vocale m’était contée.