
先週末、誰もがDeepSeekとそのモデルR1に注目している中、フランスのGenAIユニコーンであるMistral AIは、より控えめにMistral Small 3を発表しました。Apache 2.0ライセンスの下で公開されたこのモデルは、24億のパラメーターを持ち、低遅延に最適化されており、「GPT4o-miniのような不透明な専有モデルに対する優れたオープンソースの代替手段」とされています。
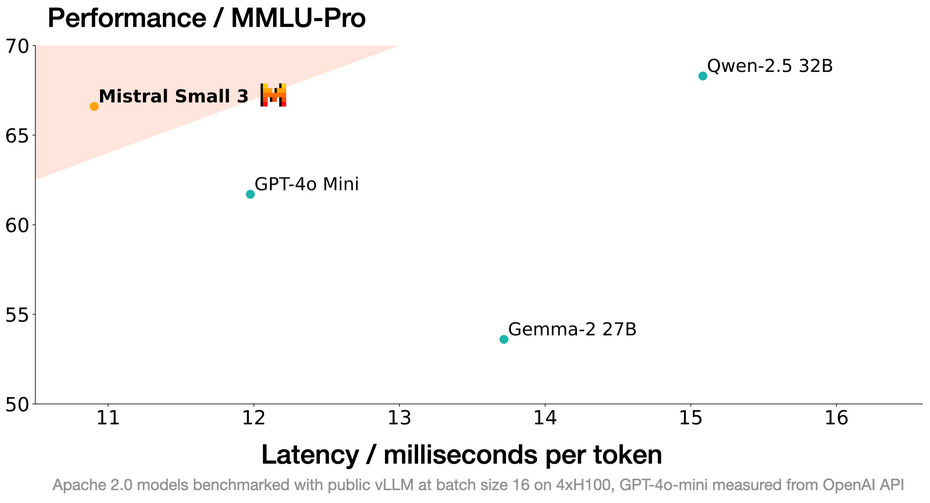
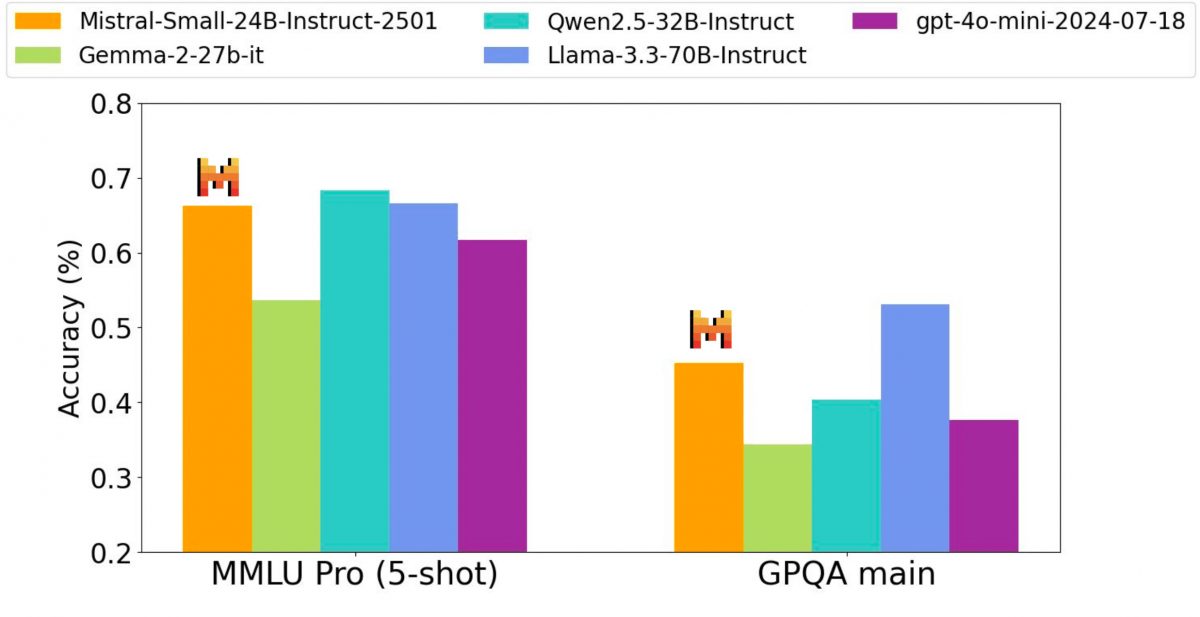
Small 3を用いて、このユニコーンは再び、優れた性能を発揮するためにLLMが天文学的な数のパラメーターを必要としないことを示しました。このモデルは、効率性の高まるニーズに応えるもので、1秒あたり150トークンの処理率を提供し、MMLUベンチマークで81%以上の精度を誇ります。
 この技術的な偉業は、従来の層の数を減らす最適化されたアーキテクチャによって実現されており、応答の質を損なうことなく、フォワードパス時間(ニューラルネットワークモデルが入力を処理し出力を生成するのに必要な時間)を短縮しています。
このアーキテクチャの選択により、「現在そのカテゴリで最も効率的なモデル」となっており、最適化バージョンのMistral Small 3 Instructは、Llama 3.3 70BやQwen 32Bのようなはるかに大きなモデルと競合し、標準ハードウェアでの迅速かつ効果的な実行を保証します。
この技術的な偉業は、従来の層の数を減らす最適化されたアーキテクチャによって実現されており、応答の質を損なうことなく、フォワードパス時間(ニューラルネットワークモデルが入力を処理し出力を生成するのに必要な時間)を短縮しています。
このアーキテクチャの選択により、「現在そのカテゴリで最も効率的なモデル」となっており、最適化バージョンのMistral Small 3 Instructは、Llama 3.3 70BやQwen 32Bのようなはるかに大きなモデルと競合し、標準ハードウェアでの迅速かつ効果的な実行を保証します。
この技術的な偉業は、従来の層の数を減らす最適化されたアーキテクチャによって実現されており、応答の質を損なうことなく、フォワードパス時間(ニューラルネットワークモデルが入力を処理し出力を生成するのに必要な時間)を短縮しています。
このアーキテクチャの選択により、「現在そのカテゴリで最も効率的なモデル」となっており、最適化バージョンのMistral Small 3 Instructは、Llama 3.3 70BやQwen 32Bのようなはるかに大きなモデルと競合し、標準ハードウェアでの迅速かつ効果的な実行を保証します。
多様なセクターへの応用
Mistral Small 3は、技術的な性能の高さを示すだけでなく、企業の具体的なニーズに適応するための柔軟性も持っています。想定されるユースケースの中で、いくつかの分野が際立っています:- 会話アシスタンスと機能呼び出し:低遅延がリアルタイムのインタラクションを保証し、チャットボットやバーチャルアシスタントにとって不可欠です;
- 特定の専門分野に対する微調整:小さなサイズが診断医療や法的アドバイスのような特定の分野に対する微調整を容易にします;
- ローカル推論:モデルをアクセス可能なハードウェアに展開することで、デリケートなデータがローカルで処理される必要があるセクターでの使用を促進します。