
TLDR : Mistral AI launches Voxtral, its first open-source audio model family, challenging major players with advanced features and competitive pricing.
Table of contents
Last Tuesday, Mistral AI announced the launch of Voxtral, its first family of open-source audio models. Designed for professional use, these speech comprehension models mark the French unicorn's entry into the strategic segment of voice intelligence, a domain previously dominated by players like OpenAI, Meta, and Google.
The Voxtral range comes in two main models: Voxtral Small (24 billion parameters) and Voxtral Mini (3 billion parameters), each aimed at different environments. The Small model is positioned for complex use cases and large-scale cloud deployment, while the Mini version targets embedded or resource-limited deployments. Mistral AI also offers Voxtral Mini Transcribe, an optimized version solely for voice transcription, with a better quality/price ratio than models like Whisper.
Features Beyond Transcription
Voxtral aims to be an alternative to unreliable ASR (automatic speech recognition) systems and costly closed proprietary APIs.
Designed to handle long audio contexts, it can manage up to 30 minutes of transcription or 40 minutes of comprehension, thanks to a window of 32,000 tokens.
Based on the Mistral Small 3.1 language model architecture, it can respond to oral queries, generate summaries from audio files, or transform a spoken intention into an API call or backend flow. The model supports the most widely used languages, including English, Spanish, Arabic, French, Portuguese, Hindi, German, Dutch, and Italian.
Cutting-Edge Performance
According to initial evaluations provided by Mistral, Voxtral Small surpasses the Whisper v3 reference model, as well as Gemini 2.5 Flash and GPT-4o Mini Transcribe from Open AI on several automatic transcription metrics, while displaying controlled resource consumption.
In FLEURS (below), Voxtral Small shows top performance in all tested languages, with accuracy superior to Whisper.
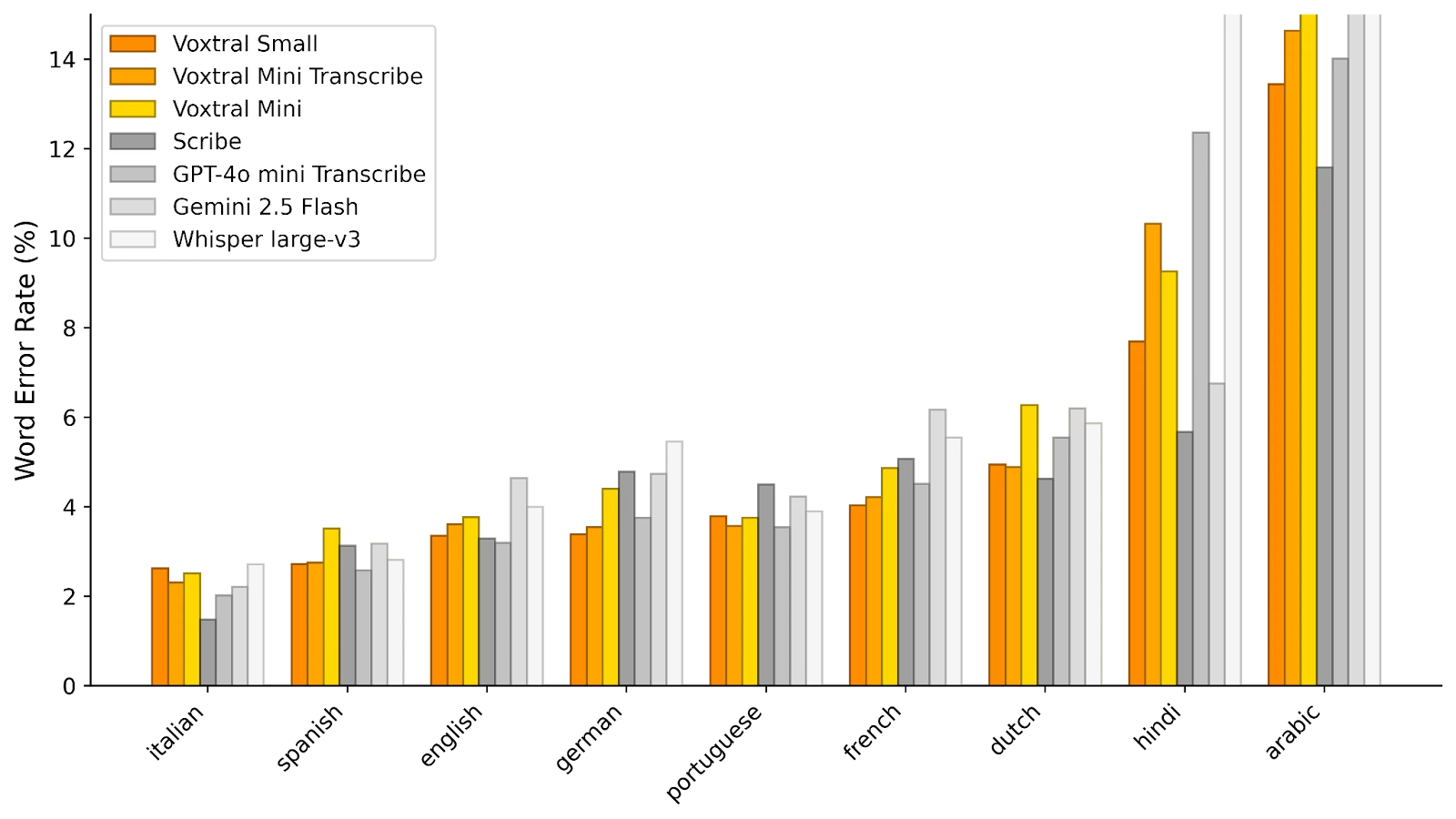
© Mistral AI
On voice translation tasks, Voxtral Small is competitive with GPT-4o Mini and Gemini.
Availability
Both models, distributed under Apache 2.0 license, are available for download on Hugging Face. Voxtral is also accessible via API starting at $0.001/minute for those wishing to integrate it into their application, which is less than half the cost of competing offers, and will soon enrich Mistral AI's conversational assistant, Le Chat.
For specific business contexts, companies can opt for private and secure deployments, particularly in legal or medical domains.
Mistral AI plans to add new features in the coming months, such as audio segmentation, diarization (identification of different speakers), or emotion detection.
An Expanding Market Dynamic
This launch comes as transcription and audio analysis solutions are in high demand, with an acceleration of use cases in customer support, interaction analysis, automated documentation, or voice assistance. Voxtral fits into a space already occupied by initiatives like Whisper (OpenAI, MIT), SeamlessM4T (Meta, non-commercial), or frameworks like NVIDIA NeMo or ESPnet.
But few of them currently offer free access, integrated semantic understanding, and the ability to trigger actions from voice, all in one solution.
Cet article publirédactionnel est publié dans le cadre d'une collaboration commerciale