On July 21st, Alibaba announced on X the release of the latest update of its LLM Qwen 3: Qwen3-235B-A22B-Instruct-2507. The open-source model, distributed under an Apache 2.0 license, boasts 235 billion parameters and positions itself as a serious competitor to DeepSeek-V3, Claude Opus 4 by Anthropic, OpenAI's GPT-4o, or Kimi 2 recently launched by the Chinese startup Moonshot, which is four times larger.
Alibaba Cloud specified in its post:
"After discussing with the community and reflecting on the matter, we have decided to abandon the hybrid thinking mode. We will now train the Instruct and Thinking models separately to achieve the best possible quality."
Qwen3-235B-A22B-Instruct-2507 is a non-thinking model, meaning it does not perform complex chain reasoning but prioritizes speed and relevance in executing instructions.
Thanks to this strategic orientation, Qwen 3 not only improves in following instructions but also shows advancements in logical reasoning, fine understanding of specialized fields, handling rare languages, as well as in mathematics, sciences, programming, and interaction with digital tools.
In open-ended tasks, involving judgment, tone, or creation, it better adjusts to user expectations, with more useful responses and a more natural generation style.
Its context window, increased to 256,000 tokens, has been multiplied by eight, allowing it to now process large documents.
An architecture oriented towards flexibility and efficiency
The model relies on a Mixture-of-Experts (MoE) architecture with 128 specialized experts, of which 8 are selected based on the query: among its 235 billion parameters, only 22 billion are thus activated per request.
It is built on 94 layers of depth, an optimized GQA (Grouped Query Attention) scheme: 64 heads for the query (Q) and 4 for keys/values.
Performance of Qwen3‑235B‑A22B‑Instruct‑2507
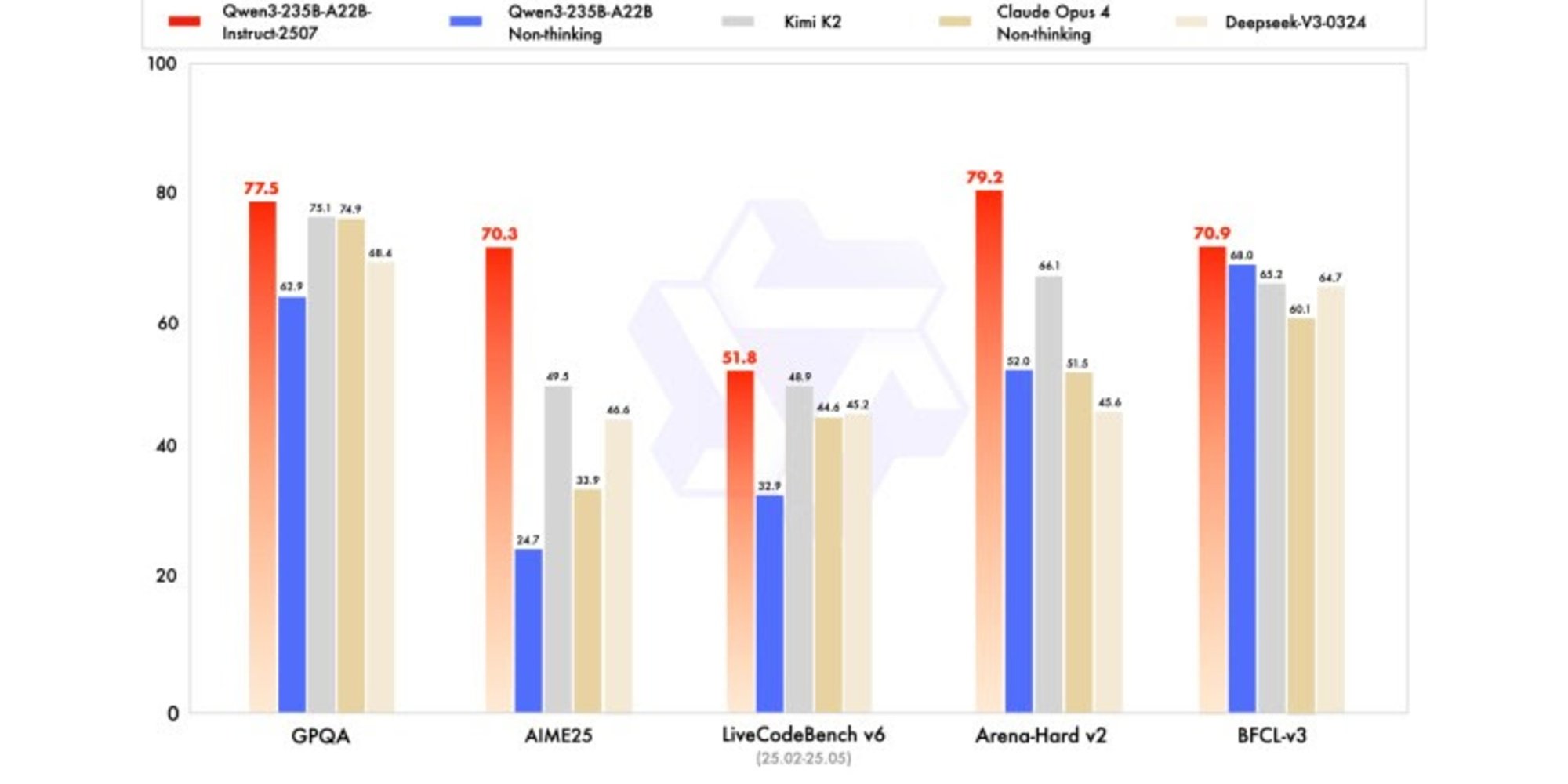
The new version shows competitive, if not superior, results to leading competitors' models, particularly in mathematics, coding, and logical reasoning.
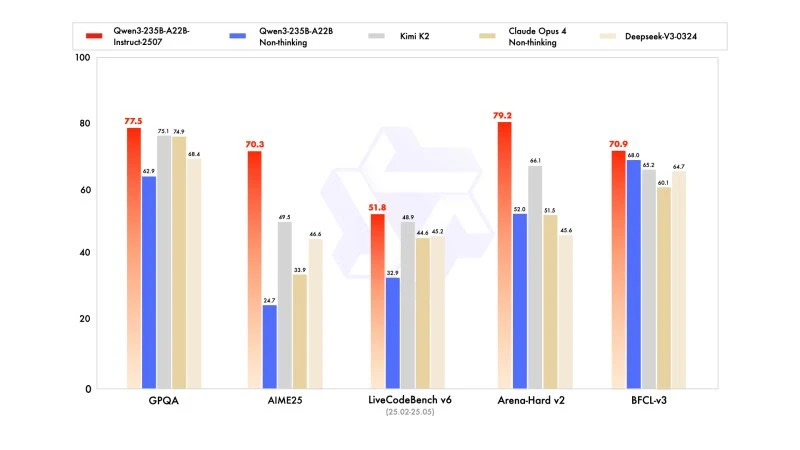
In general knowledge, it scored 83.0 on MMLU-Pro (compared to 75.2 for the previous version) and 93.1 on MMLU-Redux, approaching the level of Claude Opus 4 (94.2).
In advanced reasoning, it achieved a very high score in mathematical modeling: 70.3 on AIME (American Invitational Mathematics Examination) 2025, surpassing the scores of 46.6 by DeepSeek-V3-0324 and 26.7 by GPT-4o-0327 by OpenAI.
In coding, its score of 87.9 on MultiPL-E positions it behind Claude (88.5), but ahead of GPT-4o and DeepSeek. On LiveCodeBench v6, it reaches 51.8, marking the best performance measured on this benchmark.
FP8 quantized version: optimization without compromise
Alongside Qwen3-235B-A22B-Instruct-2507, Alibaba released its FP8 quantized version. This compressed numeric format drastically reduces memory requirements and accelerates inference, allowing the model to operate in environments where resources are limited, without causing any significant loss in performance.