
While speculations were rife about the upcoming launch of DeepSeek R2, it was ultimately an update of the R1 model that the eponymous Chinese start-up announced on May 28. Dubbed DeepSeek-R1-0528, this version strengthens R1's capabilities in key areas such as reasoning, logic, mathematics, and programming. Now, the performance of this open-source model, released under the MIT license, approaches that of flagship models like Open AI's o3 and Google's Gemini 2.5 Pro.
Significant Improvements in Handling Complex Reasoning Tasks
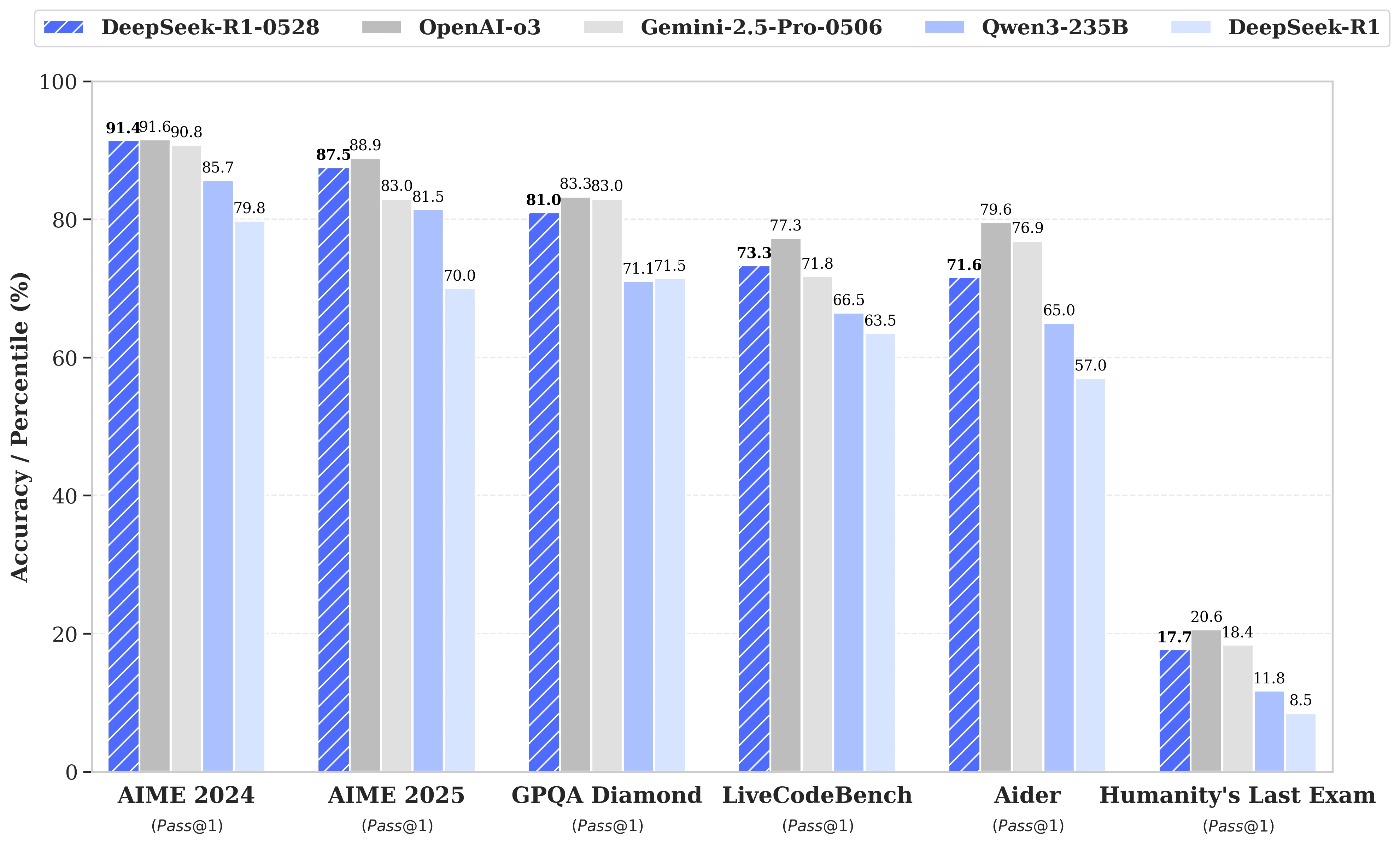
The update relies on a more efficient use of available computing resources, combined with a series of algorithmic optimizations implemented post-training. These adjustments result in increased depth of thought during reasoning: while the previous version consumed an average of 12,000 tokens per question in AIME tests, DeepSeek-R1-0528 now uses nearly 23,000, with a notable increase in accuracy, from 70% to 87.5% on the 2025 edition of the test.
- In mathematics, recorded scores reach 91.4% (AIME 2024) and 79.4% (HMMT 2025), approaching or exceeding the performance of some closed models like o3 or Gemini 2.5 Pro;
- In programming, the LiveCodeBench index progresses by nearly 10 points (from 63.5 to 73.3%), and the SWE Verified evaluation rises from 49.2% to 57.6% success;
- In general reasoning, the GPQA-Diamond test sees the model's score rise from 71.5% to 81.0%, while for the "Last Examination of Humanity" benchmark, it more than doubled, from 8.5% to 17.7%.
Reduction of Errors and Better Application Integration
Among the notable developments brought by this update, a significant reduction in the hallucination rate is observed, a critical issue for the reliability of LLMs. By reducing the frequency of factually inaccurate responses, DeepSeek-R1-0528 gains robustness, especially in contexts where precision is essential.
The update also introduces features geared towards use in structured environments, including direct JSON output generation and expanded support for function calls. These technical advances simplify the integration of the model into automated workflows, software agents, or back-end systems, without requiring heavy intermediate processing.
Increasing Focus on Distillation
In parallel, the DeepSeek team has embarked on a process of distilling chains of thought into lighter models for developers or researchers with limited hardware. DeepSeek-R1-0528, which has 685 B (billion) parameters, has thus been used to post-train Qwen3 8B Base.
The resulting model, DeepSeek-R1-0528-Qwen3-8B, manages to match much larger open-source models on certain benchmarks. With a score of 86.0% on AIME 2024, it not only surpasses Qwen3 8B by more than 10.0% but also matches the performance of Qwen3-235B-thinking.
An approach that questions the future viability of massive models, in the face of more frugal but better-trained versions to reason.
DeepSeek states:
"We believe that the chain of thought of DeepSeek-R1-0528 will have significant importance both for academic research on reasoning models and for industrial development focused on small-scale models."