DeepSeek
DeepSeek, китайський стартап, заснований у травні 2023 року в Ханчжоу, швидко зарекомендував себе як провідний гравець у сфері штучного інтелекту (ШІ) і, зокрема, у галузі великих мовних моделей (LLM). Дочірня компанія хедж-фонду High-Flyer, DeepSeek очолюється Лян Веньфенгом і має на меті конкурувати з американськими гігантами ШІ, пропонуючи інноваційні та конкурентоспроможні рішення з відкритим кодом.
Читати продовження профілю Оновлено 5 червня 2026
Сфери експертизи та основні досягнення
DeepSeek спеціалізується на розробці великих мовних моделей, здатних виконувати складні завдання завдяки розвиненим можливостям міркування. З моменту свого запуску компанія представила кілька помітних моделей, зокрема DeepSeek-V3, модель з 671 мільярдом параметрів, яка була попередньо навчена на великому наборі даних і відзначається своєю продуктивністю та значно зниженими витратами на навчання. Ця модель конкурує з найкращими американськими моделями, такими як GPT-4o або Claude 3.5 Sonnet, незважаючи на обмежені апаратні ресурси.
У січні 2025 року DeepSeek викликала сенсацію запуском DeepSeek-R1, моделі першого покоління для міркувань, яка порушила технологічну екосистему завдяки своїм вражаючим показникам і зниженим витратам на навчання. Ця модель була швидко прийнята китайською автомобільною промисловістю для застосувань у допомозі водіям та покращеній взаємодії між водіями та транспортними засобами.
Останні внески та помітні проекти
DeepSeek продовжує змагатися з технологічними гігантами, регулярно оновлюючи свої моделі. У травні 2025 року компанія запустила оновлення своєї моделі DeepSeek-R1, назване DeepSeek-R1-0528, покращуючи її можливості міркування, логіки, математики та програмування. Це оновлення дозволяє DeepSeek наблизитися до продуктивності провідних моделей OpenAI та Google, одночасно підвищуючи надійність своїх відповідей завдяки значному зниженню рівня галюцинацій.
Паралельно, DeepSeek розпочала процес дистиляції своїх моделей до легших версій, щоб зробити свої рішення доступними для ширшої аудиторії, зокрема для розробників з обмеженими апаратними ресурсами. Ця стратегія спрямована на демократизацію доступу до розвинених можливостей міркування без необхідності в дорогій інфраструктурі.
Позиція в технологічній екосистемі
DeepSeek зарекомендувала себе як серйозна альтернатива американським пропрієтарним рішенням, завдяки своєму підходу з відкритим кодом, який сприяє колаборативним інноваціям. Публікуючи свої моделі під ліцензією MIT, компанія дозволяє спільноті дослідників і розробників вільно отримувати доступ до своїх технологій, стимулюючи інновації та розвиток екосистеми ШІ з відкритим кодом.
Стартап також користується підтримкою китайського уряду, який бачить у ньому ключовий вектор для досягнення технологічної самодостатності на тлі американських обмежень на експорт стратегічних компонентів. DeepSeek вписується в національну стратегію Китаю, спрямовану на те, щоб стати світовим лідером у сфері ШІ до 2030 року.
Останні розробки та новини
DeepSeek нещодавно опинилася в центрі уваги через тимчасове призупинення роботи свого чат-бота в Південній Кореї через занепокоєння, пов'язані з конфіденційністю даних. Хоча це підкреслило певні регуляторні виклики, це не зупинило ентузіазм навколо її технологій, зокрема в Китаї, де модель DeepSeek-R1 була масово прийнята в ключових секторах, таких як правосуддя, кібербезпека та державне управління.
Тим часом, як зростають чутки про неминучий запуск DeepSeek-R2, компанія, здається, добре позиціонована для продовження виклику американським гігантам і для того, щоб грати центральну роль у розвитку ШІ на глобальному рівні. Ця наступна модель має запропонувати розширену багатомовну підтримку та мультимодальні можливості, відкриваючи шлях до нових застосувань у створенні контенту та аналізі даних.
На завершення, DeepSeek вирізняється своєю здатністю швидко інновувати та пропонувати конкурентоспроможні рішення на ринку, де домінують технологічні гіганти, тим самим зміцнюючи позицію Китаю в глобальній гонці за штучним інтелектом.
Пов'язані статті
12 загалом
Той самий модельний фундамент, різні запобіжники: що показав запуск Claude Fable 5 і Mythos 5

За допомогою LARA регуляторний ризик LLM стає аудиторським доказом для DPO
Перспективна альтернатива Chain-Of-Thought: Sapient робить ставку на ієрархічну архітектуру
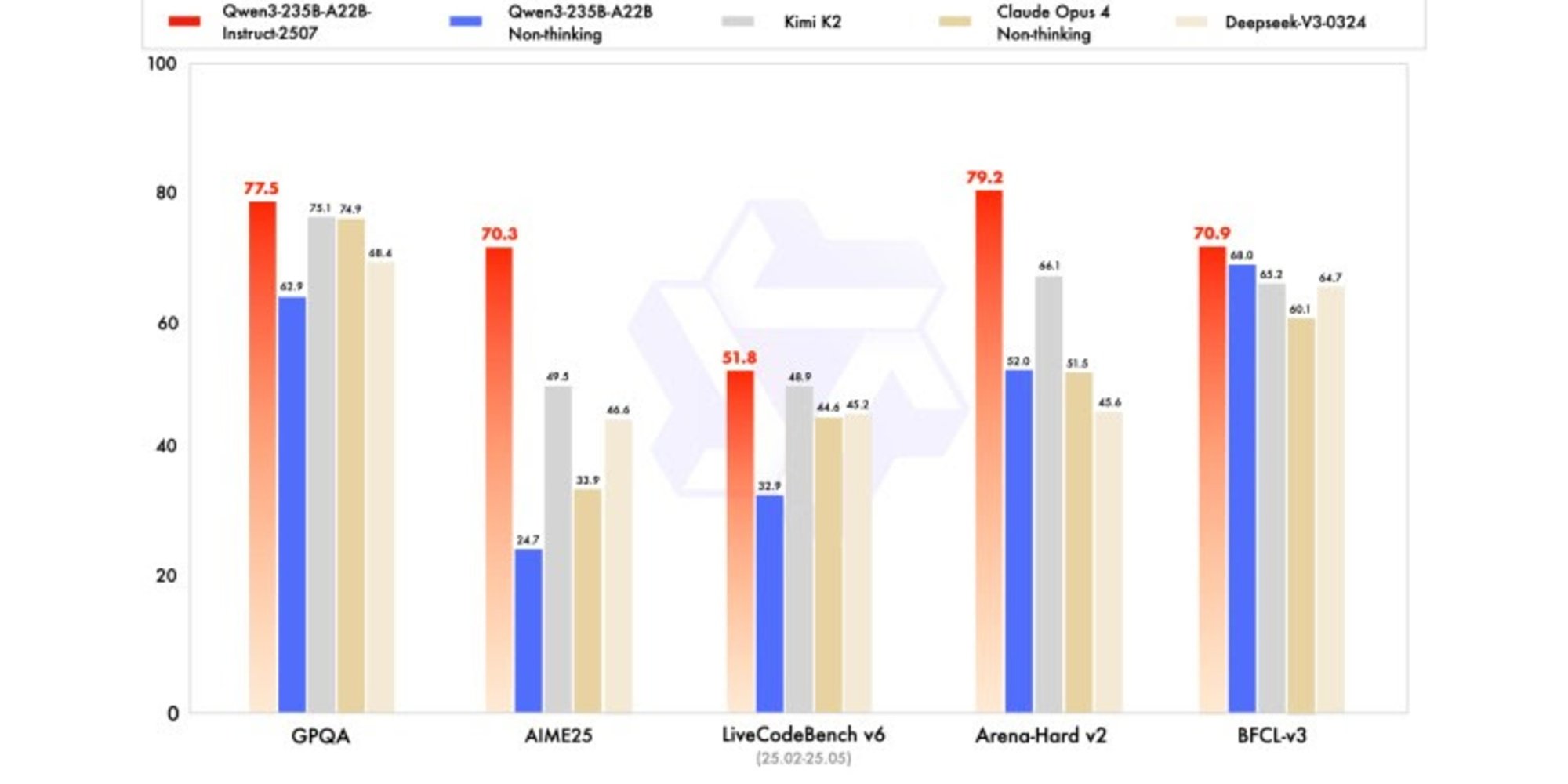
Alibaba запускає Qwen3-235B-A22B-Instruct-2507 та відмовляється від гібридного мислення
Mistral AI кидає виклик DeepSeek з Magistral, своєю першою моделлю розширеного міркування

DeepSeek-R1-0528: китайський стартап продовжує змагатися з американськими гігантами, оновлюючи свою флагманську модель

Meta AI: чи дійсно розмовний асистент поглинає дані?

L'IA під ключ: OVHcloud запускає AI Endpoints, свою безсерверну платформу для open source штучного інтелекту

Від залежності до самодостатності: амбіції Китаю у сфері штучного інтелекту

DeepSeek, тимчасово призупинений у Південній Кореї, справді передавав персональні дані без згоди

Cohere представляє Command A, канадську альтернативу американським і китайським корпоративним AI моделям
