
サーフシャーク、サイバーセキュリティのスペシャリストは最近、市場の主要チャットボットによる個人データ収集に関する比較調査の更新を公開しました。この分析は明確です:Meta AIは最も侵入的な会話型アシスタントです。分析された35種類のデータのうち32種類を収集し、平均(13種類のデータ)を大きく上回り、これまで1位だったGoogle Geminiを超えました。
2010年代以来、大手プラットフォームは注意力を収益化(ターゲティング広告、推薦アルゴリズム)することで支配力を築いてきました。生成AIの出現に伴い、新たなパラダイムが描かれています:注意を引くのではなく、より個別化されコンテキストに合わせた空間で直接ユーザーと対話することです。
Metaは、Facebook/Instagramエコシステムにアシスタントを統合することで、データの利用において新たな段階を踏み出しました。複雑なインターフェースや不透明なプライバシーポリシーに埋もれがちなユーザーの同意は、ますます象徴的になっているようです。
Meta AI、データ収集において最も貪欲
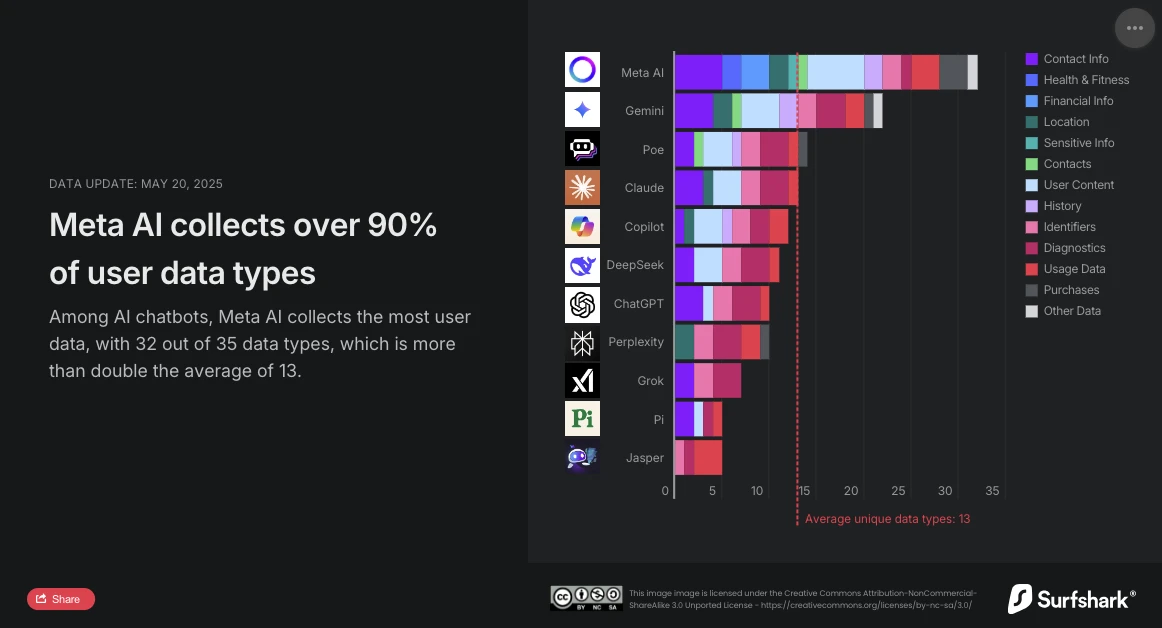
サーフシャークの調査は、AIチャットボットによるデータ収集の規模を明らかにしています。分析されたすべてのアプリケーションがユーザーデータを収集し、45%が位置情報を収集しており、Jasper、Poe、Copilotを含む約30%が広告トラッキングを行っており、これは他のサービスのデータとクロスしたり、データブローカーに販売したりすることを意味します。
データブローカーは、個人データの購入と販売を専門とする企業です。これらは、アプリケーション、ウェブサイト、公開データベースからの情報をまとめ、ユーザーの詳細なプロファイルを作成し、広告主、保険会社、雇用主、時には公共機関に販売します。
この分野の最大手企業には、Acxiom、Experian、Epsilon、Oracle Data Cloudがあり、これらの情報を活用して数十億ドルを動かしています。特定の地域では規制が進んでいるものの、世界的には市場はほとんど規制されていません。
調査によると、Meta AIは唯一、金融情報、健康、体力に関するデータを収集しており、さらに、特に敏感な情報、例えば人種や民族、性的指向、妊娠や出産、障害、宗教や哲学的信条、労働組合の所属、政治的意見、遺伝情報や生体情報も収集しています。
サーフシャークのフランス担当責任者、Maud Lepetitは警鐘を鳴らしています:
「MetaはFacebook、Instagram、またはそのオーディエンスネットワークを通じてデータを吸収するだけではありません。今日では、同じロジックをAIアシスタントに適用し、公開された投稿、写真、メッセージだけでなく、インターフェースに直接入力されたデータも取り入れています。これは、生成AIが個人データに基づく際の潜在的な逸脱の新たな例です。」
Meta AIは、Copilotとともに、ターゲティング広告のために第三者と共有するためにユーザーのアイデンティティに関連するデータを収集する唯一のアプリケーションでもあります。しかし、24種類のデータを利用しているMeta AIは、デバイスIDと広告データの2種類のみを使用するCopilotとは明らかに異なります。
ChatGPT、慎重な戦略
OpenAIは、より慎重なアプローチを採用しています。収集するデータはユーザーの連絡先、ユーザーコンテンツ、使用データ、診断データを含めて10種類のみであり、広告トラッキングや商業目的での第三者とのデータ共有は行っていません。さらに、30日後に削除される「一時チャット」オプションは、サービスの継続性とプライバシーの尊重を両立させる興味深い妥協案を提供しています。ユーザーは、自分のデータをモデルのトレーニングに使用しないようOpenAIに依頼することもできます。
DeepSeek、見かけの控えめさと具体的なリスクの間にある
中国のソリューションDeepSeekは、収集するチャット履歴を含む11種類のデータで中間に位置しています。しかし、データの保管場所(中華人民共和国)とThe Hacker Newsによって報告された重大なセキュリティ違反(100万件以上の会話記録の漏洩)が、サーバーの所在地やサイバーセキュリティの実践が収集されるデータの量と同じくらい重要であることを思い出させます。
今週からヨーロッパのユーザーデータを利用し始めるMeta
MetaがAIモデルのトレーニングのために5月27日からフランスとヨーロッパでデータ収集を開始するにあたり、Maud Lepetitは次のように述べています:
「人間とは異なり、生成AIは説明責任を持ちません。何でも学べますが、忘れることはできません。チャットボットに入力されたものは、そのシステム内に残り、おそらく永遠に。」
Metaによる個人データの利用に反対する場合、この期限前に行動する必要があります。このアプローチは「オプトアウト」の原則に基づいており、ユーザーが明確な同意(「オプトイン」)ではなく拒否の意思を表明する必要があるため、GDPRとの適合性について疑問を投げかけています。事前の同意なしにこの収集を正当化するための正当な利益が、Metaに対するNYOBや消費者団体の訴訟を引き起こしています。CNILは、AIシステムのトレーニングのための法的根拠として正当な利益を利用することが違法ではないが、関係する人々の利益と基本的権利の注意深い評価を必要とする、としています。