TLDR : Google researchers have developed MLE-STAR, an automatic learning agent that enhances the process of creating AI models by combining targeted web search, code refinement, and adaptive assembly. MLE-STAR demonstrated its effectiveness by winning 63% of competitions in the Kaggle-based MLE-Bench-Lite benchmark, significantly surpassing previous approaches.
Table of contents
Machine Learning Engineering (MLE) agents, based on large language models (LLMs), have opened new perspectives in the development of machine learning models by automating all or part of the process. However, existing solutions often face exploration limits or a lack of methodological diversity. Google's researchers address these challenges with MLE-STAR, an agent that combines targeted web search, granular refinement of code blocks, and adaptive assembly strategy.
Concretely, an MLE agent starts from a task description (e.g., "predict sales from tabular data") and provided datasets, then:
- Analyzes the problem and chooses an appropriate approach;
- Generates code (often in Python, with common or specialized ML libraries);
- Tests, evaluates, and refines the solution, sometimes over multiple iterations.
These agents rely on two key competencies of LLMs:
- Algorithmic reasoning (identifying relevant methods for a given problem);
- Executable code generation (complete scripts for data preparation, training, and evaluation).
Their goal is to reduce human workload by automating tedious steps like feature engineering, hyperparameter tuning, or model selection.
MLE-STAR: Targeted and Iterative Optimization
According to Google Research, existing MLEs face two major obstacles. Firstly, their heavy reliance on the internal knowledge of LLMs leads them to favor generic and well-established methods, such as the scikit-learn library for tabular data, at the expense of more specialized and potentially more efficient approaches.
Secondly, their exploration strategy often relies on a complete code rewrite at each iteration. This approach prevents them from focusing their efforts on specific components of the pipeline, such as systematically testing different feature engineering options before moving on to other steps.
Secondly, their exploration strategy often relies on a complete code rewrite at each iteration. This approach prevents them from focusing their efforts on specific components of the pipeline, such as systematically testing different feature engineering options before moving on to other steps.
To overcome these limitations, Google's researchers designed MLE-STAR, an agent that combines three levers:
- Web search to identify task-specific models and build a solid initial solution;
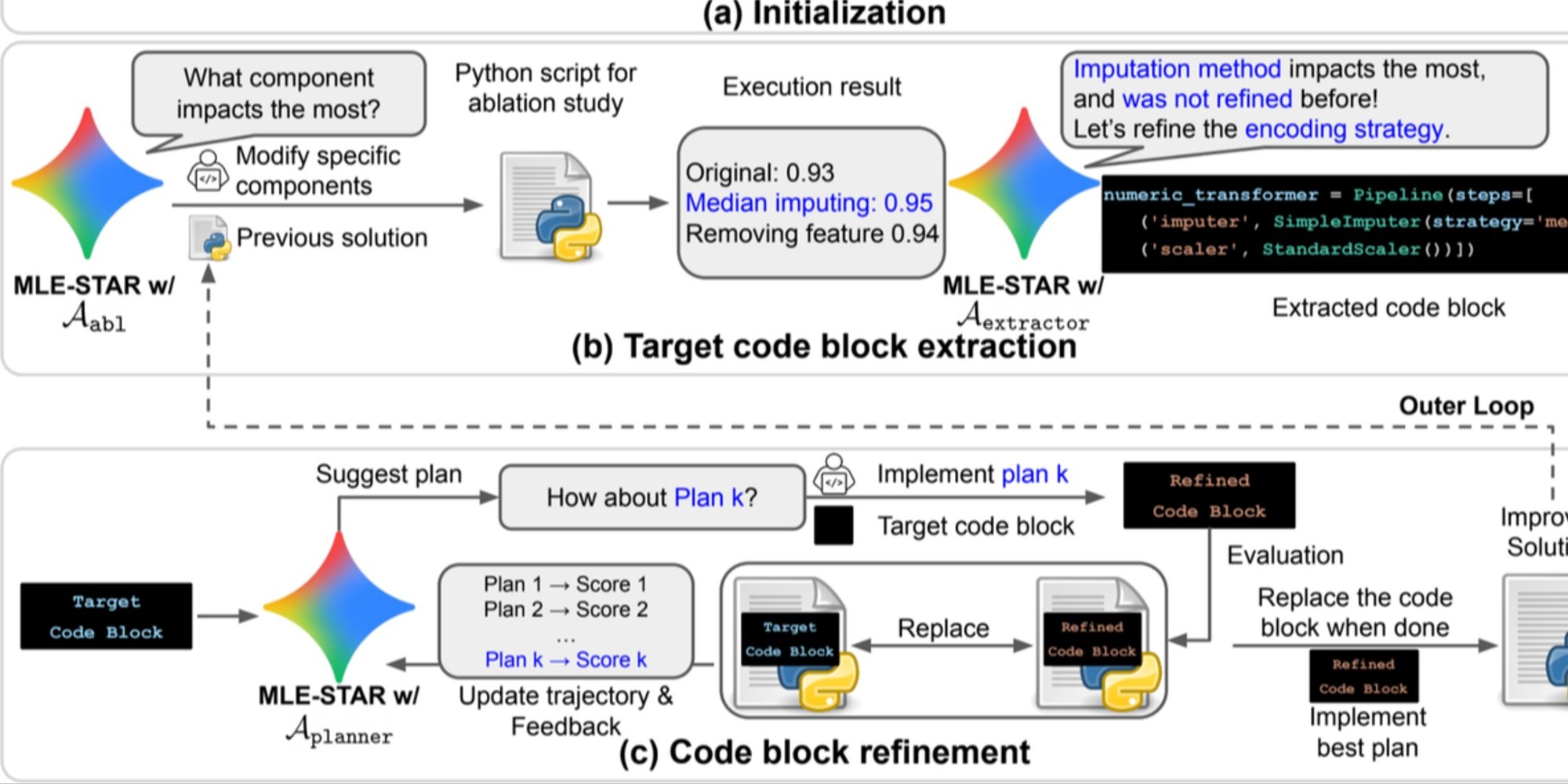
- Granular refinement by code blocks, relying on ablation studies to identify the parts with the most impact on performance, then optimizing them iteratively;
- Adaptive assembly strategy, capable of merging several candidate solutions into an improved version, refined over attempts.
This iterative process, search, critical block identification, optimization, then new iteration, allows MLE-STAR to focus its efforts where they produce the most measurable gains.
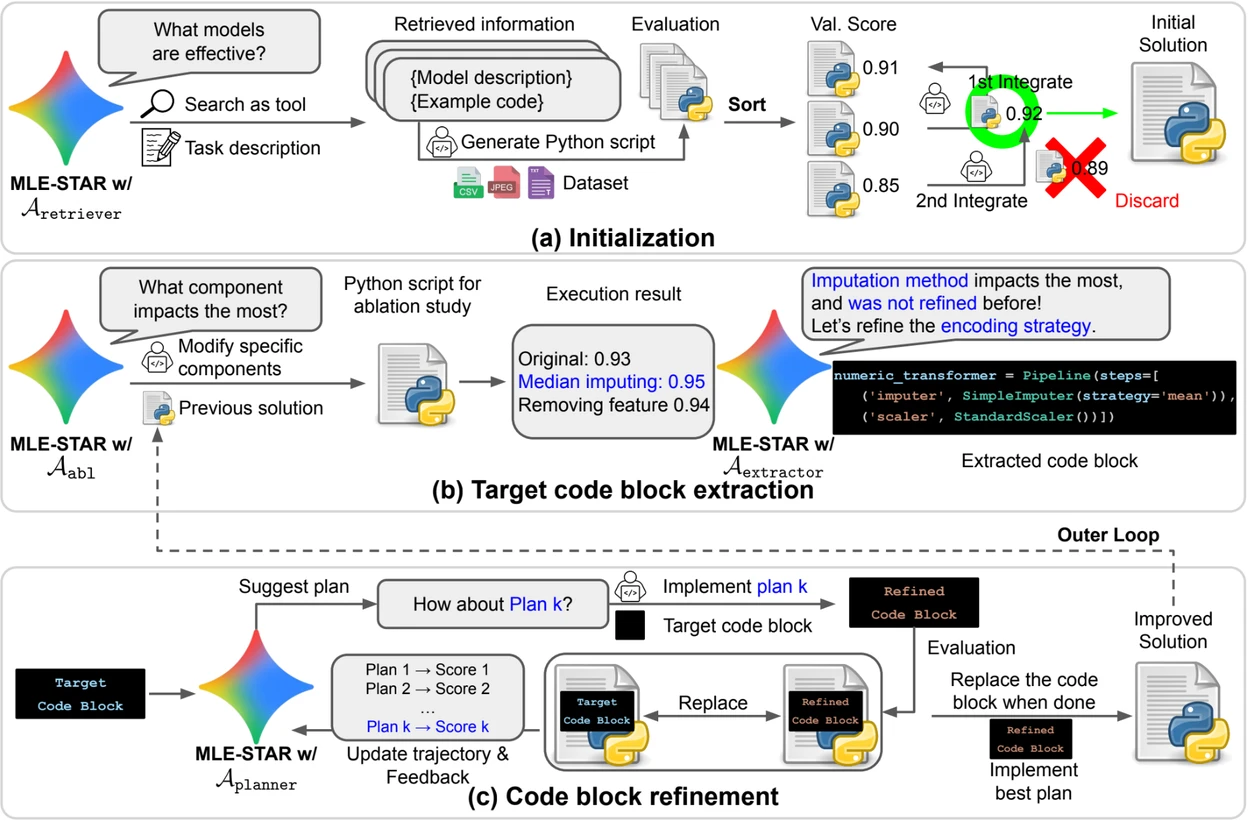
Credit: Google Research.
Overview. a) MLE-STAR starts by using web search to find and incorporate task-specific models into an initial solution. (b) For each refinement step, it conducts an ablation study to determine the code block with the most significant impact on performance. (c) The identified code block then undergoes iterative refinement based on plans suggested by LLM, exploring various strategies using feedback from previous experiments. This process of selecting and refining target code blocks repeats, with the improved solution from (c) becoming the starting point for the next refinement step (b).
Control Modules to Ensure Reliable Solutions
Beyond its iterative approach, MLE-STAR integrates three modules to enhance the robustness of generated solutions:
- A debugging agent to analyze runtime errors (e.g., a Python traceback) and suggest automatic corrections;
- A data leakage checker to detect situations where test data information is incorrectly used during training, a bias that skews measured performance;
- A data usage checker to ensure that all provided data sources are utilized, even when they are not in standard formats like CSV.
These modules address common problems observed in code generated by LLMs.
Significant Results on Kaggle
To evaluate MLE-STAR's effectiveness, the researchers tested it within the MLE-Bench-Lite benchmark, based on Kaggle competitions. The protocol measured an agent's ability to produce a complete and competitive solution from a simple task description.
The results show that MLE-STAR achieves a medal in 63% of competitions, including 36% gold, compared to 25.8% to 36.6% for the best previous approaches. This gain is attributed to the combination of several factors: the rapid adoption of recent models like EfficientNet or ViT, the ability to integrate models not identified by web search through occasional human intervention, and the automatic corrections made by the leakage and data usage checkers.
Find the scientific paper on arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
The open source code is available on GitHub